生成されたテキストの人間っぽさや面白さを高精度にモデル化:MAUVE
3つの要点
✔️ 生成文の人間らしさを自動的に評価する方法を開発
✔️ KL-divergenceを使ってType-IおよびType-IIエラーをモデル化
✔️ 既存の手法よりも人手評価との相関がかなり高く、最高精度を達成
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers
written by Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, Zaid Harchaoui
(Submitted on 2 Feb 2021 (v1), last revised 23 Nov 2021 (this version, v3))
Comments: NeurIPS 2021
Subjects: Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
オープンエンド言語生成と呼ばれるタスクがあります。有名なものだと、雑談対話やストーリー生成などです。みなさんはどのようにそれらのタスクを自動評価するかご存知でしょうか?
機械翻訳や要約などは明確な正解が用意されているため、正解との距離をBLEUやROUGEなどを使ってなんとか測ろうとします。しかし、オープンエンド言語生成では明確な正解がありません。そのため、人間らしくて興味深い文章かどうかを言語モデルなどを用いて間接的に推定します。本論文中でもベースラインとしていくつか紹介されており、以下のようなメトリックが存在します。
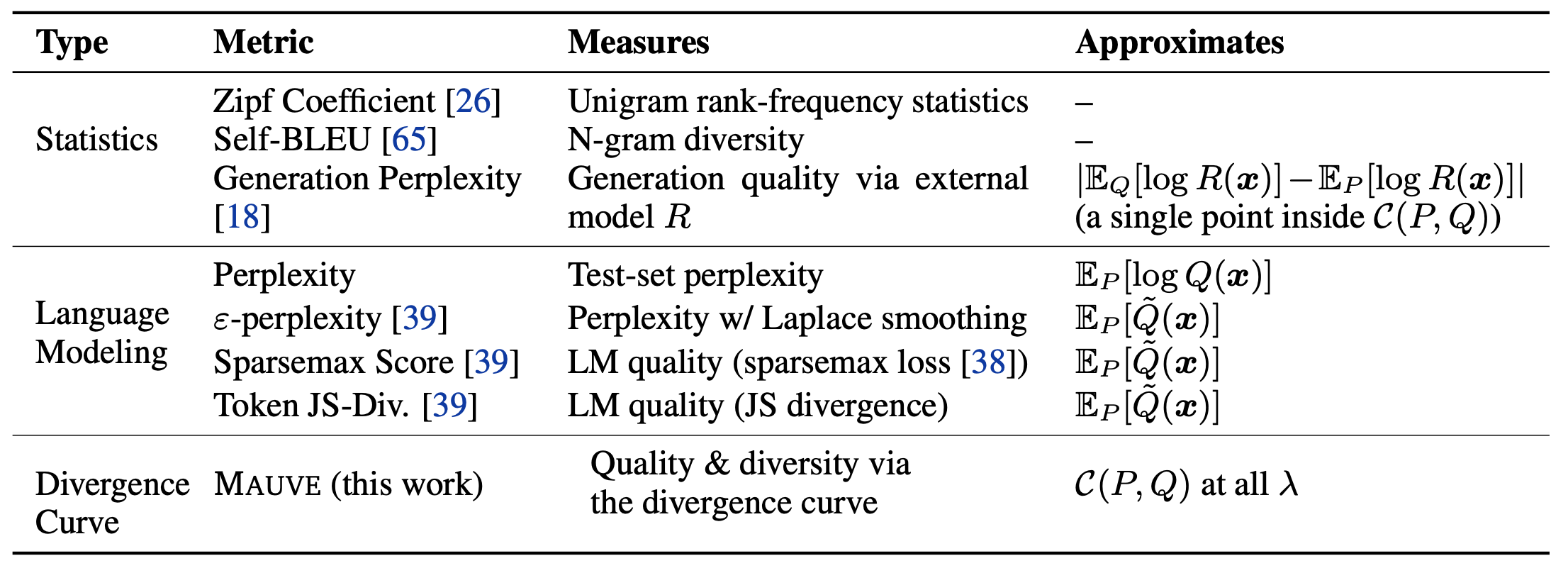
表中で最も有名なものはパープレキシティでしょうか。生成された文章の尤度を評価するものです。Self-BLEUなどは生成文間のBLEUを比較することで多様性を評価するものになります。表中の最下部にある提案手法のMAUVEは、KL-divergenceを使うことでそれら先行研究と比べて非常に高い人手評価との相関を叩き出しました。
本記事では、NeurIPSのOutstanding paperにも選ばれたMAUVEの概要を紹介していきます。
MAUVE
Type-IエラーとType-IIエラーのモデル化
モデルのエラーの分類としてType-IエラーとType-IIエラーという概念がよく使用されます。それぞれ、Flase positiveとFalse negativeとも言われ、言語生成に当てはめると、
- Type-Iエラー:人間が書きそうもない文章を生成してしまう(repetitionが代表的な例)
- Type-IIエラー:人間が書きそうな文章を生成できない
となります。図で示すと、以下のようになります(Qが生成テキスト、PがHumanテキスト)。
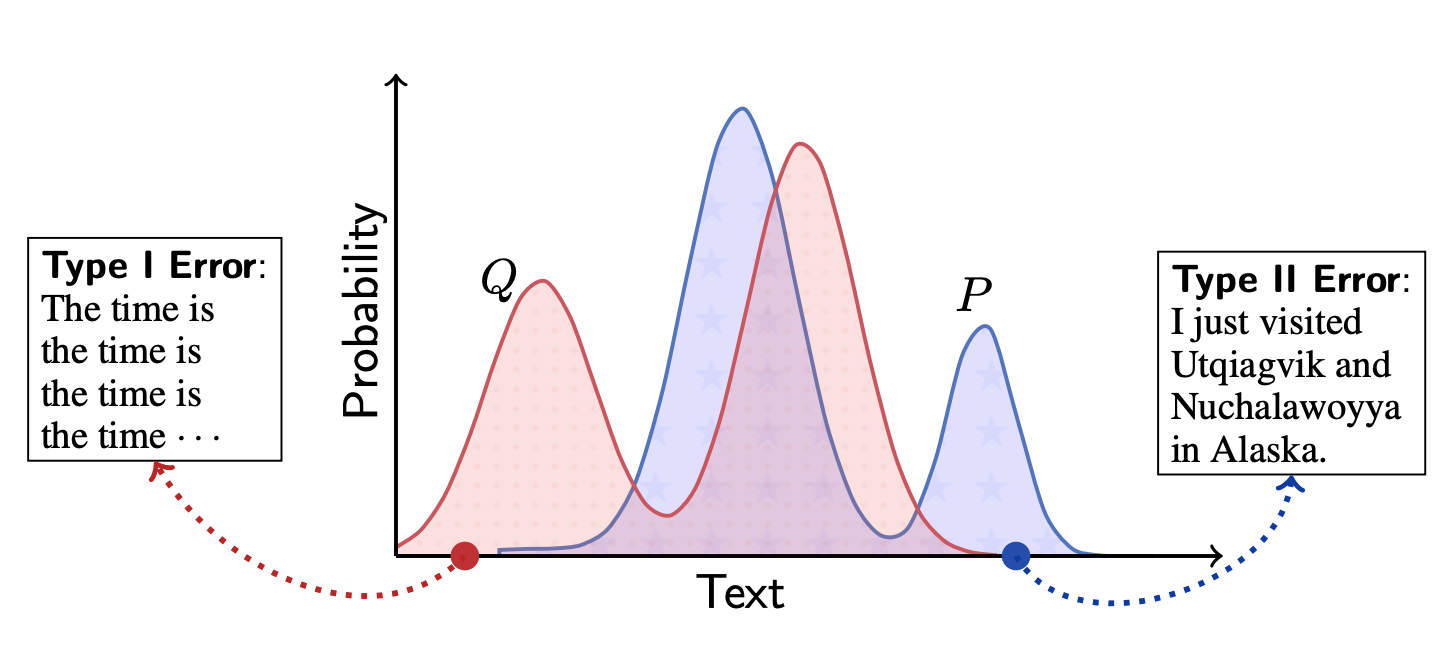
図ではモデルとHumanテキストの生起確率をプロットして、確率分布のように描かれています。これをそのままKullback-Leibler (KL) divergenceでモデル化したのが本研究です。KL-divergenceは確率分布間のギャップを測るメトリックで、大きいほど2分布が異なることを示します。特性としては、非負で、どちらの確率分布をを基準に取るかで値が異なります。
MAUVEではKL-divergenceの導入にあたって大きく2つの工夫をしています。それらを順に説明していきます。
工夫1. テキストベクトルを用いて確率分布を作る
NLPでKL-divergenceを用いるときはVocabularyに対して確率分布を作ることが多いです。しかし、本研究ではテキストのベクトルを事前学習モデル(GPT-2)で生成し、クラスタリングを行なって、それを元に確率分布を作るということを行なっています。これにより、Vocabulary単位でKL-divergenceを測るよりもより文脈的な意味を取り入れることに成功し、同時に計算量も削減しています。具体的な手順は以下の通りです。
- 生成テキスト、Humanテキストのテキストをそれぞれサンプリングする(論文では5000個)
- GPT-2を用いて、それぞれのテキストをベクトルにする
- テキストベクトルを混ぜ、k-meansでクラスタリングする(論文ではクラスタ数500)
- 生成テキスト、Humanテキストそれぞれでクラスタの確率分布を作る
なお、論文中ではサンプリング数やクラスタ数、クラスタリングのアルゴリズムなど細かく実験していますので、もし興味があればAppendixをご参照ください。
工夫2. 混合分布とのKL-divergenceを測る
KL-divergenceの重要な性質として分布が異なりすぎると値が発散してしまうことがあります。なので、そのままでは評価指標には向きません。本研究では生成とHumanテキストの2分布間で直接KL-divergenceを測るのではなく、2分布の混合分布と2分布それぞれの間でKL-divergenceを測るという工夫をしています。HumanテキストのKL-divergenceは以下の式で計算されます。
$\mathrm{KL}\left(P \mid R_{\lambda}\right)=\sum_{\boldsymbol{x}} P(\boldsymbol{x}) \log \frac{P(\boldsymbol{x})}{R_{\lambda}(\boldsymbol{x})}$
ここで、$R_\lambda$が生成テキストとHumanテキストの混合分布です(通常のKL-divergenceであれば$Q(\boldsymbol{x})$)。 $R_\lambda$は以下のように生成されます。
$R_{\lambda}=\lambda P+(1-\lambda) Q$
$\lambda$はハイパーパラメータで[0,1]の値域を取ります。つまり、PとQをどの程度の割合で混合するかを操作しています。MAUVEはこの $\lambda$を[0,1]で動かすことによって得られるdivergenceカーブを利用します。divergenceカーブの計算式は以下の通りです。
$\mathcal{C}(P, Q)=\left\{\left(\exp \left(-c \mathrm{KL}\left(Q \mid R_{\lambda}\right)\right), \exp \left(-c \mathrm{KL}\left(P \mid R_{\lambda}\right)\right)\right): R_{\lambda}=\lambda P+(1-\lambda) Q, \lambda \in(0,1)\right\}$
ここで、cはc>0のスケーリング用のハイパーパラメータで、expの処理はKL-divergenceの値域を[0,1]にするために行われています。生成テキスト、Humanテキストからみた混合分布へのKL-divergenceの図は以下のようになります。
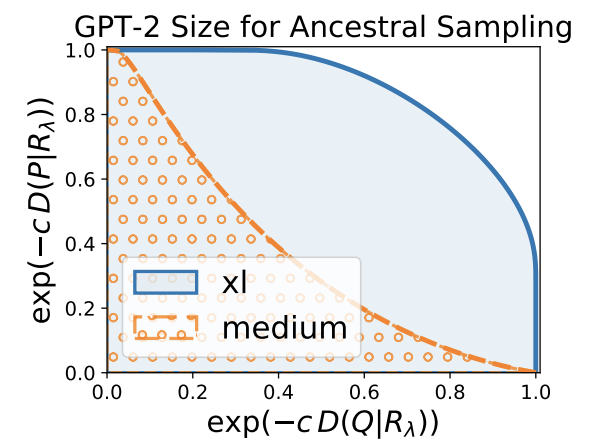
図の見方が若干複雑ですが、生成テキストから見た混合分布へのギャップは横軸が$\lambda$の値で、縦軸が$\exp \left(-c KL\left(Q \mid R_{\lambda}\right)\right)$の値を示しています。一方、Humanテキストから見た混合分布へのギャップに着目すると、縦軸が$\lambda$の値で、横軸が$\exp \left(-c KL\left(P \mid R_{\lambda}\right)\right)$の値を示します。
このdivergenceカーブの下の面積がMAUVEのスコアになります。上図では、GPT-2のxlとmediumでテキストを生成した際のスコアを比べていて、xlの方がmediumよりもスコアが大きいことから、empiricalにMAUVEの正当性を主張しています。
実験
実験のセクションでは、いくつかのempiricalな評価に加えて、人手評価を行なっています。
- タスク:
タスクはweb text、news、storiesのドメインにおけるテキスト補完タスクです。先頭の単語列が与えられて、残りの単語列を予測するタスクになります。タスクの都合上、元の単語列をHumanテキストとしますが、本来明確な正解は存在しないタスクです。 - デコーディングアルゴリズム(参考):3つのデコーディングアルゴリズムを考えます。一般的にモデルの精度はGreedy decoding<Ancestral sampling<Nucleus samplingの順になります。
- Greedy decoding
各デコーディングステップにおいて、常に生起確率の一番高い単語を選ぶ。 - Ancestral sampling
言語モデルの確率分布に則って、次の単語を確率的に選択。 - Nucleus sampling
上位p単語以外を切り捨て、残った単語で最スケーリングした分布に従い次の単語を選択。
- Greedy decoding
文長が長いほど精度が低下するか
モデルが生成するテキストは当然ですが、長ければ長いほど精度が悪化(=Humanテキストから乖離)します。この現象を先行研究を含めた自動評価指標が捉えられるかを実験します。
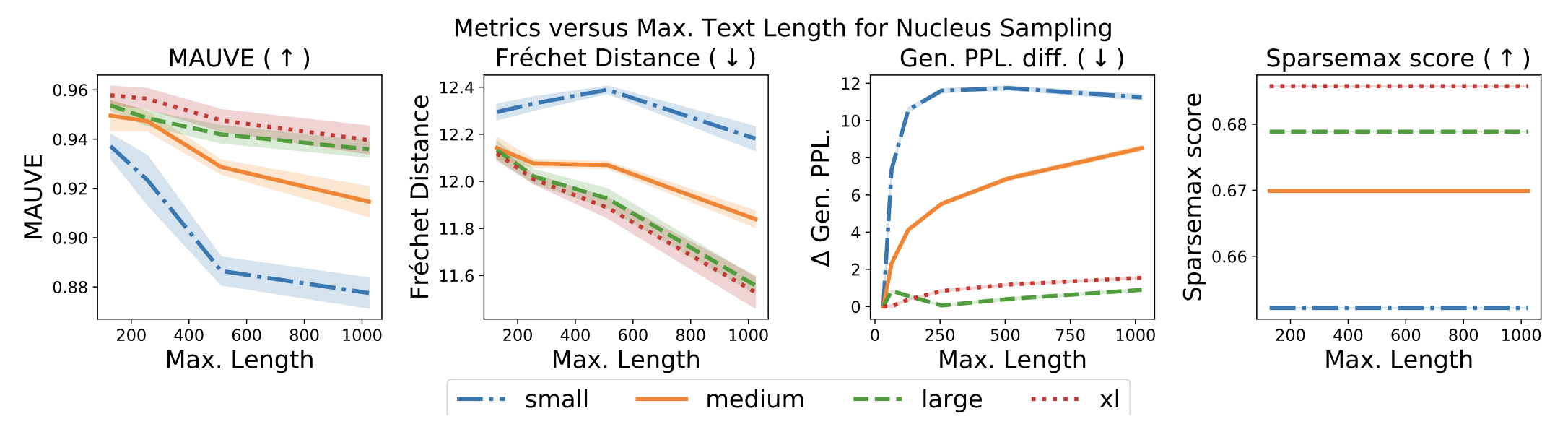
左のMAUVEが唯一変化を捉えられていることがわかります。他の指標で全てのモデルサイズで変化を捉えられているものはありません。
デコーディングアルゴリズムやモデルサイズの違いを捉えられるか
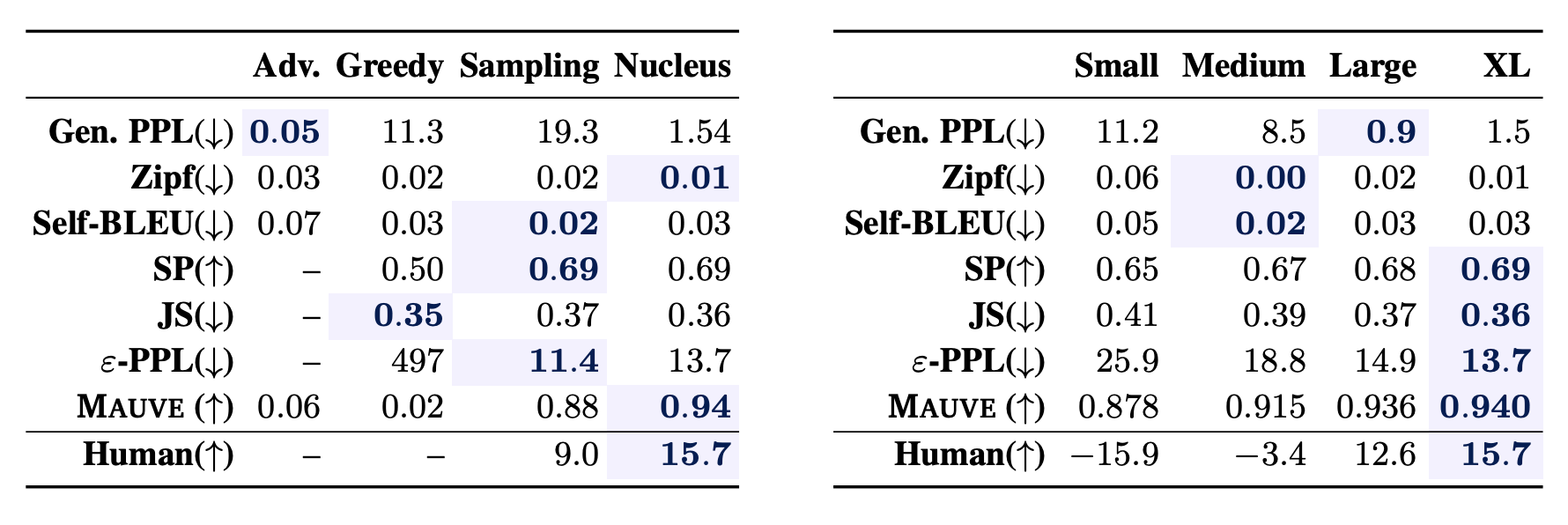
左の表をみると、MAUVEがGreedy decoding<Ancestral sampling<Nucleus samplingの順にスコアをつけられていることがわかります。また、右の表ではGPT-2のモデルサイズにおいてもSmall, Medium, Large, XLと大きくなるにつれてMAUVEが大きいスコアをつけられています。
人手評価との相関があるか
これまではempiricalな評価でしたが、一番重要な人手評価と相関があるかをみていきます。オープンエンドのタスクの評価でよく使用される、Human-like, Interesting, Sensibleの3つの指標を採用し、モデルで生成されたテキストに対してアノテーションします。各メトリックと人手スコアとの相関係数が以下の表です。

MAUVEが先行研究と比べて大幅に高い相関を示しています。その相関の高さから高精度にオープンエンドのタスクの評価が行えるといえそうです。
まとめ
今回は生成されたテキストのクオリティを高精度に評価できるMAUVEについて紹介しました。
精度面もさることながら、すでにpipを通して利用できるようになっており、モデルのトレーニングも必要ないので使い勝手がかなり良さそうです。オープエンドのタスクの評価指標として、新たなデファクトスタンダードになる可能性も十分あると思われます。
一方で、サンプリング数やクラスタリングアルゴリズムの選定など、新たなデータで指標を構築したい際はハイパラが多いことが障壁になりそうですが、本論文はAppendixでかなり丁寧に実験しているため、そこも高評価の一助になったと考えられます。オープエンドタスクの自動評価はいまだに決定的なものがなく、スコアの伸び方を見ても近年かなり改良が進んでいることが伺えるので、今後どのように発展するかたのしみな研究分野の一つです。





この記事に関するカテゴリー






