
批量归一化中的Affine参数在Few-Shot学习中可能是有害的!
三个要点
✔️ 批量正则化中的Affine参数在一般的少数过渡学习中是不利的。
✔️建议用去掉仿生参数的特征正则化代替批量正则化
✔️证明特征归一化在具有大领域转移的少许镜头过渡学习中是有效的。
Revisiting Learnable Affines for Batch Norm in Few-Shot Transfer Learning
written by Moslem Yazdanpanah, Aamer Abdul Rahman, Muawiz Chaudhary, Christian Desrosiers, Mohammad Havaei, Eugene Belilovsky, Samira Ebrahimi Kahou
Comments: CVPR2022.
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
批量归一化,经常用于卷积神经网络,包括每个通道的归一化步骤和特征移位缩放,具有可学习的仿生参数$gamma,\beta$,现在是在计算机视觉模型中至关重要。
然而,本文提出的论文显示,在Few-shot学习中,具有仿生参数的特征移动缩放处理可能是有害的。特别是,在具有较大领域转移的Few-shot学习的情况下,发现通过去除仿生参数处理,可以获得更高的性能。
关于特征归一化
如前所述,批量归一化(BN)过程包括每个通道的归一化步骤和具有可学习的仿生参数$gamma,\beta$的特征移位缩放。
在实验中,当BN层仅被每个通道的归一化步骤所取代时,为了研究因仿生参数而产生的移位缩放的影响,对Few-shot学习进行了研究。在本文中,我们把这种按通道归一化的步骤称为特征归一化(FN)。
特征归一化(FN)的定义
首先,域$textit(D)$是特征空间$textit(X)$和周围的概率分布$P(X)$(其中$X={x_1,}。,x_n\} in \textit(X)$)。
让$S$表示由$N$标记的例子组成的批次,${(x^s_i,y^s_i)\}^N_{i=1}$从源域$textit(D)^s$获得。另外,对于$L$层,将$l$层权重矩阵为$Theta^l$的深度卷积神经网络表示为$Theta$。
如果$$Theta$的第l$个中间特征是$h$,那么$l$个特征归一化层对$c$个通道的定义如下。
$FN(h_c) = frac{h_c - \mu_c}{sqrt{sigma_{c^2} + epsilon}}$
其中$mu_c,sigma_c$分别是$h_c$的一阶和二阶矩,定义为
$mu_c = frac{1}{NHW}\sum_{n,h,w}h_{nchw}$
$sigma_c = sqrt{\frac{1}{NHW}\sum_{n,h,w}(h_{nchw} - \mu_c)^2}$
其中$H,W$是$h_c$的空间维度。
微调仿生学(Fine-Affine)
在少数次学习设置中,通常只有线性分类器在微调期间被拟合,骨干权重被冻结。这不仅是为了加快微调的速度,也是因为微调骨干并不能提高性能(容易出现过度拟合)。
另一方面,Affine参数有较少的参数,在Few-shot学习设置中,可能能够拟合模型而不会过度拟合。因此,在实验中,我们还引入了一个设定,即线性层和仿生参数都被联合拟合。(在论文中,这被称为Fine-Affine)。
实验装置
在实验中,将研究把FNs应用于最先进的几率学习框架的有效性,如STARTUP。我们还将研究用FN代替BN是否能提高AdaBN的性能,AdaBN是一种基于BN的领域适应技术,当它应用于少数次学习时。
基准
CDFSL
实验使用了具有挑战性的CDFSL基准。作为源数据集,在由物体识别任务组成的miniImageNet或ImageNet上进行了实验。
目标数据集由四个数据集组成,它们来自与这些源数据集完全不同的领域(有较大的领域转移)。
- EuroSAT(卫星图像)。
- CropDiseases(植物图像)。
- ChestX(胸部X光图像)
- ISIC 2018(皮肤病变成像)。
在实验中,下游任务是在有5个类别的5-way k-shot设置中进行过渡学习,每个类别有k个样本。
META-DATASET.
它还以ImageNet为基础,在META-DATASET上进行实验。
目标数据集包括。
- 全能型
- 飞机
- 鸟类。
- VGG花
- 快速拉动
- 真菌
- 纹理。
- 交通标志。
- MSCOCO
这个数据集的一个特点是,除了源和目标之间的领域转移外,该任务不遵循常见的K-way N-Shot设置。
实验结果
跨域的几率过渡学习。
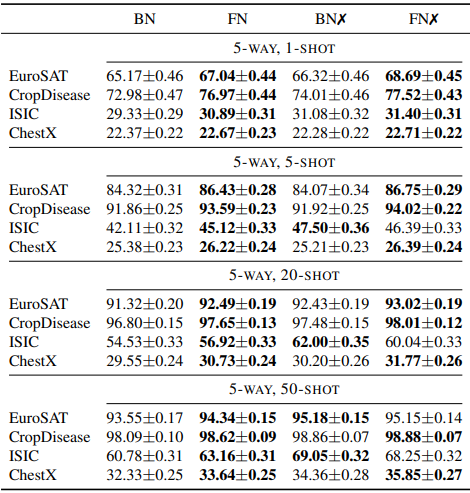
首先,在CDFSL基准上对FN和BN进行了比较。架构上使用了ResNet10。结果如下。
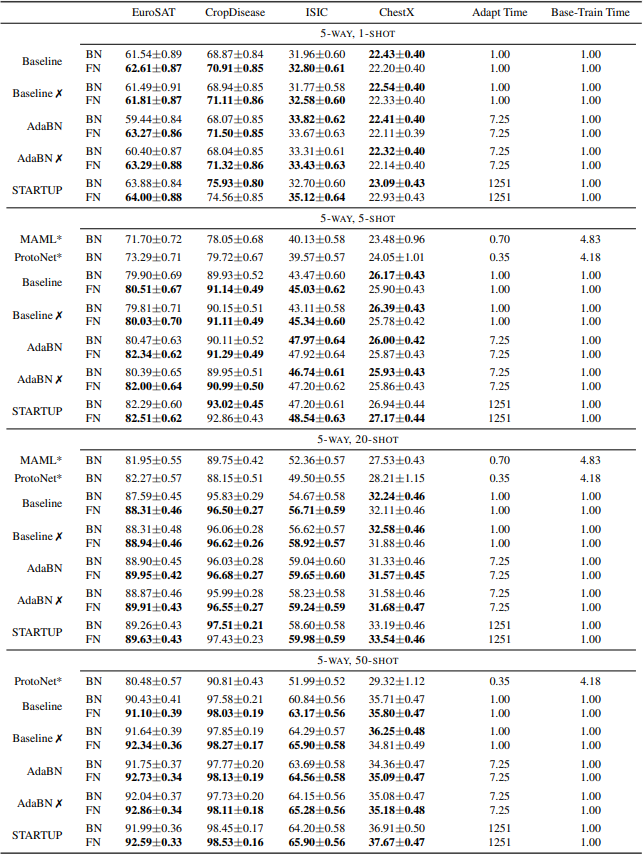
基线是标准的过渡学习设置。✗标记显示的是Fine-Affine设置的结果,它同时适合线性层和仿生参数。总的来说,可以看出,使用FN的模型的平均性能优于BN模型。使用META-DATASET的结果也显示如下。
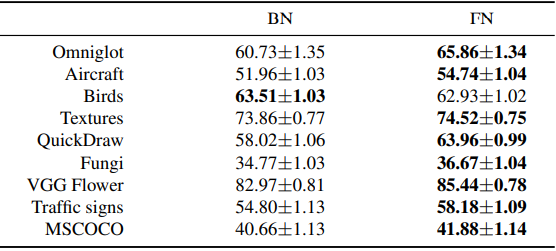
与CDFSL一样,FN模型在大多数情况下的表现优于BN模型。这些结果表明,对于发生领域转移的几率很小的过渡学习,由BN的仿生参数处理对性能有负面影响。
相邻领域之间的少许过渡学习。
接下来,研究了与CDFSL相比较小的域移的结果。该实验使用miniImageNet作为源,ImageNet作为目标。结果如下。
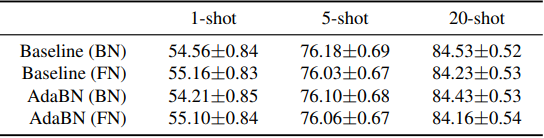
结果显示,FN的表现并不明显优于BN,当发生大的领域转移时,FN更有效。这也可以从下图中读出,该图评估了在ImageNet上训练时对验证数据的表现。
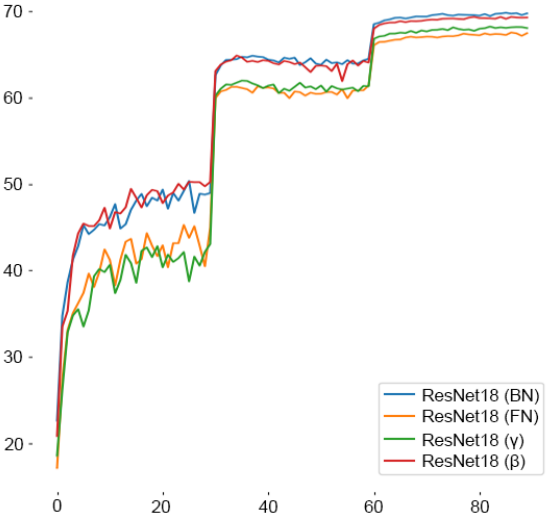
该图显示,在评估该领域的表现时,BNs比FNs表现得更好。
精细-阿芬设置
对线性分类器和仿生参数进行微调的结果也显示如下。
✗标记表示Fine-Affine设置,其中FN在基础学习阶段被训练,$\gamma,\beta$分别被初始化为1和0,并在过渡学习期间引入。总的来说,我们发现在这种情况下,BN和FN的性能都有所提高,但FN模型的表现仍然优于BN模型。
消融研究
BN层由两个可学习的仿生参数组成,当这两个($\gamma,\beta$)参数分别被移除时,结果如下。
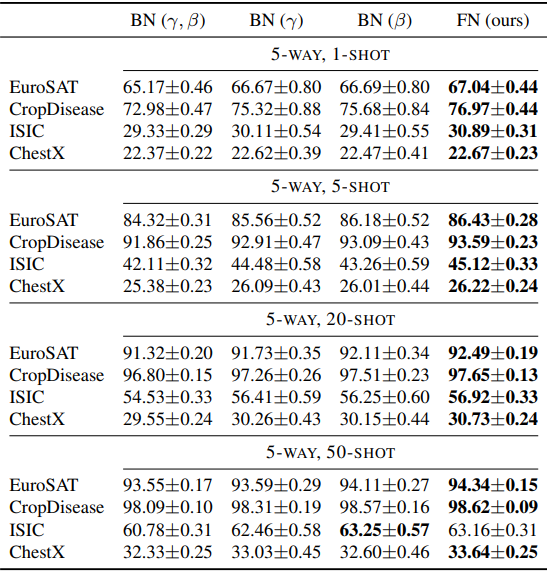
一般来说,去掉两个参数之一的$BN(\gamma),BN(\beta)$的性能优于常规BN,去掉两个参数的FN表现最好。
分析FN和BN之间的差异。
最后,对造成这种结果差异的原因进行了分析。首先,下面是FN层和BN层的输入和输出特征在大领域转移中的分布图。
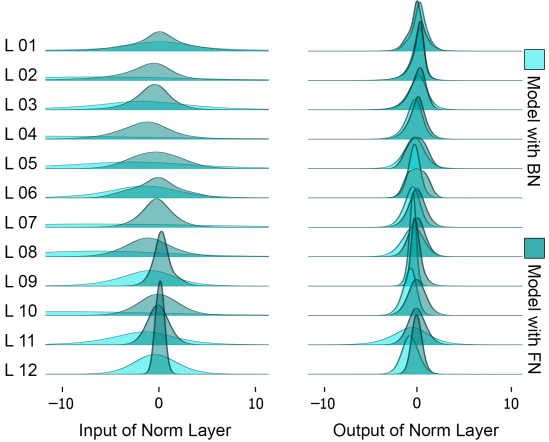
如图所示,与BNs相比,FNs的输入更加中心化,输出分布也相对相似,还有其他结果。本文还假设,领域转移下的BN仿生参数问题与ReLU的稀疏化特性有关。
为了研究这个假设,下面将介绍源数据和目标数据的稀疏性比较。
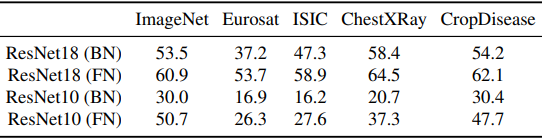
一般来说,使用FNs可以抑制源数据和目标数据的稀疏性损失。这一结果表明,由于ReLU阈值特性导致的分布变化可以通过使用FNs而不是BNs来抑制信息损失。
摘要
批量归一化是一种应用于各种情况的方法,但人们发现,在领域偏移较大的少数过渡学习情况下,仿生参数有负面作用。所提出的特征归一化是一种去除仿生参数处理的归一化方法,已被证明是解决这一问题的有效方法。



与本文相关的类别
