カメラにシールを貼るだけでディープラーニングを誤認識させる攻撃方法が登場
3つの要点
✔️カメラにシールを貼るだけでディープラーニングを誤認識させることが可能になった
✔️対象物を異なる角度や距離で撮影しても誤認識させられることを動画データで検証
✔️顔認証用のカメラにシールを貼っておくことでシステムに気づかれずに他人になりすましたりできてしまうかもしれない
ディープラーニングによる画像分類は高い性能を誇りますが、画像に摂動を加えるだけで、人間の目ではほぼ違いがないのにディープラーニングが他のカテゴリであると誤認識してしまう adversarial attack という攻撃方法が知られています。
この adversarial attack にどのように対応するかは、実世界でディープラーニングを含んだシステムを運用していく上で重要になるだけでなく、人間の認識とディープラーニングによる認識の違いを理解するのにも重要であり、一つの大きな研究テーマにもなっています。
これまで、画像のピクセル値を直接いじるデジタルな攻撃方法や、被写体のそばに特別に印刷した物体を置いたりする攻撃方法などが知られていました。これらの攻撃方法は、システムに介入しなくてはならなかったり、画像にはっきりと異物が含まれていたりするので、被攻撃者に気づかれないようにするのは難しく、現実的には使われにくいようなものでした(自動運転をターゲットにして道路標識に攻撃を仕込んでおくなどはできるかもしれません)。
この論文では、被写体には全く手を加えずに、撮影をするカメラに色のついたシールを貼っておくだけで攻撃が可能となることが示されました。性能に関してはまだまだ荒削りですが、例えば顔認証用のカメラにこっそりシールを貼っておくことで、他人になりすましてセキュリティを突破するというようなことができるようになってしまうかもしれません。
以下の動画が実際の攻撃の様子で、様々な角度や距離から「道路標識」を「ギターピック」に誤認識させることに成功しています。
注意事項として、このような攻撃は単一のディープラーニングのモデルに対して有効なものとなっています。複数のモデルに対して有効な攻撃もあるのですが、この記事で紹介する攻撃は単一のモデルに対して有効なものであると考えてください。
従来の攻撃方法との違い
画像をデジタルに操作する
最初に登場した adversarial attack は画像のピクセル値を操作するというものでした。典型的には以下のようなものです。
摂動を加えた画像は人間の目から見ると元の画像とほぼ変わらないものですが、ディープラーニングは元画像のラベルとは違うラベルであると分類してしまいます。このような摂動を作るメカニズムは、ごく簡単に言うと、ノイズの大きさの上限値を決めた上で損失関数に基づき他のラベルと間違えるように画像にノイズを加えていく、というものになっています。

摂動を加えてディープラーニングが誤認識する画像を作る様子。左の列は元画像で、中央の列は加える摂動、右の列は摂動を加えた画像でこれらはすべて「ダチョウ」と分類されてしまいます。論文 (https://arxiv.org/abs/1312.6199) より引用。
これは非常に興味深い性質で後に様々な研究に繋がっていきますが、攻撃という観点ではディープラーニングを含むシステムに侵入して画像をいじる必要があるのであまり現実的なものではありません。
被写体の近くに特殊なパッチを置く
その後、デジタル画像に手を加えることなく、被写体のそばにパッチを置くだけで誤認識を引き起こす攻撃方法が発見されました。色々な画像に対してパッチを置いた時に特定のクラスに間違えるようにパッチを作成することができます。
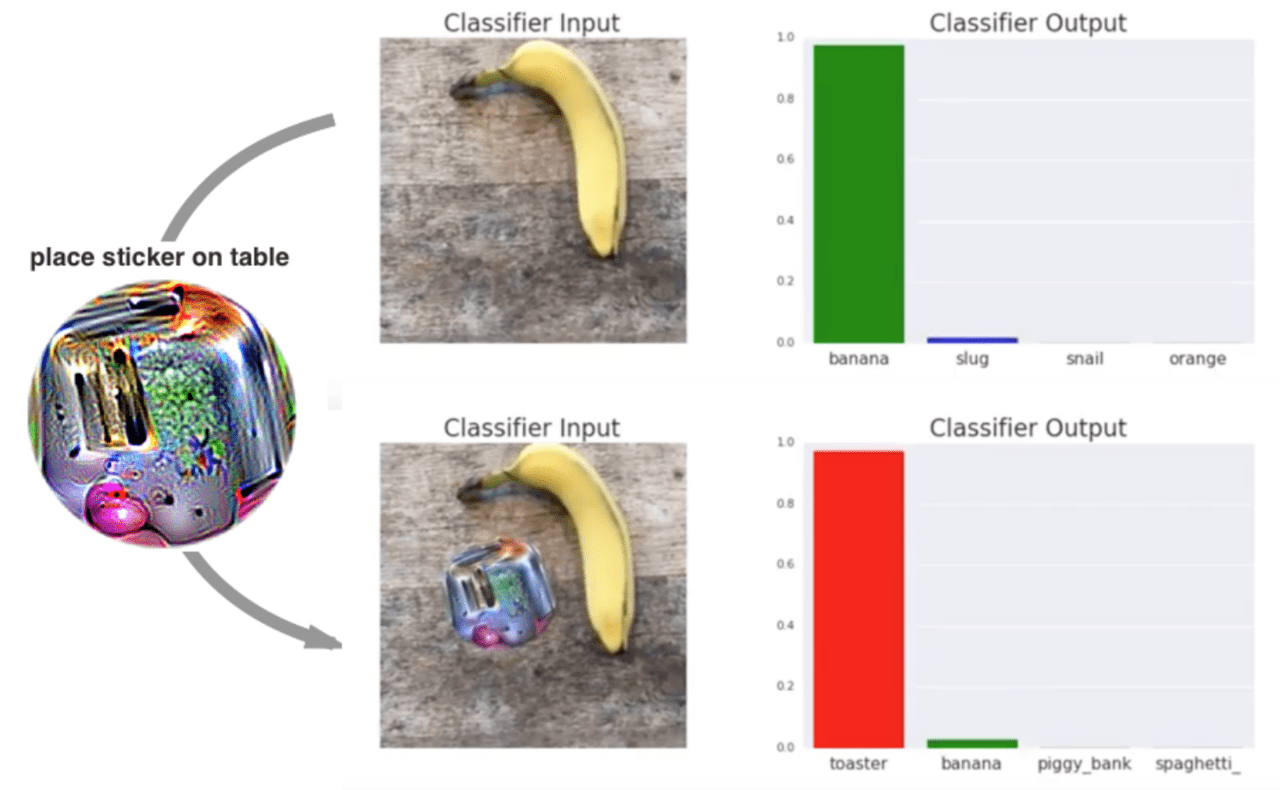
被写体のそばに特殊なパッチを置いてディープラーニングを誤認識させる様子。パッチの存在によって、「バナナ」が「トースター」に分類されてしまいます。論文 (https://arxiv.org/abs/1712.09665) より引用。
これはデジタルな操作が必要ないため、攻撃という観点でも興味深いものとなります。例えば道路標識などにこのパッチを付随させておくことは自動運転の障害になるかもしれません。
しかしながら、被写体側にあからさまな変更を加える必要があって攻撃されていることが明確なため、現実的にはかなり用途が限定されるでしょう。
カメラにシールを貼る(この論文での提案手法)
この論文では、カメラに色付きのシールを貼ることでディープラーニングに誤認識を引き起こす手法が発明されました。
詳細は後に説明しますが、以下の画像のようにカメラにシールを貼るのみで被写体には何も手を加えないという点が特徴です。

カメラにシールが貼られている様子と、そのカメラで撮影した画像の例。撮影した画像には少し色がついている部分があることが見て取れます。論文 (https://arxiv.org/abs/1904.00759) より引用。
撮影された画像には少し色がついていてそういった点で被攻撃者が気づく可能性もありますが、従来手法と比べると適用範囲は遥かに広いことが分かります。
顔認証決済などが話題に上ったりしますが、気付かぬ間に他人が自分になりすまして支払いを肩代わりさせられる、ということになったりするかもしれません。
以下ではこのような攻撃用シールをどのように作成するのかを解説していきます。
攻撃用シールの作り方
まずは抽象的な定式化をしておきます。
$(x, y)$ が画像とラベル、$\pi$ が画像に加える摂動、$l$ が損失関数としたときに、ある特定のラベル $y_{targ}$ に誤認識させるには以下を解くことになります。ここでは一サンプルだけ考えていますが、実際にはラベル $y$ の様々な画像をサンプルして期待値を最大化することで汎化させます。
\[
\max_{\pi \in \Pi} \left( l(f(\pi (x)), y) – l(f(\pi (x)), y_{targ}) \right)
\]
これだけでは画像をいくらでも変更できてしまって摂動ではないので、$\pi(x) = x + \delta$ としたときに拘束条件として $||\delta||_p \leq \epsilon$ を課すことで元画像からの変更を小さなものに制限します。
ここで、$x$ は当然デジタル画像のピクセル値になるので、カメラにシールを貼って撮影することで操作をすることはできますが、細かい操作をすることはできません。
細かい処理を用いずに目的を達成するために、この論文ではシールに色付きの半透明の丸模様をプリントするという方法を採用します。撮影された画像は元画像と丸模様のアルファブレンディングとなります。以下が具体的な例です。

摂動としての半透明の色付き丸模様と、それを印刷してカメラに貼って撮影した画像の例。論文 (https://arxiv.org/abs/1904.00759) より引用。
これを次のように定式化していきましょう。
一つの半透明色付き丸模様があるとき、$x(i,j)$ を元画像のピクセル値、$\alpha(i,j)$ を半透明色付き丸模様のピクセル値、$\gamma$ を丸模様の色としたときに、アルファブレンディングした画像のピクセル値を以下のように書けます。
\[
\pi_0 (x;\theta)(i,j) = (1 – \alpha(i,j)) x(i,j) + \alpha(i,j) \gamma
\]
半透明色付き丸模様のピクセル値は、ある中心を定めてそこから離れると指数的に 0 になるようなものと定めます。イメージ図としては以下のようになります。
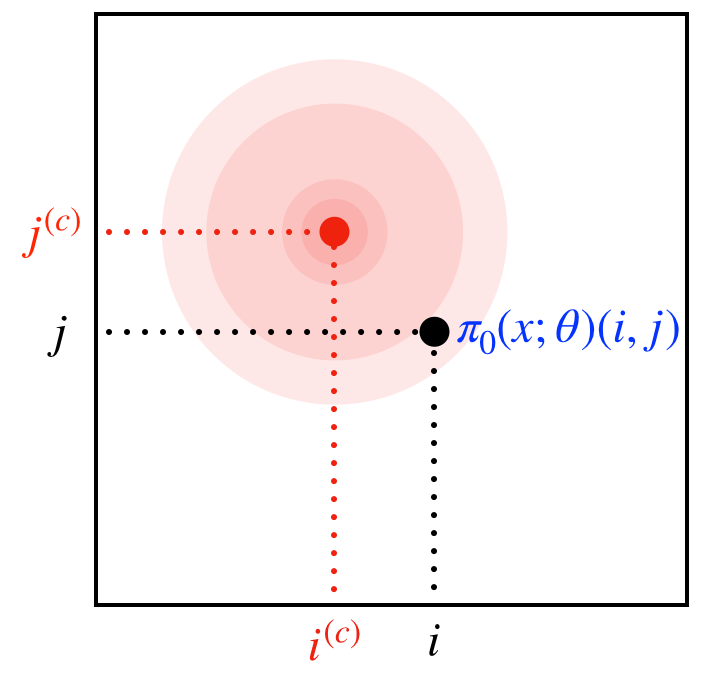
元画像と半透明色付き丸模様のアルファブレンディングのイメージ図。半透明色付き丸模様は中心から離れるとピクセル値が 0 に近づいていくので、中心にある程度近い領域だけに影響を及ぼすようになります。
これを使って実際に攻撃用シールを作っていきますが、以下の二つの問題点があります。
- 色付き丸模様の数や濃さや色や位置など最適化すべきパラメタが多くて大変
- 物理的に実現困難な組み合わせだったり被攻撃者にとって分かりやすすぎるものも作られる
前者は、様々な予備実験によって多くのパラメタを固定(例えば丸模様の数は10個で固定)してしまって、実際に最適化するパラメタはそれぞれの丸模様の位置と色(そしてこの色も10通りに限定している)のみにすることで解決しています。
位置は微分可能ですが離散化した色は微分不可能なので、まずは greedy に最適な組み合わせを見つけ、その後に勾配法で位置を微調整します。
後者は、実現可能なものをベースにして進めることで解決しています。
被攻撃者に分かりづらくて物理的にも実現できる色をまず人力で定め、それを使ってデジタル画像でアルファブレンディングした画像を作り、できるだけそれに近づくようにシールを作成する、というステップになっています。
以上により、実際に攻撃用のシールを作成することができるようになりました。
実験結果とまとめ
画像分類のモデルとしては ImageNet pre-traiend ResNet-50 を使用し、攻撃用シールとしては 5 種類作成し、動画を 1000 フレーム撮影してどれくらい誤認識をさせられたかを測定したものが以下のものとなります。
元々の正しいラベルと分類するフレームも 2,30% ほどありますが、確かに誤認識させたいラベルに分類させることに成功していることが見て取れます。冒頭の動画はこの中の Street sign -> guitar pick の場合となります。
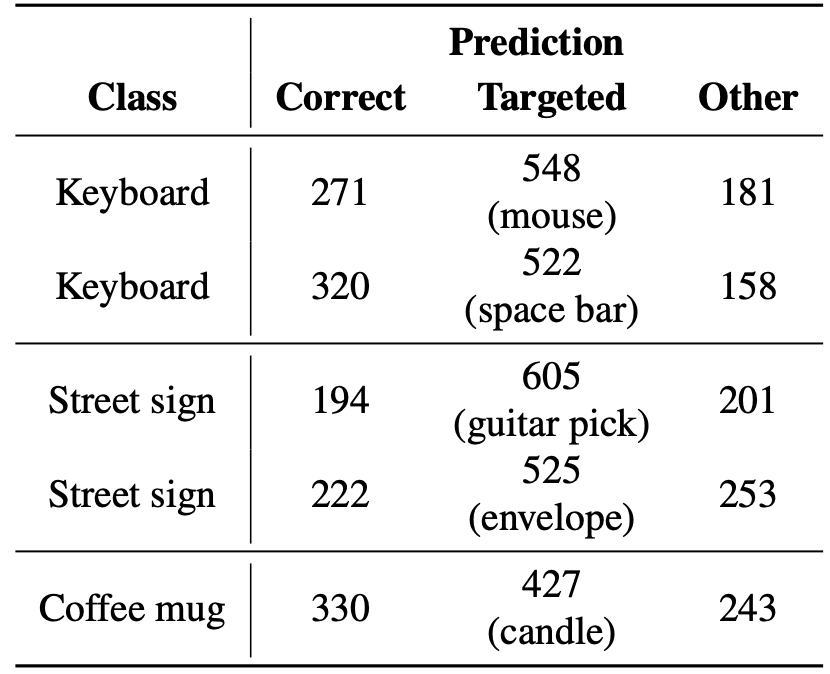
実験結果。Class は元々のラベルで、Prediction Targeted の括弧内のラベルに誤認識させたいという問題設定。論文 (https://arxiv.org/abs/1904.00759) より引用。
実際に攻撃に使うには、より高い誤認識率、より被攻撃者が気づきにくい攻撃、特定のモデルでなくて色々なモデルに有効な攻撃、などが必要になってくると思いますが、カメラにシールを貼るだけという難しい条件にも関わらずディープラーニングを誤認識させることができると示されました。
ディープラーニングを含むシステムを運用する観点からは、このような攻撃方法の存在に関しても注意せねばならない日がやってくるかもしれません。
より高い誤認識率の攻撃のためには、更に広い範囲でパラメタの最適化を実施したり異なる種類の模様を試したりするということが考えられます。被写体への操作も合わせて効果を増大させるというような方向性もあるかもしれません。
より被攻撃者に気づきにくい攻撃のためには、知覚的に気づきにくいパラメタ領域の探索する余地がありますが、摂動によって元画像に変更を加える時に人間にとってどういうものがより変化として認識されづらいかを調べていくのも面白いかもしれません。
特定のモデルでなく色々なモデルに有効な攻撃のためには、Universal adversarial perturbations のような先行研究の結果を取り入れていくことができるでしょう。
その他にも、データセットを変更して顔認証で試してみたり、様々な被写体が映る自動運転の画像で試してみたり、実際の攻撃をイメージした実験をしていくのも興味深い発展です。
このように様々な方向性から研究が進んで、adversarial attack への理解が進み、注意点をより深く理解したりその結果として防御方法も発展していくことで、ディープラーニングを含むシステムがより安全に運用できるようになっていくことが期待されます。
この記事では、カメラにシールを貼ることでディープラーニングを誤認識させる研究について紹介しました。
adversarial attack はディープラーニングの研究でも特に盛んなテーマの一つですので、今後の展開にも注目です。
Adversarial camera stickers: A physical camera-based attack on deep learning systems
written by Juncheng Li, Frank R. Schmidt, J. Zico Kolter
(Submitted on 21 Mar 2019)Accepted to the 36th International Conference on Machine Learning
Subjects:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR); Machine Learning (cs.LG); Machine Learning (stat.ML)




この記事に関するカテゴリー






