图表转文本,一个巨大的图表总结基准,在这里!这是个很好的例子。
三个要点
✔️ 构建了一个大规模的基准,即图表到文本,包括两个数据集和44096个图表
✔️ 使用这个数据集和最先进的神经网络模型创建了一个基线
✔️ 针对基线进行了指标和人力评估。生成自然的摘要并取得合理的BLEU分数
Chart-to-Text: A Large-Scale Benchmark for Chart Summarization
written by Shankar Kantharaj, Rixie Tiffany Ko Leong, Xiang Lin, Ahmed Masry, Megh Thakkar, Enamul Hoque, Shafiq Joty
(Submitted on 12 Mar 2022 (v1), last revised 14 Apr 2022 (this version, v3))
Comments: ACL 2022
Subjects: Computation and Language (cs.CL)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
数据可视化,如柱状图、线状图和饼状图对于分析定量数据至关重要,而自动图表总结,即从图表中提供自然语言总结,是一个重要的工具。帮助人们从图表中获得重要的洞察力是一项重要的任务。
然而,到目前为止,这项图表总结任务很少受到关注,主要是由于两个问题
- 缺少大型数据集,无法使用现代神经网络模型来执行这项任务
- 使用最新的神经网络模型,在这项任务中没有强大的基线
本文介绍了一篇解决上述问题的论文,它使用由44096个广泛的主题和各种类型的图表组成的两个数据集,为图表总结任务建立了一个大规模的基准,并使用最先进的神经网络模型对其进行基线分析。
图表到文本数据集
在本文中,使用了以下步骤来构建数据集。
数据收集
在搜索了各种来源,包括新闻网站、教科书和网站后,我们发现以下两个来源有足够数量和类型的图表,并有文字说明
- Statista:一个在线平台,定期发布关于各种经济、市场和民意调查主题的图表,在2020年12月发布的34810个网页中共检索出34811张图表。
- 皮尤研究:一个发布有关社会问题、公众意见和人口变化趋势数据的网站,2021年1月发布的3999个网页中共有9285个图表。
对于获得的每张图表,都下载了图像、周围的段落和相关的文字,并将每张图表人工分类为简单或复杂。
数据注释
对于收集到的两个网站上的每个图表,都有一个摘要说明。
对于从Statista检索到的图表,图表所附文本的第一部分被注释为图表摘要文本,这是基于"在图表所附文本中,第一句话通常描述了图表的简短摘要,其余部分包含背景信息(如历史)"的假设。标注为图表的摘要文本。
另一方面,皮尤研究公司遇到的问题是,由于网页中包含大量的图表,很难简单地检索出附在图表上的文字,因此使用下图所示的程序进行了注释。

- 使用最先进的OCR模型CRAFT检测图表中的文本。
- 通过梯度提升将检测到的文本分类为以下类别之一:标题、轴标签、图例或数据标签。
- 为每个图表和相关段落做注释
对数据集进行分析
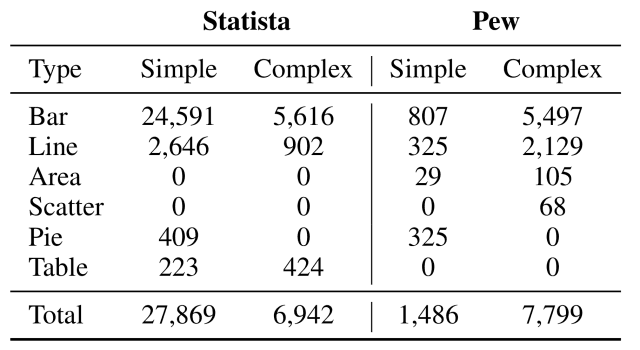
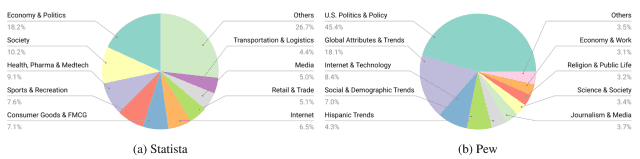
如下表所示,制作的数据集包括各种类型的图表,如柱状图(Bar)和线状图(Line),涵盖了政治(Economy&Politics)、社会(Society)和健康(Health)等广泛的主题。健康。
图表到文本的基线模型
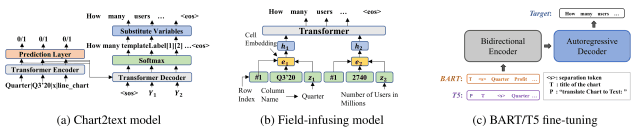
在本文中,使用下图所示的三个模型开发了一个基线模型。
-
Chart2text模型(Obeid和Hoque,2020):基于Gon等人(2019)的数据到文本模型的Transformer模型,针对图表到文本进行修改。
-
现场灌输模型(Chen等人,2020):基于概念到文本的工作创建的模型(Lebret等人,2016)。
- BART(Lewis等人,2020):一个采用seq2seq Transformer架构的模型,用于预训练去除噪音,为文本生成任务进行预训练。
- T5(Raffel等人,2020):一个统一的seq2seq Transformer模型,将各种NLP任务转化为text2text。
如果有一个输入的数据表,则按原样使用,否则所有OCR文本按从上到下的顺序串联起来,作为输入给模型。
从图表到文本的评价
最后,通过评级指标进行自动评价,并对照基线进行人工评价。
自动评估
以下五个评价指标被用于自动评价
- BLEU:衡量正确答案和模型生成的句子的相似程度。
- CS(内容选择):与BLEU类似,衡量模型生成的句子与正确句子的相似程度。
- BLEURT:一个基于模型的评价指标,衡量生成的句子在语法上的正确程度。
- CIDEr:通过计算由TF-IDF加权的n-gram重叠度,用于评估图像的标题生成模型。
- PPL(Perplexity):语言模型中使用的一个指标,如果在生成的句子中正确预测了正确的词,则该指标较小。
使用上述评价指标的结果显示如下。(TAB-指使用数据表的模型,OCR-指使用OCR提取的数据的模型)。
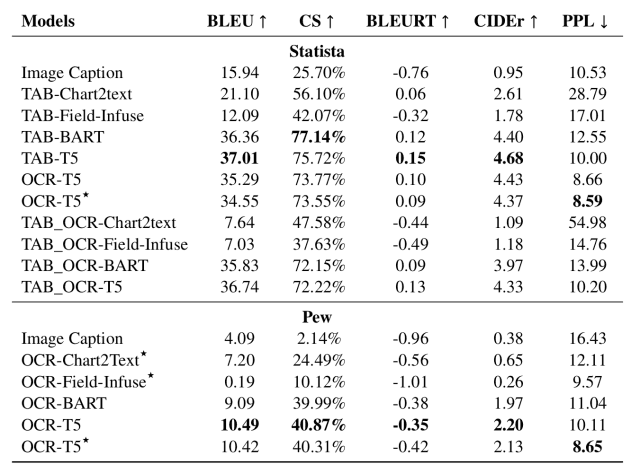
从这个表格中,我们发现
- 大规模的预学习模型(BART,T5)显示出总结性能的显著提高
- 在Statista中,给定一个数据表,Chart2text和Field-Infuse模型能够从数据表中提取信息,但很难生成高质量的摘要报表(可能是因为这些模型没有经过大规模的预训练)。
- 另一方面,TAB-BART和TAB-T5能够生成结构化的、适当的概要句子。
- 基于OCR的模型通常能够产生高质量的摘要文本,但由于OCR过程中在输入数据中引入了噪音,因此提取相关信息的能力稍差。
因此,大规模的预训练模型,如BART和T5,被发现具有最好的总结性能。
人的评价
为了进一步评估所生成的摘要声明的质量,本文由四位英语为母语的注释者对Statista数据集中随机抽样的150张图表的质量进行了评估。
对于每个图表,注释者根据三个标准来比较总结性陈述
- 事实性:哪种总结性陈述在事实上更正确(即提到的事实得到了图表的支持)
- 连贯性:哪一个总结性陈述更连贯(即句子连接良好)?
- 流利性:哪种总结性陈述更流利,语法更正确
对于每个标准,注释者选择前者为更好(总结1赢),后者为更好(总结2赢)或平局(平局)。
比较结果显示如下。

结果显示,TAB-T5在所有三个标准上都明显优于OCR-T5(尤其是在Factual方面)。
此外,不使用数据表作为输入的OCR-T5模型倾向于产生更多的解释错误(以红色显示,即输出的句子内容与给定的输入不同)和事实错误(以蓝色显示,即图表中的一个数值被误认为另一个),如下图所示。该图表倾向于显示出大量的致幻错误(红色)和事实错误(蓝色,即图表中的一个值被误认为是另一个数据集中的一个值)。

这被认为是由于通常不可能从OCR文本中生成事实正确的句子,而解决这些问题将是未来的一个挑战。
摘要
情况如何?在这篇文章中,我们描述了Chart-to-text,这是一个大规模的图表总结的基准,它是使用最先进的神经网络模型建立和建立的。
虽然使用本文创建的数据集的基线可以进行适当的图表总结,特别是在大型预训练模型中,但它也揭示了图表总结任务所特有的一些挑战,例如在没有数据表的情况下,性能明显下降,未来的发展有待注意未来的发展。
所介绍的数据集和基础模型的架构的细节可以在本文中找到,如果你有兴趣,应该查阅。



与本文相关的类别
