Fairness入門 ~AIに倫理観を教える~
AIを勉強している皆さんこんにちは。
皆さんはFairnessを知っていますか?
FairnessはAIの分野の一つで、近年とても注目されています。そこで、A Survey on Bias and Fairness in Machine LearningというFairnessのサーベイ論文を軸にしてFairnessの入門記事を書くことにしました。
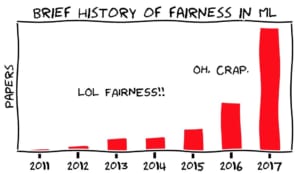
2011年から2017年までのFairnessの論文数
引用元: https://towardsdatascience.com/a-tutorial-on-fairness-in-machine-learning-3ff8ba1040cb
Fairness(公平)とは
AIにおけるFairnessという分野とは、「AIの判断を出来るだけ公平なものにしよう。」という分野です。公平なAIとは何でしょうか。例えば、人間に関する情報を入力とし、その人間が今後犯罪を犯す確率を出力するAIを考えましょう。人間に関する情報は年齢、性別、出身地、過去の犯罪歴などとしましょう。AIがそれらの情報を元に今後犯罪を犯す確率を計算するわけですが、当然学習にはデータセットが必要になります。そのデータセットにとてつもなく犯罪率が高い都市Aがあったとします。すると、AIは出身地の情報をとても重要視することになります。
AI「あ、この人の出身地は都市Aか。じゃあ犯罪する確率高めにしよう。」
という風になります。どうでしょうか。これって不公平じゃないでしょうか。
確かに、都市Aの犯罪率がとてつもなく高いならば、都市Aに住んでいる人は犯罪を犯す確率は高くなるかもしれません。しかし、まだ犯罪を犯していない好青年が、ただただ自分の生まれた土地のせいで犯罪を犯す確率を高く予想されてしまうというのは公平ではありません。だからと言って出身地情報を全く使わないで判断すると予測精度が著しく落ちてしまいます。ここら辺をきっちり議論しようという分野、それがAIにおけるFairnessです。
続きを読むには
(9303文字画像2枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






