你可以通过简单地改变数据顺序来攻击一个神经网络!
三个要点
✔️ 通过改变数据批处理顺序的攻击方法
✔️ 利用了学习过程的随机性质
✔️ 证明了模型性能的下降,学习进度的重设和后门攻击
Manipulating SGD with Data Ordering Attacks
written by Ilia Shumailov, Zakhar Shumaylov, Dmitry Kazhdan, Yiren Zhao, Nicolas Papernot, Murat A. Erdogdu, Ross Anderson
(Submitted on 19 Apr 2021 (v1), last revised 5 Jun 2021 (this version, v2))
Comments: NeurIPS 2021 Poster
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
机器学习模型可以通过污染其训练数据而受到攻击,这可以降低训练模型的性能并引入后门。
然而,这种对抗性攻击需要攻击者能够操纵用于学习的数据,这可能是不切实际的。
本文提出的论文表明,只要在训练期间改变数据的批次和顺序,就可以影响模型的行为,而不是像现有的攻击那样改变训练的数据。
整个管道
所提出的方法,即批量重排、重新排序和替换(BRRR)攻击,是基于在训练过程中操纵批量的顺序和批量中数据的顺序。
这是一种黑匣子攻击,攻击者无法访问被攻击的模型,并遵循以下管道
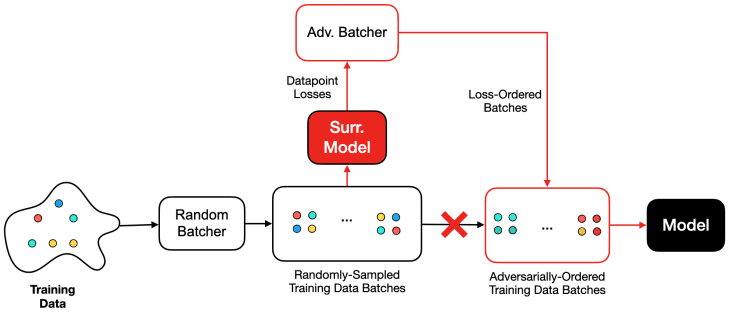
攻击者不能够访问被攻击的模型,而是平行地训练代用模型,并根据输出结果,在训练过程中重新排列批次或其数据,或用数据集中的其他数据替换。
在这种情况下,我们不向数据添加噪音或做任何其他处理。
攻击BRRR的背景
可以说,所提出的攻击技术利用了当前深度神经网络的概率性质。
首先,假设被攻击的模型是一个深度神经网络,参数为$theta$,训练数据集$X={X_i\}$,损失函数$L(\theta)$。如果第i个数据点对应的损失是$L_i(\theta)=L(X_i,\theta)$,那么第k$批(大小为$B$)的损失平均值是$hat{L}_{k+1}(\theta)=frac{1}{B}\sum^{kB+B}_{i=kB+1}L_i(\theta)$。现在,如果整个训练中的样本数是$N\cdot B$,我们希望优化的损失是$hat{L}(\theta)=frac{1}{N}\sum^N_{i=1}\hat{L}_i(\theta)$。
在这种情况下,在学习率为$eta$的情况下,SGD算法中的权重更新由以下公式表示
- $\theta_{k+1}=\theta_k+\eta\\\Delta \theta_k$
- $Delta\theta_k=-\nabla_theta\hat{L}_k(theta_k)$
在这种情况下,经过$N$次SGD步骤的参数如下

如该方程所示,最终参数$theta_{N+1}$包含了一个取决于训练期间批次顺序的项,这是由数据顺序依赖性表示的。所提出的方法通过操纵它来攻击这个顺序相关的项,例如降低最终模型的性能。
这是对学习算法属性的利用,该算法假定批量抽样程序是无偏的。
如果抽样程序是无偏的,可以认为小批量的梯度近似于真实的梯度,但所提出的方法通过人为地操纵数据的批次顺序来利用和攻击这一假设。
BRRR攻击的分类
BRRR攻击分为三种类型
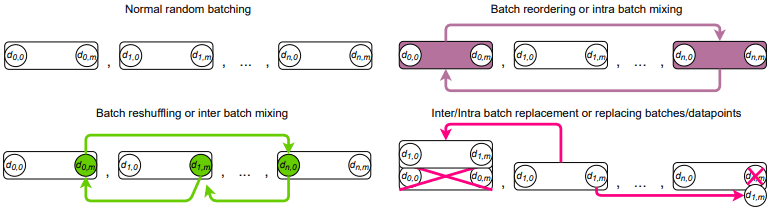
- 批量重新洗牌:改变一批数据点的顺序(一个数据点的出现次数不改变)。
- 批量重排:改变一个批次的顺序(批次中的数据点在内容或顺序上没有改变)。
- 批量替换:替换一个批次的数据点(数据点的出现次数可能会改变)。
在这里,改变批次或数据点顺序的政策分类如下图所示
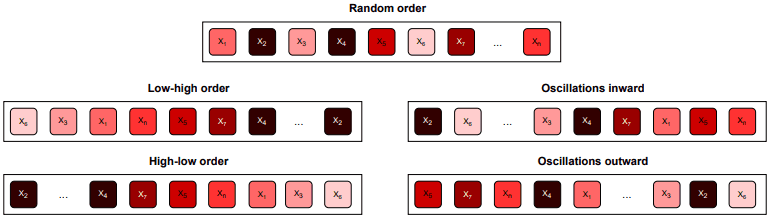
- 低-高:将损失从低到高排序。
- 高-低:将损失从高到低排序。
- 向内震荡:最高和最低损失的顺序交替进行。
- 向外震荡:在中位数以上的最小损失和中位数以下的最大损失交替排列。
这些攻击是根据以下伪算法进行的

关于更详细的伪算法,请参见原始论文中的算法2。
批量订单中毒(BOP)和后门(BOB)攻击
对机器学习模型的中毒后门攻击通常是通过在训练数据集$X$中加入一个敌对的数据点$hat{X}$或将数据点改为$X+\delta$来进行的。
批量重排攻击也可适用于这些中毒后门攻击。
具体来说,与敌对数据点$hat{X}_k$相对应的梯度被具有类似梯度的数据点$X_i$所接近($nabla_theta\hat{L}(hat{X}_k,\theta_k) \approx\nabla_\theta hat{L}(X_i,\theta_k)$)。
在这种情况下,参数更新规则如下

这是一种中毒后门攻击,可以在不改变原始数据集的情况下进行,这使得它成为一种强大的攻击,可以非常难以检测和防御。
实验结果
在我们的实验中,我们使用CIFAR-10、CIFAR-100和AGNews数据集。在CIFAR-10和CIFAR-100中,我们使用ResNet-18和ResNet-50作为源模型(攻击者),LeNet-5和MobileNet作为攻击者的代用模型。AGNews使用三个全耦合层作为源模型,一个全耦合层作为代用模型。
一般来说,与源模型相比,攻击者的代用模型被设置为较低的性能模型。
完整性攻击
下表显示了每个源模型在批量重新洗牌和批量重新排序下的最佳性能。
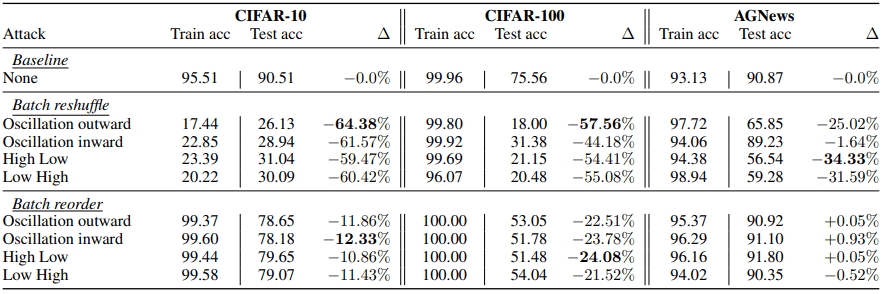
(更详细的结果见原论文表4)。
一般来说,我们可以看到,批量重排攻击在计算机视觉任务上效果很好,而批量重新洗牌攻击在任何任务上都很好。另外,每个源模型在Batch reshuffling攻击下的最佳性能是在第一个epoch,这时攻击者还没能学习到数据集,之后的大部分epoch,性能下降到低于随机预测。
下面是ResNet18上批量重新洗牌攻击的学习曲线的例子。
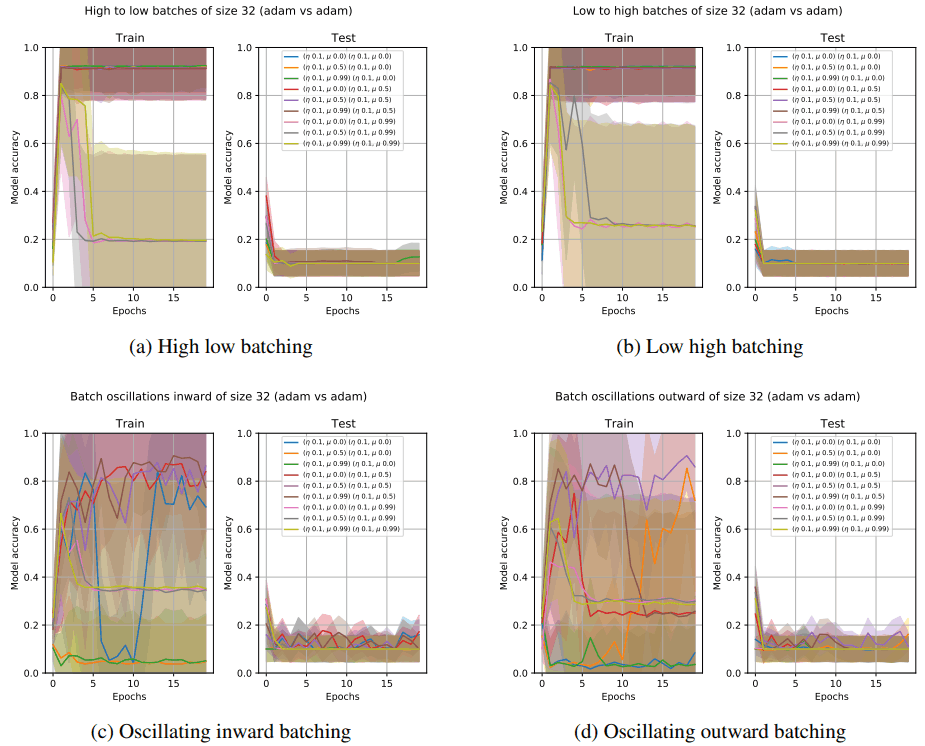
一般来说,我们发现改变数据点顺序或批处理顺序会降低模型的性能并重置训练结果。
可用性攻击
接下来,我们考虑可用性攻击。在这一节中,我们实验看看当攻击发生在特定的历时中时,我们是否可以延迟模型的训练。
其结果如下图所示。
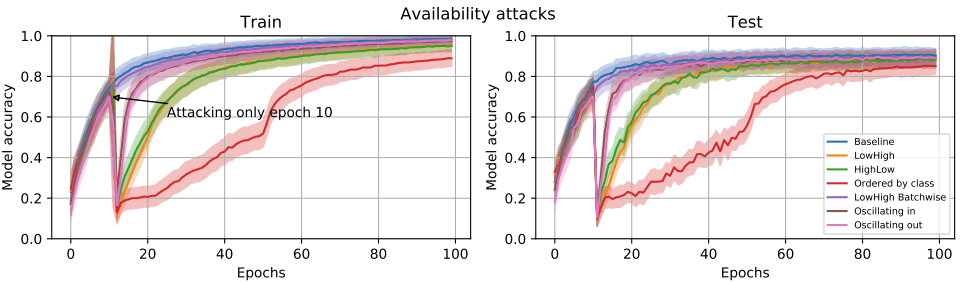
在这个图中,重排攻击只在10个历时中进行。在攻击成功的情况下,学习状态将被大大重置,需要很多个历时才能恢复到原来的性能,这可能是一个非常大的威胁。
后门攻击
最后,我们将通过改变批处理顺序来实验后门攻击。
在这里,我们对包含下图所示触发器的图像进行上述的BOB攻击。
结果如下(详细设置见原始论文)。

总的来说,事实表明,在不改变原始数据的情况下引入后门是可能的,只需插入少量重新排序的批次,尽管性能因触发器的类型和是否为黑盒而不同。
摘要
我们描述了一篇论文,提出了一种新的攻击方法,只需改变批次或数据点的顺序,而现有的方法则需要改变训练数据。令人惊讶的是,他们甚至表明可以通过改变数据点的顺序来进行后门攻击,这与现有的攻击方法大相径庭,引入了新的威胁。



与本文相关的类别



