[ICLR2021] 提高EBM训练的效率--从粗略的图像到精细的图像
三个要点
✔️ 提出了一种有效的方法,通过基于能量的模型(EBM)在图像生成中从低分辨率转移到高分辨率的训练。
✔️ 提出了一种不需要循环一致性的图像领域转换的新方法
✔️ 通过在图像生成、去噪、图像修复、异常检测和领域转换方面的各种实验,证实了所提方法的有效性。
Learning Energy-Based Generative Models via Coarse-to-Fine Expanding and Sampling
written by Yang Zhao, Jianwen Xie, Ping Li
(Submitted on 29 Sept 2020)
Comments: ICLR2021 Poster
Keywords: Energy-based model, generative model, image translation, Langevin dynamics
code:
本文所使用的图片要么来自该文件,要么是参照该文件制作的。
简介
本文介绍的从粗到细的EBM(CFEBM)是一种使用基于能量的模型(EBM)的高效图像生成的新方法,EBM是一种深度生成模型。以此为名。从名字上看是 "从粗到细",它通过将模型的训练从低分辨率平滑过渡到高分辨率来实现高效图像生成。
本文的流程如下。
- 什么是EBM?
- 建议的方法
- 实验结果
- 摘要
什么是基于能量的模型(EBM)?
EBM是一种深度生成模型,其目的是对数据分布$p(x)$进行建模。神经网络参数$theta$所代表的分布被表示为$p_{theta}(x)$,定义如下这里,$E_{theta}(x)$是一个将数据$x$作为输入并返回一个标量的函数,称为能量函数。
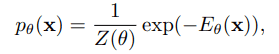
基本上,EBM的训练是为了最小化这个负的对数可能性$-log(p_{theta}(x))$。然而,分布函数$Z_{theta}$不能用分析法计算,因为它必须在所有$x$上进行积分,而且密度本身也不能确定。
使用神经网络训练EBM需要对负对数似然的参数进行梯度处理,计算方法是数据分布$p_{data}(x)$和模型分布$p_{theta}$的期望值之差,如下所示
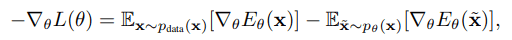
在上述方程中,从模型分布中取样很困难,通常使用MCMC。然而,众所周知,MCMC存在一些问题,如当$x$为高维时,收敛缓慢。
使用朗文蒙特卡洛方法,即哈密尔顿蒙特卡洛方法的一个变种,从模型分布中取样可按以下方式进行
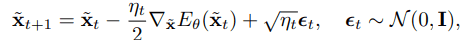
EBM仍然面临一些挑战,如训练的稳定性和生成数据的多样性。在下一节中,我们将介绍一种利用图像数据结构的特点来解决这些问题的方法。
粗到细的EBM (CF-EBM)
在EBM图像生成中,图像质量越高,能量函数的多模态性就越强,从模型分布中取样就越困难。另一方面,从以前的研究中可以知道,降采样的低维图像比高维图像变化更平稳。
这些结果表明,从低维图像中学习EBM更稳定,收敛更快。
Coase-To-Fine EBM逐渐向代表能量函数的神经网络添加层,从而将训练从低图像质量转移到高图像质量。
使用多分辨率图像的多阶段训练
当从低质量训练转向高质量训练时,我们使用由训练图像生成的多分辨率图像进行多步骤训练。让训练步骤的数量为$S$,每个步骤$s$的图像为$x^{(s)}$。$x^{(s-1)}$由$x^{(s)}$的均值集合生成,$x^{(0)}$代表最低分辨率图像,$x^{(S)}$代表训练图像。
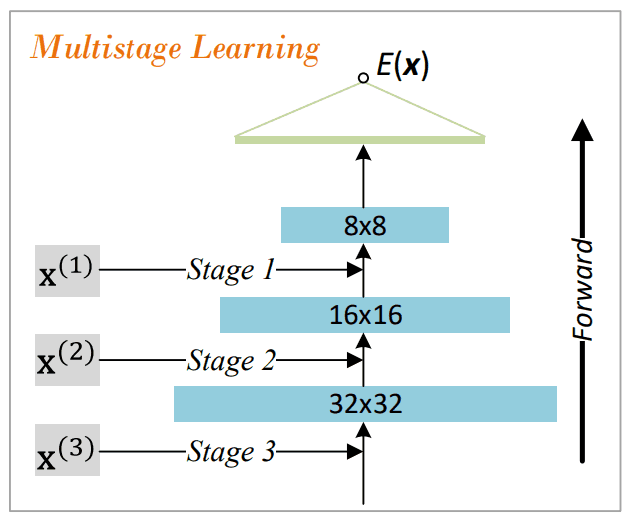
在步骤s中学到的能量函数$E^{(s)}$在进入下一步骤时,通过在底层增加一个随机初始化的层,转变为新的能量函数$E^{(s+1)}$。
稳定的学习
为了提高上述多阶段学习的稳定性,本文提出了架构和采样的两种方法。
平稳的架构变化
为了避免在向底层添加随机初始化的层时扰乱先前一步所学的能量函数,我们提出了一个平滑变化的架构修改。具体来说,我们定义了一个层(扩展块),计算两个神经网络的输出加权和,即Primal和Fade块,并将其添加到底层。
$Expand(x)=Primal(x) + (1 - \beta) Fade(x)$
从上式可以看出,通过逐渐将$\beta$从0移到1,我们可以实现逐渐关注最小特征的学习。
平滑的MCMC采样
当步骤从$s-1$移动到$s$时,在学习的早期阶段,对学习的主要贡献是由$E^{(s-1)}$和Fade块做出的。随着学习的进展和系数$\beta$1的接近,Primal块被强化训练。因此,随着训练的进行,MCMC采样反映了Primal块的梯度,导致更高分辨率的图像被采样。
此外,我们对前一个能量函数$E^{(s-1)}$中获得的样本用噪声初始化数据,以平滑训练过渡。
实验结果
在以下实验中对CF-EBM进行了评估:图像生成、图像修复、异常检测和领域转换。以下是对每个实验的详细描述。
图像生成
在CIFAR-10上训练的CF-EBM的性能评估如下表所示,使用深度生成模型如VAE和GAN,以Frechet Inception Distance(FID)作为评估指标。FID越小,指数越好。
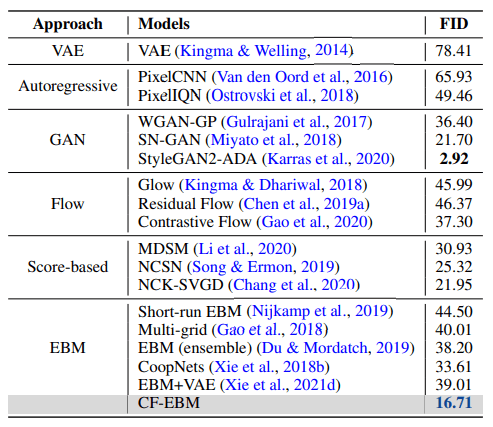
从表中可以看出,CF-EBM超过了大多数其他方法,并以很大的优势在EBM中记录了最好的性能。
使用CelebA作为数据集的结果如下表所示,与CIFAR-10的情况一样,评估是使用FID进行的。

同样,CF-EBM的表现超过了其他方法。然而,那些标有♰的图片是在一个经过调整的图片上测试的,中间切出了一个正方形。
图像修复
一旦学会了能量函数,它就可以被用于图像修复任务。在我们的论文中,我们进行了两项图像修复任务:去噪和空间完成。
在去噪方面,在CIFAR-10中随机选择的测试图像中加入白噪声,并通过Langevin动力学的采样来恢复图像。
此外,空白完成掩盖了每个图像的25%,并通过朗文动态采样对掩盖的区域进行图像修复。
下面的两个数字显示了这些结果。上面的是去噪的结果,下面的是空间完成的结果。


在这两个实验中,我们可以看到,重建的图像与原始图像有一些共同的一般特征,但在更多的细节特征上有所不同,如背景的颜色或眼镜的存在。这表明,经过训练的EBM不会记忆训练样本,但也能产生新的样本。
故障检测
异常检测是一个二元分类问题,解决了给定数据是正常还是异常的问题,以前的研究表明,EBM的可能性对异常检测很有用。
正常数据的能量函数的输出会很大,而异常数据的能量函数的输出会很小。
使用CIFAR-10训练了四种不同的深度生成模型,包括CF-EBM,使用SVHN、均匀分布、常数、图像之间的线性内插和CIFAR-100样本作为异常数据。结果显示在下面的表格中。AUROC被用来作为评价指标。
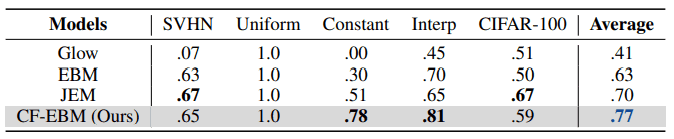
从上表可以看出,异常检测数据集的平均性能是最好的。还可以看出,CF-EBM在异常数据上表现良好,如图像之间的线性插值,很容易被误认为是正常的。此外,考虑到CF-EBM不使用标签,而JEM在训练期间使用图像标签,CF-EBM的性能与CIFAR-100相比并不差。
域名转换
图像域转换是指在保留图像内容(如其所包含的物体)的同时,转换图像的风格,如颜色和纹理。
使用EBM的域转换是通过用源域图像初始化朗文动态采样并生成目标域图像来进行的。目标域图像是通过对源域图像进行初始化采样产生的。
传统的方法,如CycleGAN,在学习双向领域转换和从源头到目标以及从目标到源头的转换时,考虑到返回原始图像的约束的损失(循环一致性)。然而,基于EBM的领域转换并不要求这种周期一致性。
下图显示了在三个不同的数据集上进行领域转换的结果:橘子-苹果、猫-狗和照片-Vangogh。可以看出,这种方法产生的图像比其他方法更详细。

总结
你怎么看?在本文中,我们表明,在MCMC中对高维数据进行抽样,这是训练EBM的挑战之一,通过"从低分辨率到高分辨率的逐步抽样",可以使效率更高。同样有趣的是,当使用EBM对图像进行域转换时,不需要循环一致性。
我们希望EBM的应用在未来能得到扩展。如果你有兴趣,我敦促你阅读原始的论文!



与本文相关的类别
