无监督的持续学习!
三个要点
✔️ 关于无监督连续学习的研究
✔️ 建议LUMP防止灾难性的遗忘
✔️ 证明了无监督连续学习比有监督连续学习的优越性。
Representational Continuity for Unsupervised Continual Learning
written by Divyam Madaan, Jaehong Yoon, Yuanchun Li, Yunxin Liu, Sung Ju Hwang
(Submitted on 13 Oct 2021 (v1), last revised 15 Oct 2021 (this version, v2))
Comments: ICLR2022
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
持续学习,旨在学习一组任务而不忘记以前获得的知识,是一个解决深度学习中一个关键问题的研究领域:灾难性遗忘。然而,尽管这一领域的研究很活跃,但现有的方法却偏向于监督式连续学习(SCL)。因此,在难以获得高质量标签的现实世界中应用这些方法可能并不实际。
本文介绍的论文侧重于无监督持续学习(UCL),它涉及在一组无标签的数据上学习表征,同时避免灾难性的遗忘。
结果显示,与SCL模型相比,UCL模型具有更优越的特性,如对灾难性遗忘和分布转移更稳健。我们还提出了一种简单而有效的方法,将混搭应用于UCL,称为终身无监督混搭(LUMP)。(由于这些贡献,本文已被ICLR 2022接受(口头))。
关于设置持续学习问题。
首先,$T$的任务是$\textit{T}_{1:T}=(\textit(T)_1,...,\textit_T)$,我们考虑一个连续的学习设置,它在一个由$T$任务组成的连续数据集上学习。
对于有监督的连续学习(SCL),任务描述符$\tau \in \{1,...,T\}$,每个任务由$D_{tau}=\{(x_{i,\tau},y_{i,\tau})^{n_{\tau}}_{i=1}\}$的数据集组成,有$n_{tau}$实例。
每个输入对都是$(X_{i,tau},Y_{i,tau})/in X_{tau}×Y_{tau}$,其中$X_{tau},Y_{tau})$是一个未知数据分布。这里,将输入转化为嵌入的特征表示网络表示为$f_{\Theta}:X_{\tau}→R^D$(参数$\Theta=\{w_l\}^{l=L}_{l=1}$、$R^D$是$D$维的嵌入空间,$L$是层数)。分类器也是$h_{psi}:R^D→Y_{\tau}$。
然后,SCL的交叉熵损失由以下公式表示
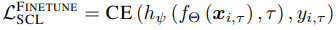
另一方面,由于本文侧重于无监督连续学习(UCL),每个任务由$U_{\tau}=\{(x_{i,\tau})^{n_{\tau}}_{i=1}\}$组成。那么,目标就是为一组任务学习一个特征表示$f_{\Theta}:X_{\tau}→R^D$,保留以前任务的知识。
学习协议和评价指标
在传统的连续学习策略中,一个网络表征$f_{\Theta}:X_{\tau}→Y_{\tau}$是在一系列的任务中学习的。另一方面,在无监督的连续学习环境中,目标是学习$f_{Theta}:X_{tau}→R^D$,所以学习协议是两阶段的。
- 第一阶段:一系列任务 $T_{1:T}=(\textit{T},...,\textit{T}_T)$是预学习的,表征是获得的。
- 第二阶段:K-近邻(KNN)分类器被用来评估预训练的表征的质量。
如果在学习了任务$T_{\tau}$之后,任务$i$的测试精度为$a_{\tau,i}$,那么对于通过连续学习获得的表征,可以定义以下两个评价指标。
- 平均准确率:在学习任务之前完成的所有任务的平均测试准确率$A_{\tau}=\frac{1}{tau}\sum^{\tau}_{i=1}a_{tau,i}$
- 平均遗忘:每个任务的最佳精度和学习完成时的精度之间的平均性能下降 $F=\frac{1}{T-1}\sum^{T-1}_{i=1}max_{\tau \in\{1,...,T\}}(a_{\tau,i}-a_{T,i})$
关于无监督的连续学习
通过一系列的任务进行顺序性的表征学习。
本文使用SimSiam和BarlowTwins进行无监督的连续学习,它们在标准表示学习基准上取得了最先进的性能。
关于SimSiam
SimSiam由一个编码器网络$f_{\Theta}$组成,包括一个骨干网和一个投影MLP $h(\cdot)$和一个预测MLP $h(\cdot)$。
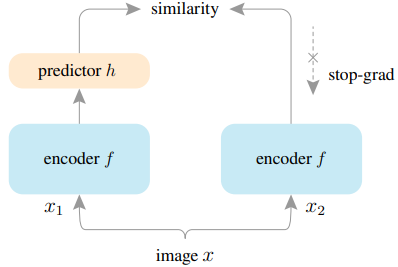
SimSiam被训练为最小化两个不同的增强处理图像$x^1_{i,\tau},x^2_{i,\tau}$的投影仪和预测仪输出向量的余弦相似度。
在这种情况下,对于预测器的输出$z^1_{i,\tau}=f_{\Theta}(x^1_{i,\tau})$和$p^2_{i,\tau}=h(f_{\Theta}(x^2_{i,\tau}))$,无监督连续学习的目标损失是其表达方式如下。
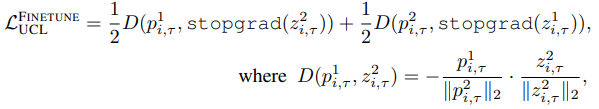
关于BarlowTwins
BarlowTwins学习使两个相同的网络(Encoder+Projectro)的输出之间计算的交叉相关矩阵更接近于一个身份矩阵。
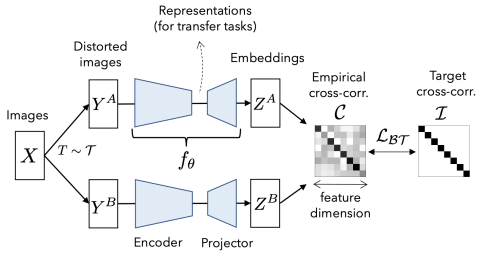
其中$C$是两个网络输出之间的交叉相关矩阵,无监督连续学习的目标损失可以表示如下
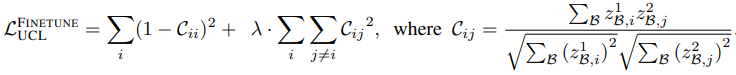
$\lambda$是权衡的正常数,$i,j$是网络输出向量维度。
对于SimSiam和BarlowTwins来说,它可以在几乎不改变现有持续学习策略的情况下应用。
关于现有的有监督的连续学习方法。
除了基于SimSiam和BarlowTwins的表征学习外,还将对将现有的有监督的连续学习方法扩展到无监督的环境的例子进行实验。具体来说,突触智能(SI)作为一种基于正则化的方法和渐进神经网络(PNN)作为一种基于架构的方法(即随着学习的进展改变模型架构的方法),扩展到UCL介绍。
此外,作为黑暗经验重放(DER)对UCL的扩展,引入了以下损失,作为一种基于排练的方法(一种以某种形式重用过去数据的方法)。
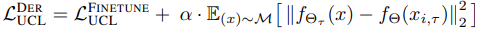
其中$M$是重放缓冲区。
另外,由于基于排练的方法的性能因$alpha$的选择而有很大的不同,本文引入了一个终身无监督的混合法来解决这个问题。
LUMP(Lifelong Unsupervised Mixup)。
在一个标准的混合中,两个随机样本$(x_i,y_i),(x_j,y_j)$用权重$\lambda$加在一起,形成一个新的样本。然后,损失函数由以下公式表示
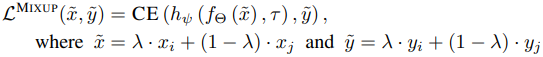
Lifelong Unsupervised Mixup(LUMP)使用存储在以前任务的重放缓冲器中的例子来训练Mixup。
也就是说,对于当前任务实例$(x_{i,\tau}\in U_{tau})$和从重放缓冲区采样的实例,创建一个插值实例$\tilde{x}{i,\tau}$,表示如下。
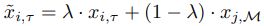
其中$x_{j,M}~M$表示从重放缓冲区$M$采样的例子。得到的$\tilde{x}{i,\tau}$被用作学习最小化$L^{FINETUNE}_{UCL}$的样本。
实验装置
基准线
实验比较了各种有监督/无监督的连续学习方法。
SCL(有监督的持续学习)。
- FINETUNE:学习一系列的任务,没有规律化和表象记忆。
- MULTITASK:用完整的数据训练模型。
- 基于正则化的方法:SI、AGEM。
- 基于架构的方法:PNN。
- 基于排练的方法:GSS, DER.
UCL(无监督的持续学习)。
无监督的连续学习使用SimSiam和BarlowTwins进行表征学习。然后对多个变体进行了如下实验。
- FINETUNE:如监督的案件。
- MULTITASK: 与监督的案件相同。
- 基于正则化的方法:SI
- 基于架构的方法:PNN。
- 基于排练的方法:将DER扩展到无监督的情况下
数据集
实验中使用的数据集如下。
- 分割CIFAR-10
- 分开CIFAR-100。
- 分裂的Tiny-ImageNet。
学习和评估设置
对于SCL的训练时间,遵循以往研究的超参数设置;UCL使用的是调整后的版本,并由KNN分类器进行三次独立运行的评估。
UCL方法经过200个epochs的训练。此外,每个数据集的超参数设置如下。

实验结果
实验结果如下表所示。
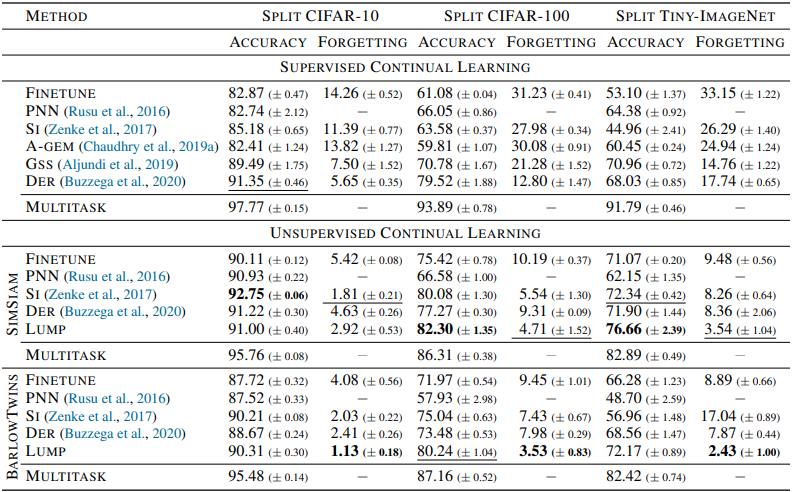
一般来说,无监督连续学习(UCL)比有监督连续学习(SCL)结果显示出更高的准确性和更低的遗忘率。
有趣的是,即使是UCL-FINETUNE设置,在没有正则化等额外方法的情况下,其表现也明显优于有监督的连续学习。文中提出的LUMP也明显比其他基线表现好。此外,每个任务的小数据集大小(FEW-SHOT)的结果如下。
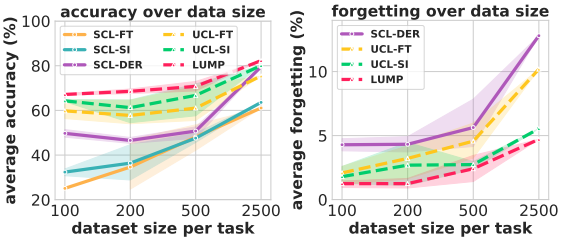
总的来说,无监督方法显示出明显优于有监督方法的结果,特别是在小数据量的准确性和大数据量的遗忘性方面。此外,所提出的方法LUMP在准确性和遗忘性方面都显示出优越的性能。每种方法在OOD(Out of Distribution)数据上的结果也显示如下。
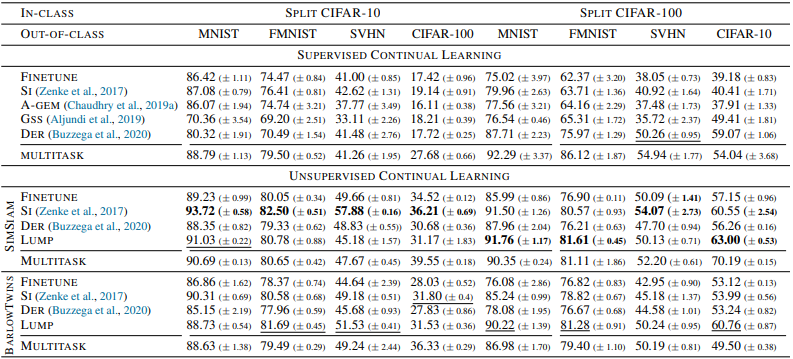
总的来说,结果显示,无监督连续学习的表现优于有监督设置的表现。
摘要
这篇文章介绍了针对无监督的连续学习的研究。文章通过实验证明,与有监督的连续学习相比,通过无监督的连续学习获得的表征是稳健的,并提出了一种抑制灾难性遗忘的方法,即LUMP。尽管存在一些挑战,如实验中使用的图像任务的分辨率有限,但还是提出了关于无监督连续学习的有用结果。



与本文相关的类别

![[MGSER-SAM]解决连续学习中灾难](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/mgser-sam-520x300.png)

