DeepSets: 「集合」を学習するニューラルネットワーク
はじめに
機械学習モデルの入力は配列であることが多いです。通常、その配列の順序には意味があり、順序を並び替えるとデータの意味が変わってしまいます。しかし、配列の順序を並び替えてもデータの意味が変わらない「集合」と呼ばれるタイプのデータが存在しており、現実のデータの重要な一部分を占めています。集合データを学習するためには通常の機械学習モデルでは適さない場合が多く、機械学習モデルとして集合データの性質を正しく反映させたものでなければいけません。
本記事では、そういった集合データのための機械学習モデルである DeepSets について紹介します。まずは論文の意義をわかりやすくするために配列の順序に意味がある場合とない場合とについて解説し、それから論文の内容を見ていきます。
配列の順序に意味がある場合
まずは、配列の順序に意味がある場合を考えてみましょう。例えば、ある会社の将来の株価を予測したいとして、その入力特徴量を以下であるとします:
・現在の株価
・現在の売上高
・現在の利益
・現在の資本金
この場合、入力は配列の形で、例えば
[現在の株価 [円], 現在の売上高 [億円], 現在の利益 [億円], 現在の資本金 [億円]]
のような形で書けます。具体的な値として、
[3000, 100, 10, 30]
などが考えられますね。ここで、例えば 2 番め(ここでははじめの要素を 1 番目数えます)の要素と 3 番めの要素を入れ換えて
[3000, 10, 100, 30]
のようなデータを作ったとしたらどうでしょうか。これは、もとのデータとはまったく違う状態を表していることがわかると思います。前者では売上 100 億円・利益 10 億円の会社であるのに対して、後者では売上 10 億円・利益 100 億円というちょっと考えにくい状況になっています。つまり、今考えているデータでは 配列の順序に意味がある と言えます。
こういった例は何も特別なものではなく、例えば画像データなども順序に意味があります(図 1)。このようなデータを タプル (tuple)と呼び、 $(x_1, x_2, \dots)$ のように書き表します。
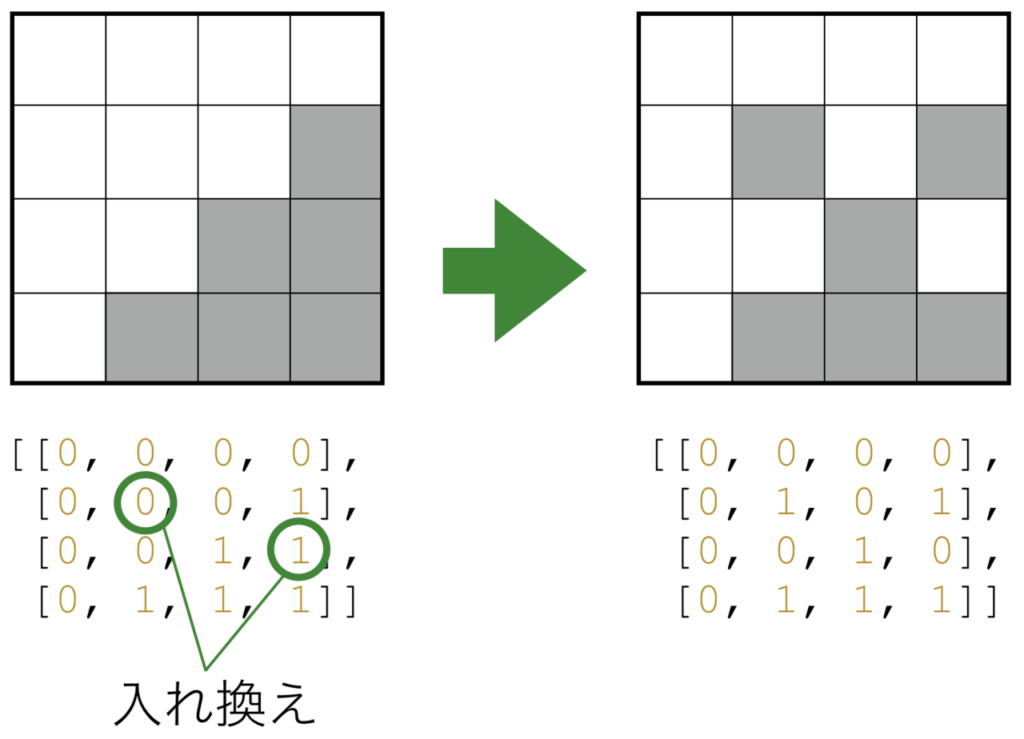
図 1. 画像データに対して配列の要素の入れ替えを行った例。画像として別のものになっている。
配列の順序に意味がない場合
次に、配列の順序に意味がない場合を考えてみます。例えば、ある会社の社員それぞれの将来の給与を予測したいとして、その入力特徴量を以下であるとします:
・社員全員の給与
この場合、入力は配列の形で、例えば
[社員の給与_1 [万円], 社員の給与_2 [万円], 社員の給与_3 [万円], ...]
のような形で書けます。具体的な値として、
[600, 800, 810, 1000]
などが考えられますね。ここで、例えば 1 番めの要素と 3 番めの要素を入れ換えて
[810, 800, 600, 1000]
のようなデータを作ったとしたらどうでしょうか。この場合でも、データとしては同じ情報を表していると考えられます。例えば、給与のヒストグラムを書いてみればこのふたつが同じものであることが視覚的にわかると思います(図 2)。つまり、今考えているデータでは 配列の順序に意味がない と言えます。
図 1. 画像データに対して配列の要素の入れ替えを行った例。画像として別のものになっている
こういった例も実は考えて見るといろいろあります。画像に付与されているタグ(下図 3)や、点の集まりで形状を表現する点群(下図 4)などは、順序に意味がない例と言えます。このようなデータを 集合 (set)と呼び、 $\{x_1, x_2, \dots \}$ のように書き表します。

図 3. 画像のタグに対して配列の要素の入れ替えを行った例
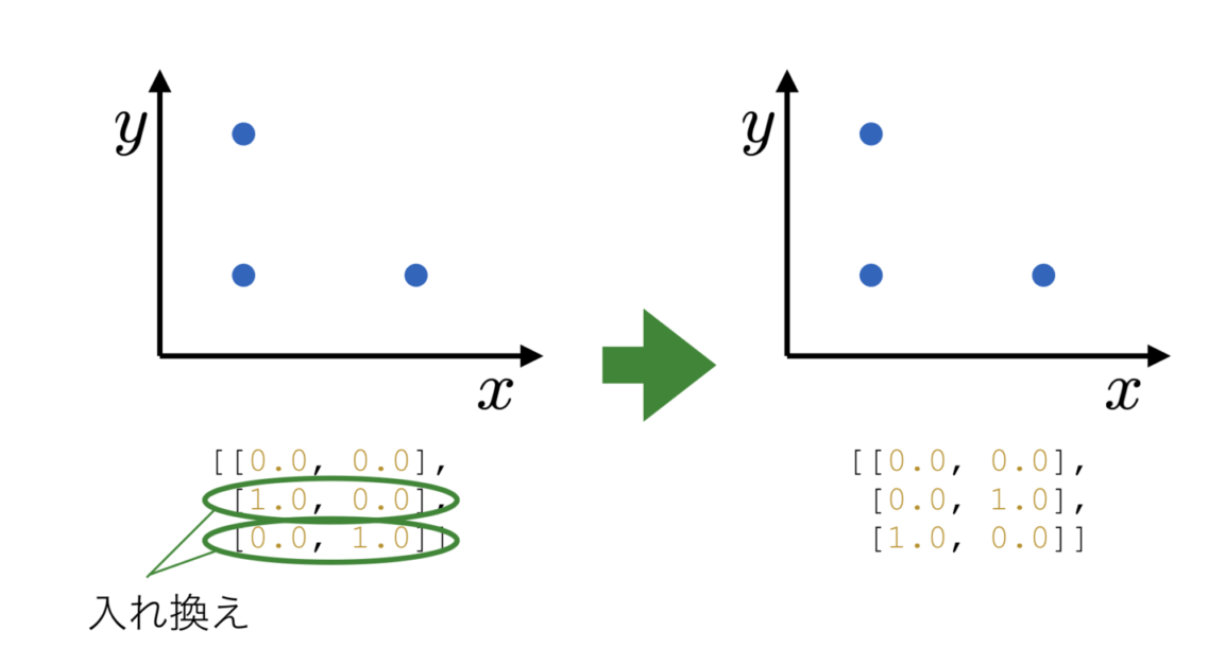
図 4. 点群データに対して配列の要素の入れ替えを行った例
集合データの難しさ
上記のような集合データの学習には、集合データ独自の難しさがあります。通常の MLP (Multilayer Perceptron) や CNN (Convolutional Neural Network) などの機械学習モデルでは集合データには対応しておらず、配列の順序を入れ換えてしまったら別のデータとみなしてしまいます。そうすると、配列の順序を入れ換えたものが同じであるという事実も含めて学習せねばならず、集合データに対して効率的な学習を行うことができなくなってしまいます。配列の長さが 3 程度であればすべての組合せ(6 通り)を網羅することは比較的簡単ですが、配列の長さが 100 ほどにもなると組合わせの数は約 $10^{158}$ 通りにもなります。これらの組合せの学習データを網羅的に集め、なおかつそれらが同一のものであることを学習することは非常に難しくなります。
他にも、順序の入れ換えを考慮しなくて済むように前処理の段階でデータをソートすることなども考えられますが、多次元配列のデータに対してはノイズに対して堅牢なソートが存在しないことが知られています。機械学習タスクのほとんどは高次元のデータを扱うことになるため、こちらもあまり効果的でないことがほとんどです。
そこで、集合データをうまくハンドリングできるような機械学習モデルが必要となるのです。
DeepSets
ではいよいよ本題に入ります。上記のような集合データに対して、それをうまくハンドリングするためにはどのようにすればいいのでしょうか?
続きを読むには
(5531文字画像5枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






