【Materials Informatics】物性値のデータ不足に対応したCGCNN-転移学習モデル
3つの要点
✔️ Crystal Graph Convolutional neural network (CGCNN)を用いた転移学習(TL-CGCNN)を提案
✔️ 結晶グラフ(Crystal Graph)記述子では、物質の結晶構造のみを説明変数とする
✔️ 取得しやすい物性値のビッグデータで事前学習し、取得しにくい別の物性値の高精度予測が可能
Transfer learning for materials informatics using crystal graph convolutional neural network
written by Joohwi Lee, Ryoji Asahi
(Submitted on 20 Jul 2020 (v1), last revised 29 Jan 2021 (this version, v4))
Comments: Published in Comp. Mater. Sci
Subjects: Materials Science (cond-mat.mtrl-sci); Computational Physics (physics.comp-ph)
code:
本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
データ量不足による予測性能の低下問題にどう対処するか…
コンピュータービジョンや自然言語処理などの分野とは異なり、MI(マテリアルズ・インフォマティクス)の分野では蓄積されたデータ数が少ない傾向にあり、機械学習を行うと十分な予測精度が出ないという問題があります。これは、実験で得られるデータ量はたかが知れており、計算科学を用いたシミュレーションでも、計算するのに膨大なコストが必要になる場合が多くあるためです。
解決策の一つとして、近年MIの分野で注目されているのが、転移学習です。ビッグデータが存在する物性値で事前学習したモデルを、また別の物性値の予測に使用するというものです。
記述子選択
材料探索におけるもう一つの重要なチャレンジは、多様な目的変数(物性値)を予測できる汎用性の高い物質の記述子を発展させることです。物性値は、物質の結晶構造や構成元素などに強く依存するため、それら構造特性をベースにおいた記述子が多く開発されています。具体例として、Coulom matrixやSOAP(Smooth Overlap of Atomic Positions)、R3DVS (Reciprocal 3D voxel space)などがあります。
近年、CGCNN(Crystal Graph Convolutional neural network)が、XieとGrossmanによって提案されました。CGCNNを用いて分類および予測タスクを行う場合、必要な情報は物質の結晶構造のみです。結晶構造から結晶グラフ構造を作り、それをもとに深層ニューラルネットワークで目的変数(物性値)の予測を行います。
ある記述子を用いて転移学習を行う場合、重要なのは、事前学習に使用した物性値と相関性の低い物性値の予測を高精度で行えるかどうかです。記述子が物質構造の特徴を根底からうまく捉えられていないと、様々な物性に対応できる転移学習は行えません。
本研究では、CGCNNと転移学習(TL)を組み合わせたモデルの性能を調査しました。
モデル構築
CGCNN
CGCNNは、結晶構造からグラフ構造をつくる部分と、埋め込み層、畳み込み層、プーリング層、全結合層からなる深層CNNの部分からなります。 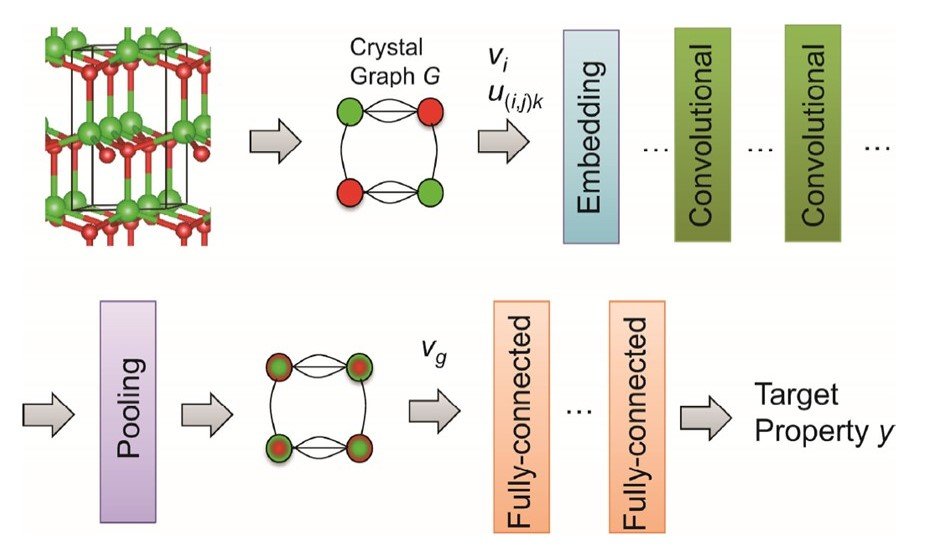
結晶グラフGは、原子のグループや原子番号、原子間の距離などを2進数で表現する離散的な記述子として表現されます。ノードが原子を、エッジが化学結合を表し、結晶構造中の原子のセット、間接的な結合、原子特性、結合特性で構成されます。そして、この離散的な記述子は、埋め込み層で連続的な記述子に変換されます。その後、その連続的な記述子が畳み込み層にインプットされます。
i+1番目の畳み込み層において、原子特性ベクトル viは以下のように表されます。
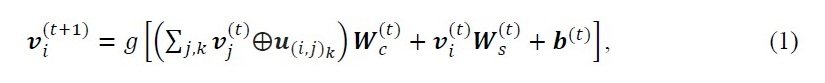
u(i,j)k : 結合特性ベクトル(i番目の原子とj番目の原子の間のk番目の結合)、 Wc : 畳み込みの重み行列、 Ws : 自己の重み行列, b : t番目の層のバイアス、g : ソフトプラス関数、vとuの間の記号 : vとuの連結
しかし、上記の式では、結晶構造中の隣接するすべての原子の原子ベクトル・結合ベクトルは重み行列を共有するため、個々の原子間の相互作用を認識しにくいという問題点があります。そこで、標準的なEdge-gatingテクニックを適用します。そのため、隣接原子間の特徴をまとめたベクトル z(i,j)k を用いて、以下のように原子特性ベクトルviを表現します。

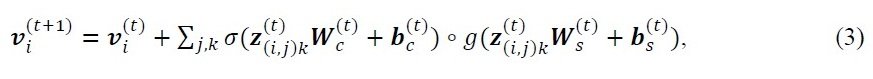
σ: シグモイド関数、○ : Σの要素ごとの乗算
XieとGrossmanはこの手法を用いることで、より予測性能が向上すると報告しています。その後、viはプーリング層にインプットされます。今回は平均プーリングを使用し、結晶特徴ベクトルvgを得ます。

Nは結晶グラフ中の原子数
最終的に、vgは全結合層にインプットされます。ここで、vgから非線形関数を用いて目的変数(物性値)を算出するように学習させます。
TL-CGCNN
本研究では、事前学習によって最適化したパラメータを組み込む方法として、ファインチューニングを採用しました。
ちなみに、事前学習用タスクと目的タスクで目的変数(物性値)のスケールをそろえるために、tanh標準化を実施しました。
データセットと学習について
物質の結晶構造と、対応するバンドギャップエネルギー(Eg)や生成エネルギー(ΔEf)などの物性値は、第一原理計算データベース、Materials Project Database(MPD)から用意しました。TL-CGCNNモデルは、10k、54k、113k個の生成エネルギー(ΔEf)のデータで事前学習を行いました。
(詳細な学習方法について興味のある方は、論文を参照していただければと思います。)
結果・考察
CGCNNとTL-CGCNNの比較
以下では、モデルを以下のように示します。
Ex.) 500-NM-Eg : 目的変数がバンドギャップエネルギー(Eg), 学習用データ数が500, 非金属性の物質(NM)のデータのみ使用
扱うほとんどの物質はバルク(ナノ粒子や薄膜などではない)の無機物です。
以下の図は、データベースの118286個全ての物質の生成エネルギー(ΔEf)とバンドギャップ(Eg)の間の散布図を示します。直線回帰での相関係数(rp)は-0.49であり、物性値間に強い相関はないことが分かります。
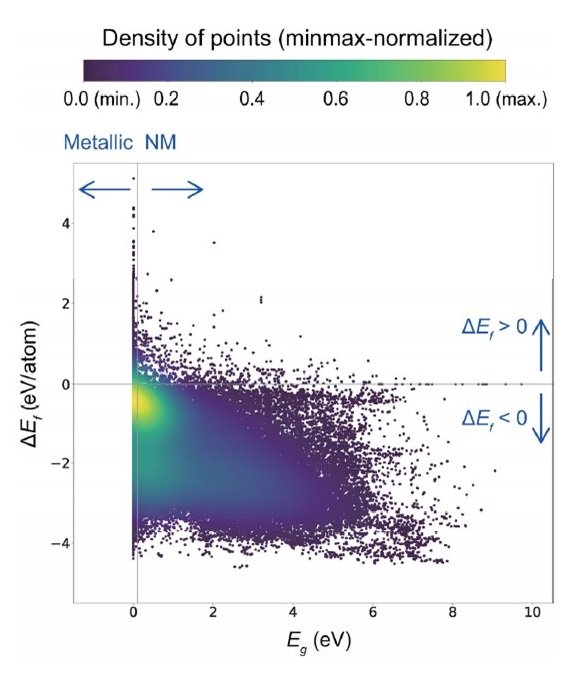
カラースケールはGaussianカーネル密度推定によって得た相対密度を表す。
以下の図は、CGCNNでEgとΔEfのそれぞれの予測タスクを行った場合の、データセットサイズと予測誤差の相関性を示します。
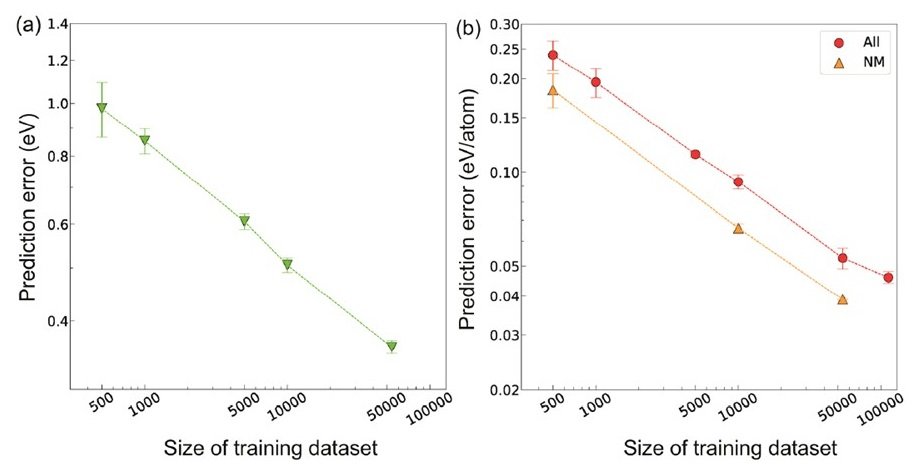
縦軸と横軸はlog10軸になっています。
データセットサイズが大きくなるほど、顕著に予測誤差は減少しました。データ数最大での予測誤差の値は、実験と合わせて行った第一原理計算(DFT計算)で算出される値の誤差に匹敵することが分かりました。また、無機物の中でも、金属性と非金属性の物質では構成元素と結合の種類が異なるため、結晶グラフも大きく異なると考えられます。そこで、それぞれ分けて、非金属性の物質のみでモデル構築と予測を行ったところ、データサイズが同じの条件で、分けた方が顕著に予測誤差が減少しました。
続いて、データ数が不十分な場合の予測タスクを行いました。以下の図は、CGCNNとTL-CGCNNによる非金属性の物質のバンドギャップ(Eg)の予測性能の比較です。
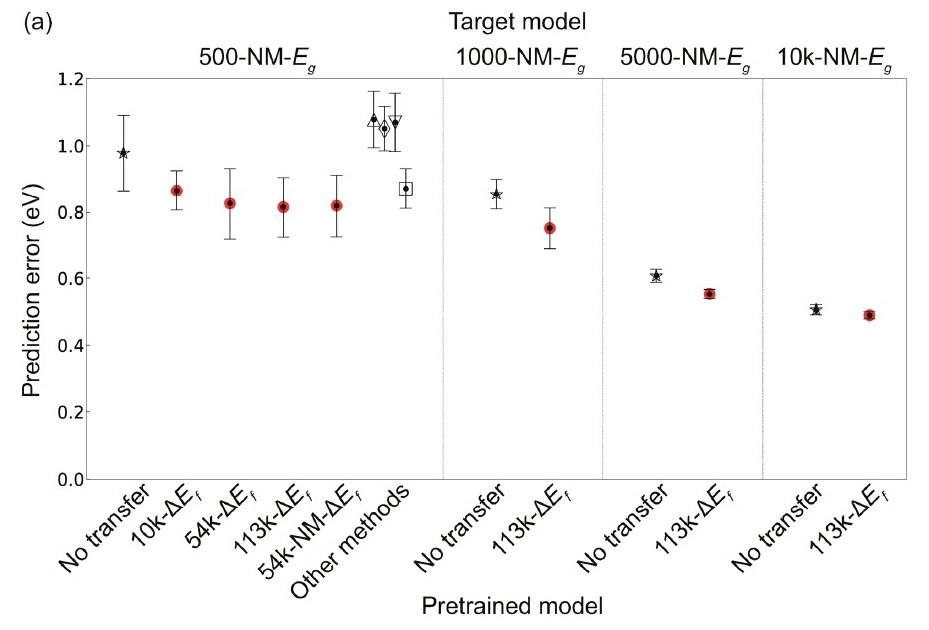
TL-CGCNNではそれぞれのサイズのデータで事前学習を行っている。△: PLS、▽: SVR、◇: LASSO、▢: RF
CGCNNのみの場合に比べ、転移学習(TL)を行った場合の方が顕著に予測誤差は低下しました。また、生成エネルギー(ΔEf)での事前学習のデータ量を増やしていくほど、Egの予測誤差は低下しました。500-NM-Egで、有意水準1%で対応のあるt-検定を実施した結果、CGCNNと113k個のΔEfのデータで事前学習したTL-CGCNN(113k-ΔEf TL-CGCNN)の間では、p = 6.9×10-5であり、TL-CGCNNによる明確な予測性能向上が確認されました。
以下の図(a)は、CGCNNとTL-CGCNNによる非金属性の物質のΔEfの予測性能の比較を行った結果です。
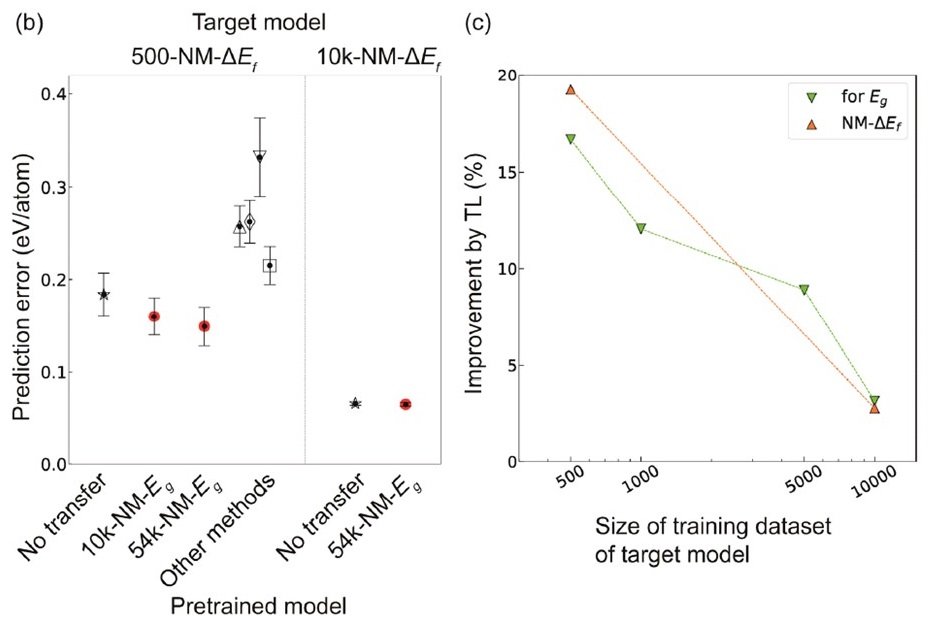
TL-CGCNNではそれぞれのサイズのデータで事前学習を行っている。△: PLS、▽: SVR、◇: LASSO、▢: RF 、
TL-CGCNNでは、非金属性の物質データのみで事前学習を行っています。こちらでも、TL-CGCNNの使用により明確な予測誤差の低下が確認できました。
ちなみに、非金属性の物質データのみで事前学習を行い、金属性の物質を含むデータのΔEfの予測を行ったところ、有意差が見られませんでした。やはり、金属性と非金属性の物質群では構成元素や結合状態が大きく異なり、結晶グラフの構成も大きく異なることが影響していると考えられます。つまり、結晶グラフの構成が大きく異なると予想される物質の性質種別は、モデルを別にした方が良い可能性があります。
上の右図(c)は、ターゲットモデルの学習用データ量と、TLを用いた場合の予測精度の向上率の関係性を表します。ターゲットモデルのデータ量が少ないほど、TLの威力が顕著に発揮されています。
収集しにくい物性データ予測へのTL-CGCNNの活用
体積膨張率(KVRH)や誘電率(εr)、準粒子のバンドギャップ(GW-Eg)などの物性値は、計算科学で求めるコストが高価で、Egなどのデータに比べてデータ蓄積量がとても少ないです。CGCNNとTL-CGCNN(上記の物性値と相関性の低いΔEfとEgで事前学習)でこれらの物性値の予測タスクを行い、得られた予測誤差の比較を以下に示します。
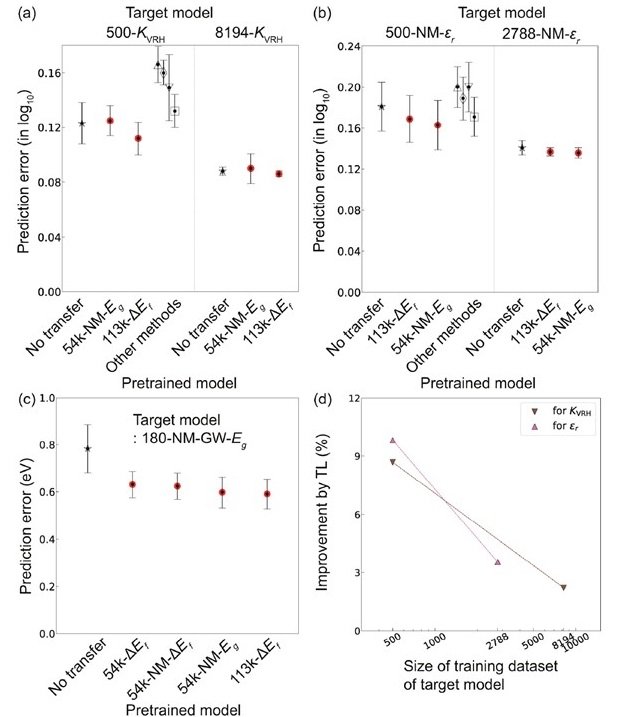
(a)体積膨張率(KVRH)、(b)誘電率(εr)、(c)準粒子のバンドギャップ(GW-Eg)の予測誤差
すべての物性値でTL-CGCNNでは性能改善が見られました。特に、非金属性の物質のGW-Egの予測では、TLの併用により最大で24.5%の予測精度向上が確認されました。(上記の図を見ると、一見有意差がないように見えますが、縦軸がlog10スケールになっているため、実際の差は見た目よりもずっと大きいです。) また、やはりターゲットモデルの学習用データ量が少ないほど、TLによる改善率の高さが顕わになりました。
ちなみに、上記の試験結果にはよく知られたPLSやSVR、RFなどのモデルで同様のタスクを行った場合の結果も示されています。CGCNNの性能と比較すると、データ数500の少量でもRFのみは、特定の物性値においてCGCNNを凌駕する性能を示しました。しかし、TL-CGCNNには到底及ばない結果となりました。RFのような広く使用されている回帰モデルは、今回の結果のように、目的変数となる物性値と強い相関を持つ記述子と組み合わせた場合は、優れた性能を示します。しかし、それぞれの物性値に対して、それぞれ有効な記述子をその都度選択するのは手間がかかり、容易ではありません。
まとめ
結晶グラフ記述子と転移学習を組み合わせたTL-CGCNNは、少量のデータしか得られないときに、強力で柔軟性の高い予測モデルであるといえます。結晶グラフ記述子は、ビッグデータで事前学習を行うことで、元素や結晶構造の特徴を効果的につかむことができるため、転移学習において優れた性能を発揮します。以上の特徴から、TL-CGCNNモデルはデータを蓄積するのが難しい物性値のデータ収集にも、役立てられると期待されます。



この記事に関するカテゴリー
.jpg)




