
领域适应模型的无监督调整
三个要点
✔️ 无监督领域适应在目标数据上有很高的预测性能,但由于缺乏监督数据,很难调整超参数。
✔️ 在本文中,我们设计了一个新的指标,即软邻里密度(SND),其假设是同一类的目标数据被判别器嵌入到彼此的邻里中。
✔️ SND被发现在图像识别和分割方面都更有效,尽管它与传统方法相比很简单
Tune it the Right Way: Unsupervised Validation of Domain Adaptation via Soft Neighborhood Density
written by Kuniaki Saito, Donghyun Kim, Piotr Teterwak, Stan Sclaroff, Trevor Darrell, Kate Saenko
(Submitted on 24 Aug 2021)
Comments: ICCV2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
虽然深度神经网络能够在图像识别中学习到非常准确的特征,但它们在不同的领域中不能保持其性能。为了弥补这一点,人们研究了无监督领域适应性(UDA),它涉及从具有充分监督数据的源数据中学习无监督目标数据的特征。近年来,各种UDA方法已经被开发出来,并在图像识别、语义分割和物体识别方面表现出很高的性能。然而,UDA的性能因超参数和训练迭代次数的不同而变化很大,这使得评估变得非常重要。由于UDA没有任何目标监督数据,如何对其进行超参数调整(HPO)?
一个传统而有效的方法是分类熵(C-Ent)。如果分类器对自己的输出有信心,并且熵很低,那么目标数据中的特征应该很容易识别,并能形成可靠的分类。然而,在分类器自信地将目标数据的一部分归入不同类别的情况下,C-Ent也会很低,如下图所示。
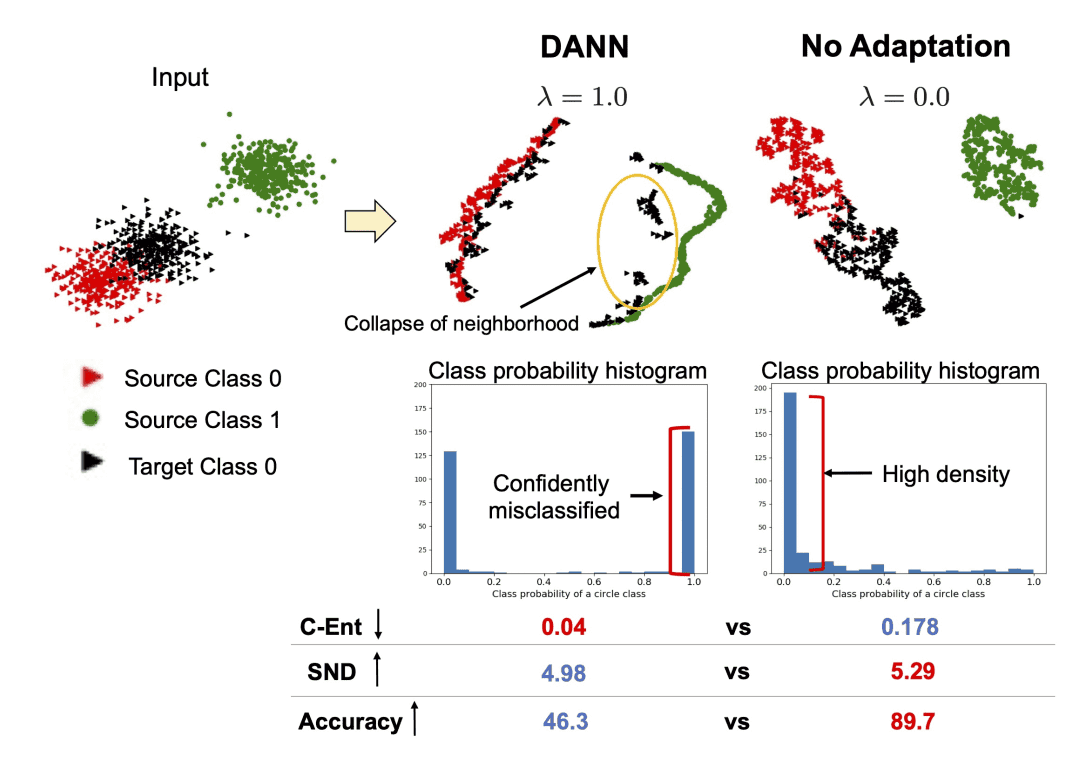
在本文中,我们定义了软邻里密度(Soft Neighborhood Density,SND),基于这样的假设:一个训练有素的模型会将同一类别的目标数据纳入近距离,形成一个密集的邻里点。SND是一个简单的措施,通过计算邻居的密度来衡量目标数据中特征的可识别性。
问题设置
如果源数据为$D_s={({bf x}_i^s, y_i^s)}_{i=1}^{N_s}$,目标数据为$D_t={({bf x}_i^t)}_{i=1}^{N_t}$,UDA的损失一般为
$$L = L_s(x_s, y_s)+lambda L_{adapt}(x_s, x_t, δ)$$
可写为其中$L_s$是源数据的分类损失,$L_{adapt}$是目标数据的适应损失,$lambda$是折衷参数,$eta$是计算$L_{adapt}$的超参数。我们的目标是找到一个能够优化$\lambda$、$\eta$和训练迭代次数的评价指标。
软邻里密度(SND)
SND的推导包括三个步骤:1)计算相似度,2)计算软邻接,3)计算SND,如下图所示。

相似性
首先,我们从目标样本$S\in\mathbb{R}^{N_t\times N_t}$计算相似性。然而,$N_t$是目标样本的数量。以$S_{ij}=<{bf f}_i^t, {bf f}_j^t>$定义相似性矩阵S,作为目标数据$bf{x}_i^t$的特征值,${bf f}_i^t$规范为$L_2$。然而,我们忽略了对角线部分,因为它们是不需要的。矩阵$S$定义了距离,但目前还不清楚样本之间相对于对方有多远。
软邻里关系
然后,为了突出样本之间的距离,我们用Softmax函数将它们转化为概率分布。
$$P_{ij}=\frac{\exp{(S_{ij}/\tau})}{\sum_{j'}exp{(S_{ij'}/\tau})}$$
其中$tau$是一个温度参数,用于调整样品之间的距离。因此,如果样本$j$与样本$i$不相对相似,$P_{ij}$将很小,样本$j$可以被忽略。在这个实验中,我们设定$tau=0.05$。
SND
最后,给定$P$,我们计算$P$的熵,作为说明邻域密度的一个尺度。如果$P_i$的熵很大,概率分布在软邻域内应该是均匀的。也就是说,样本$i$的邻域密布于非常接近的点。
$$H(P)=-\frac{1}{N_t}^{N_t}\sum_{i=1}^{N_t}\sum_{j=1}^{N_t}P_{ij}\log{P_{ij}}$$.
在像开头图中所示的分布的情况下,$H(P)$会很小,所以我们选择了$H(P)$最大的模型。另外,由于SND的目的是将目标数据的同一类别放在邻域,我们使用了分类器的softmax输出,其中包含${bf f}$的类别信息。
实验结果
图像分类
下图显示了准确度和评估指标相对于训练迭代次数的变化。
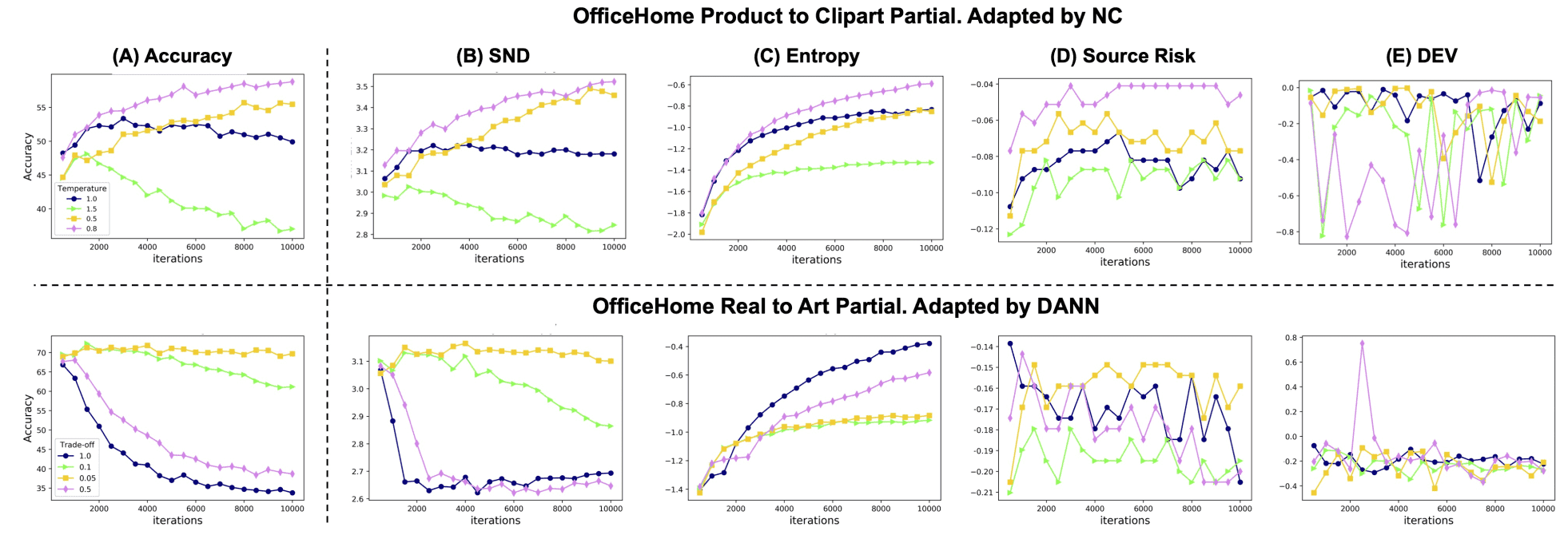 域适应(DA)方法显示出很大的变化,取决于超参数。然而,SND和准确率曲线是相似的。下表还显示了将不同的DA方法应用于几个数据集时的准确率结果。
域适应(DA)方法显示出很大的变化,取决于超参数。然而,SND和准确率曲线是相似的。下表还显示了将不同的DA方法应用于几个数据集时的准确率结果。

CDAN、MCC、NC和PL代表DA方法;A2D、W2A、R2A和A2P代表不同的数据集;Source Risk、DEV和Entropy(C-Ent)代表传统的评价度量。总的来说,SND的值最高,退化非常小,而其他指标在某些情况下表现明显更差。所有这些表明,SND在广泛的HPO方法中是有效的。
语义分割
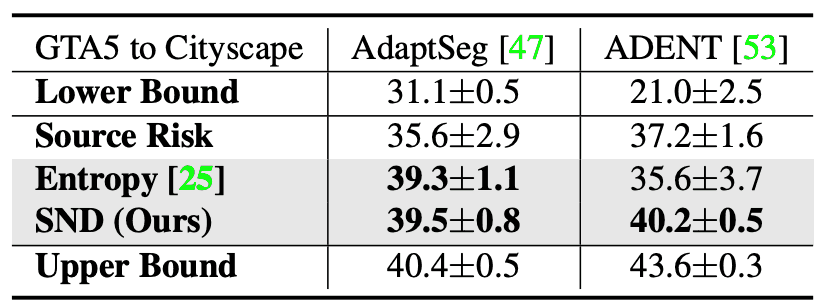
分割实验的结果如下表所示,其中DA方法是AdaptSeg和ADVENT,数据集是GTA5和CityScape。表中的数值是平均IoU(mIoU)。这两种方法的SND都很高。
摘要
在本文中,我们为UDA提出了一个更好的评价指标--SND,它考虑到了目标样本的聚类程度,并在各种数据集上与传统方法进行了比较。 HPO对于UDA方法至关重要,因为它们的性能因超参数的不同而有很大的差异。尽管SND显示出比传统指标更好的性能,但无监督的HPO也取决于DA方法,建立一个考虑到HPO工作方式的DA方法是未来的一个挑战。



与本文相关的类别
