キャッチコピーの強調キーワードもニューラルネットで自動決定!
3つの要点
✔️短いフレーズから強調するべきキーワードを付与したデータセットを作成
✔️単純なニューラルネットワークでもキーワードの検出が可能
✔️コンペ形式で手法を募っており、今後の動向に注目
弊メディア、AI-SCHOLARでは「AIをどこよりも分かりやすく!どこよりも身近に!」というキャッチコピーを掲げ、日々AIに関する論文の紹介記事を掲載しています。こうしたキャッチコピーを使ってポスターなどを作成する時、ただ文字列を貼り付けるだけでは味気がありません。そこで、多くのポスターはキャッチコピーのうち特に注目するべきキーワードを色やフォントの差で強調します。例えばAI-SCHOLARの例では、「AIをどこよりも分かりやすく!どこよりも身近に!」といったキーワードを強調することで、その特色をアピールすることができると考えられます。
このとき「どの単語を強調するべきか」という選択の基準は、作業をする人のセンスに大きく依存します。すなわち、人によって強調したい単語のチョイスに揺れがあります。例えば上のキャッチコピーに対して「AIをどこよりも分かりやすく!どこよりも身近に!」とする強調を好む人もいれば、「AIをどこよりも分かりやすく!どこよりも身近に!」のような強調を好む人もいるかもしれません。
もちろん、キャッチコピーに含まれる単語を見境なくキーワードとして強調すれば良いというわけではありません。強調するべき単語が少なければ少ないほど、強調の度合いは強まります。しかし、デザインや広告の素人にとって、効果的にメッセージを伝えられるキーワードを選択することは簡単ではありません。それでは、あるキャッチコピーが与えられた時に「もっともらしいキーワード」を機械学習で提案することはできないでしょうか。
本記事では、こうした動機に基づいてデータセットを作成し、キャッチコピーに対して強調するべきキーワードを抽出するというタスクを提案した論文をご紹介します。本論文の著者にはAdobe ResearchやAmazon Alexa AIといった企業の研究グループが入っており、より実用的なシステムを目指したタスクの提案として注目すべき動向です。
キャッチコピーから強調すべきキーワードを検出

どの単語がキーワードとして妥当なのか
前述した通り、キャッチコピーのような短文から効果的なキーワードを選択することは簡単ではありません。特に、元となる短文が母語ではない言語で記述されている場合、その難しさは跳ね上がります。例えば「Knowledge is only as good as it is actionable」という単語列のうち、どの部分がキーワードとしてもっともらしいでしょうか。
上図では、異なるキーワードを強調したキャッチコピーを用いたイラスト例を挙げています。どちらのレイアウトも今風で素敵ですが、強調している単語が異なるだけで、そのメッセージ性に差が生まれています。右側の図(b)ではknowledgeなどの意味がある単語を強調し、キャッチフレーズのメッセージ性を強めています。一方で左側の図(a)はasという単語を強調していますが、このデザインを見た人にとってはなぜasを強調しているのかがわからず、キャッチコピーの訴えかける内容を理解するのに時間がかかってしまいます。効果的にメッセージを伝えるという観点に立った時、図(b)のようなキーワードの強調がより効果的であると考えられます。
こうしたキーワードを自動的に選択するシステムを考えた時、もっとも単純な手法としては単語の頻度を利用するものが考えられます。例えば出現頻度が低い単語は強いメッセージ性を持つと仮定し、それをキーワードとして選ぶ方法です。上の例であれば、actinableという単語は他の単語に比べて使用頻度が低いので、キーワードとして妥当であるといった基準で選択を行います。
しかし、この方法を取った場合は使用頻度が高いgoodという単語を選択することができなくなってしまいます。つまり、こうしたキーワード抽出を自動で行うためには、人間が短文に対してキーワードを付与したデータセットを作成し、そのパターンを機械学習する必要があります。
人手による強調単語のアノテーション
そこで筆者らは、Amazon Mechanical Turkによるクラウドソーシングを用いたデータセットの作成を行いました。Adobe Sparkが提供している1,206のキャッチコピーなどの短文に対して、9人のアノテーターが強調するべきキーワードを選択します。9人のアノテータはそれぞれが自由にキーワードを選択しているため、キーワードは必ずしも一致していません。そのため、作成されたデータセットには9人それぞれに対応するアノテーションが付与されています。
下表は本論文で作成されたデータセットの一例です。「Enjoy the Last Bit of Summer」というフレーズのうち、キーワードに「I」、それ以外の単語に「O」というラベルが付与されています。A1〜A9はそれぞれのアノテーターを表しており、Freq.はその単語をキーワードとして選んだアノテーターの数を示しています。この単語ごとに付与されたIタグ、Oタグを教師信号としてモデルを学習することで、ある単語の「キーワードらしさ」が計算できるようになります。
また、アノテーターごとにアノテーション情報がつけられているため、それぞれのアノテーターの特徴を掴んだモデルを学習することもできます。例えばA2のアノテーターであれば、キャッチコピーの中程にある抽象的な言葉をキーワードとして選びやすい、といった学習ができるかもしれません。

シンプルなモデルでもある程度キーワードを検出できる
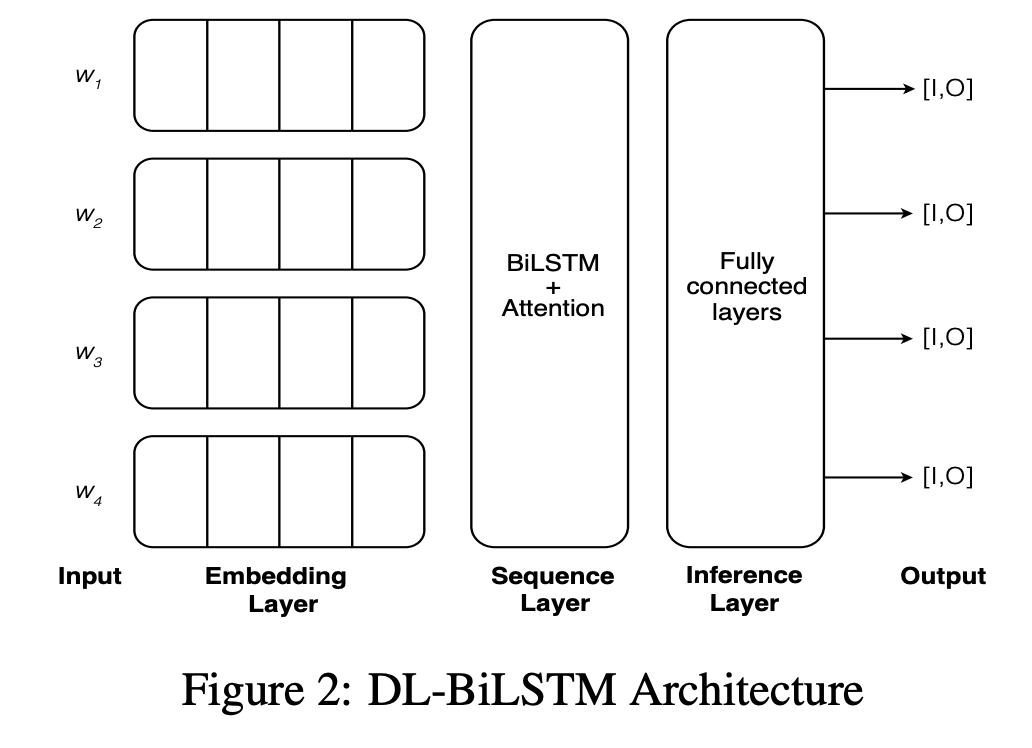
上で説明したデータセットは、いわゆる系列ラベリングと呼ばれるタスクとして解くことができます。系列ラベリングとは、ある意味のある順番で並んだデータ列のそれぞれに対してラベルを付与するタスクです。自然言語処理であれば、単語列に対して品詞を推測する品詞タグ付けタスクや、単語列からキーワードなどを抽出する固有名詞抽出といったタスクを、系列ラベリングとして見ることができます。
今回のデータセットも、キャッチフレーズという順番に意味のある単語列に対して、キーワードであるか(Iタグ)そうでないか(Oタグ)を付与する系列ラベリングとして考えることができます。系列ラベリングは自然言語処理で広く解かれているタスクであるため、ニューラルネットワークを用いた様々な手法がすでに研究されています。
今回の論文ではベースラインモデルとして、上図のようなニューラルネットワークを用いてデータセットの学習を行なっています。モデルは単語分散表現を注意機構付きのBiLSTMでエンコードし、対応する単語がキーワードになる確率を全結合層で計算するものになっています。このような比較的シンプルなモデルで学習を行った結果、テストデータでのTopK(K=4)指標で85%と、ニューラルネットワークで十分に問題が解けることが示されています。
なお、TopK指標とはキャッチフレーズのうちアノテーターがキーワードとしてもっともらしいと判断した単語上位4つと、モデルがキーワードとしてもっともらしいと予測した単語上位4つがどれだけ被っているかを測った評価指標です。
下図左は、学習済みのモデルを用いてキャッチフレーズのキーワードを予測した結果を示しています。赤色が濃い単語ほど、モデルがキーワードである確率が高いと判断したものです。図右の正解のキーワードと見比べると、満足できる程度にキーワードの予測ができていることがわかります。

SemEval2020 Task10として採用!
本データセットを用いたタスクは、SemEval 2020という自然言語処理のコンペに採用されています。SemEvalでは毎年様々なタスクでコンペが開かれ、多くの参加者がモデルを提案しその性能を競っています。今回のキーワード抽出タスクでも、多種多様なモデルが提案されると期待されます。
コンペは2020年の1月10日にモデル評価が始まり、夏ごろに提案手法の発表が行われます。単語列からキーワードを抜き出すというシンプルなタスクであるだけに、どのような手法や特徴量が高い性能を発揮するのか、ぜひ忘れずに注目しておきたいコンペです。なお、本データセットはこちらのフォームから入手することができます。
今回ご紹介したデータセットはAdobeによって提供されたキャッチコピーを元に作成されています。キーワードのアノテーションはクラウドソーシングによって作成されたものであるため、必ずしも効果的なキーワードが選択されているとは限りません。今後、プロのデザイナーなどによる「本気のアノテーション」が付与されたデータセットを作ることができれば、まさにプロのようなキャッチコピーの強調ができるニューラルネットが学習できるかもしれません。
こうした「実用的で面白いデータセット」を作れることは、大学にはない企業の強みと言えます。今回の論文を皮切りに、日本語でも同じようなデータセットが作成されれば、日本語での自然言語処理の応用がさらに発展していくと期待されます。
Learning Emphasis Selection for Written Text in Visual Media from Crowd-Sourced Label Distributions
Amirreza Shirani, Franck Dernoncourt, Paul Asente, Nedim Lipka, Seokhwan Kim, Jose Echevarria, Thamar Solorio
ACL2019




この記事に関するカテゴリー






