不再需要大型计算机来训练深层生成模型了!二元深度生成模型
三个要点
✔️ 第一个成功生成图像的深度生成模型的二元神经网络架构
✔️ 为了享受传统二元神经网络中使用的批量归一化的效果,我们提出了 "二元权重归一化",它是权重归一化的二元版本。
✔️ 我们成功实现了激活函数和残差耦合的二元归一化,这些函数和残差耦合被用作深度生成模型的架构,而不损失性能。
Reducing the Computational Cost of Deep Generative Models with Binary Neural Networks
written by Thomas Bird, Friso H. Kingma, David Barber
(Submitted on 26 Oct 2020 (v1), last revised 3 May 2021 (this version, v2))
Comments: ICLR2021
Subjects: Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
产生高维数据的深度模型,如图像,需要高度的表现力,而训练这种深度生成模型的计算成本很高。
在本文中,我们使用了"二元神经网络",一种网络的权重是二元的架构,以显著降低计算成本,而不影响模型的性能。在本文中,我们将简要介绍二元神经网络作为背景,然后详细介绍本文介绍的方法。
什么是二元神经网络?
二元神经网络是一个神经网络,其中网络的权重以{-1,1}的二进制值表示。通过使权重成为二进制,可以将原本需要保存在32位的参数只保存在1位。
不仅如此,据报道,仅仅通过使权重变成二进制,学习速度就可以加快2倍,如果对该层的输入被限制为二进制,则学习速度可以加快29倍。因此,从记忆效率和学习效率这两个角度来看,二元神经网络是一个优秀的架构。
然而,权重的二进制化也有其缺点,如模型的表现力下降和优化的困难。
通常,在二进制神经网络中,每一层的权重和输入都是二进制的。为了对一个层的输入进行二进制化,一个符号函数被应用于前一层的输出。符号函数是一个用以下公式表示的函数
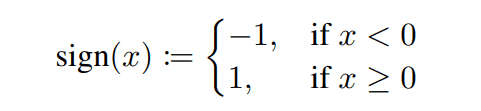
对于权重参数的二进制化,一个符号函数被应用于隐藏参数,该参数由一个实值表示。一般来说,这个隐藏参数是在优化过程中被优化的,而不是直接优化二进制权重。
在深度学习中,使用了基于梯度的优化方法,但符号函数很难学习,因为大多数地方的斜率都是零。因此,用一种叫做直通式估计器(STE)的方法来近似它,如下所示。
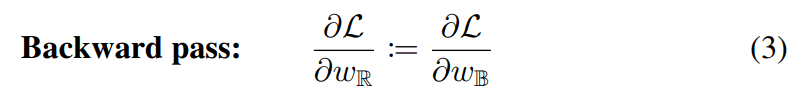
众所周知,当梯度变得非常大时,取消梯度的方法是有效的,按照这个方法,我们可以得到以下的剪裁权重参数的更新公式
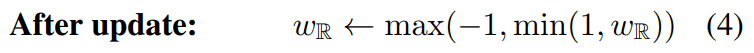
有针对性的深度生成模型
使用上述二元神经网络实现的深度生成模型是Hierarchical VAE和Flow++。这些模型在其他文章中有详细描述,但请注意,下面描述的二元神经网络所做的改变并没有改变每个生成模型的目的,而只是改变了架构。
下面描述的二值化方法主要集中在"权重正常化 "和"残差组合 "上,这些方法用于深度生成模型。
二元深度生成模型
在使用二元神经网络的深度生成模型中,本文提出了两种二元化的方法。
它们分别是"权重正常化的二值化"和"残留神经网络的二值化"。我将逐一解释。
权重标准化的二值化
在深度生成模型中,经常使用加权归一化而不是批量归一化。它也被用于上述的层次化VAE和Flow++中。加权归一化的表达方式可表示为在此,我们考虑将方程中的$v$二进制化。
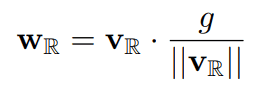
通过二进制化$v$,方程中的欧氏规范可以写成维数$n$的平方根。这意味着我们不需要计算权重的规范,从而减少了计算时间。
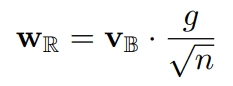
另外,在二进制权重规范化中,实际进行的唯一操作是乘以系数$alpha=gn^{-1/2}$。因此,带有二进制权重规范化的卷积操作对应于在与二进制权重卷积后应用系数$alpha$的操作。
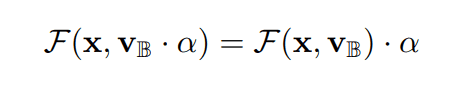
残余神经网络的二值化
在深度生成模型的架构中经常出现的一个结构是残差连接。
剩余耦合是一种具有跳过连接结构的架构,如下式所示。为了在不造成梯度损失的情况下提高模型的代表性,已经研究了剩余耦合,以解决随着层的深入,精度下降的问题。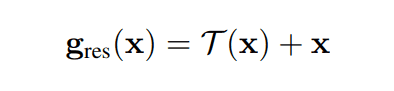
作者只选择了残值债券作为二进制化的目标,理由如下
- 生成模型需要特别高的表现力,而这种表现力原则上会被二进制化所削弱。
- 在生成模型中,数据点的似然性对模型的输出很敏感,而二进制化会导致模型的输出出现大的波动。
- 即使在残余边界被二进制化的情况下,身份函数是可学习的这一特性也被保留下来。
特别是,在基于归一化流量的生成模型中,如Flow++,要训练的函数的反变换的存在是一个要求,因此,在网络中使用的残差耦合可以很容易地代表一个同构图,这一点很重要。
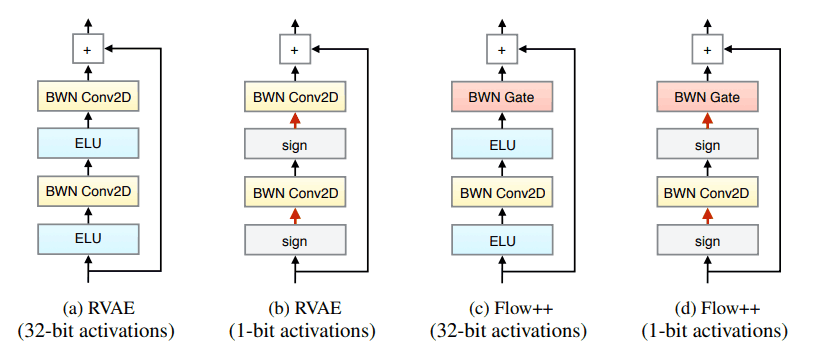
实验中使用的剩余耦合器的实际结构如下。有两种类型的输入,一种是实数向量,另一种是二进制向量,分别使用ELU和符号函数作为激活函数。传统残差匹配中使用的卷积层已被BWN卷积层取代。
图像生成实验
为了证实深度生成模型可以使用二元神经网络成功训练,我们在CIFAR和ImageNet中进行了图像生成实验。我们使用了两个生成模型,ResNet VAE和Flow++。
下表比较了在每个数据集上训练模型时的损失。表中的32位代表实际实现,1位代表二进制实现。增加宽度 "一栏显示了增加ResNet中的过滤器数量(从256到336)时的结果。
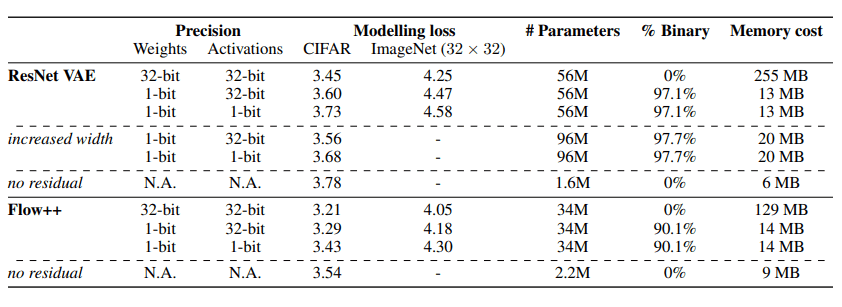
可以看出,对残差连接中的权重进行二进制化的结果比使用真实权重的结果要差一些。然而,在这两个模型中,二值化将内存成本降低到1/10和1/20之间。
这一结果表明,通过二进制化,在内存效率和性能之间存在着权衡。
内存成本的大幅降低使我们可以用更大的网络规模来训练模型,但从增宽的结果可以看出,当增加二元权重的数量时,我们并没有观察到性能的改善。
实际生成的图像看起来像这样。左边是具有实数权重的传统模型,右边是具有二进制权重的模型。可以看出,二元模型生成的图像并不逊色于传统模型。


摘要
你怎么看?本文的主要思想只是为了提高训练深度生成模型的内存效率,但令人惊讶的是,内存成本可以降低到1/10!这也是本文的主要目的。未来有可能在PC和智能手机上训练大规模的生成模型。
我们希望将来会有一个二元神经网络框架,像PyTorch或TensorFlow一样稳定使用。



与本文相关的类别
