测试精度可以从GAN样本中推断出来!
三个要点
✔️ 尝试使用GANs的合成数据集预测测试准确性
✔️ 证明了超越一系列现有方法的结果
✔️ 确定了GANs的有趣特性,如其生成分布更接近测试集而不是训练集
On Predicting Generalization using GANs
written by Yi Zhang, Arushi Gupta, Nikunj Saunshi, Sanjeev Arora
(Submitted on 28 Nov 2021 (v1), last revised 17 Mar 2022 (this version, v2))
Comments: ICLR2022
Subjects: Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
仅仅从训练数据集和网络中预测测试错误是深度学习的一个重大挑战。
本文提出的论文通过使用在同一训练数据集上训练的生成对抗网络(GAN)产生的合成数据来解决这个问题。
结果表明,与众所周知的GANs的局限性(如模式崩溃)相反,通过GANs来预测测试错误的尝试是成功的。
用GAN样本进行测试性能预测。
本文尝试用GAN生成的合成数据来预测测试性能。这里,由GAN生成的训练集、测试集和合成数据集分别表示为$S_{train},S_{test},S_{syn}$。
给定一个在训练集$S_{train}$上训练的分类器$f$,在测试集$S_{test}$上的分类精度$g(f) := frac{1}{|S_{test}|}\sum_{(x,y) \in S_{test}}1[f(x)=y]$。目标是预测。
本文的尝试很简单:为了实现这一目标,通过在$S_{train}$上训练的条件GAN模型创建了一个标记的合成数据集$S_{syn}$。然后,$S_{syn}$中$f$的分类精度$what{g}(f)$被作为测试精度的预测指标。
整个伪算法如下。

这里,来自StudioGAN库的预训练BigGAN+DiffAug被用作GAN,VGG-(11,13,19)、ResNet-(18,34,50)和DenseNet-(121,169)作为分类器,而CIFAR-10和Tiny用ImageNet进行这一尝试的结果如下图所示。
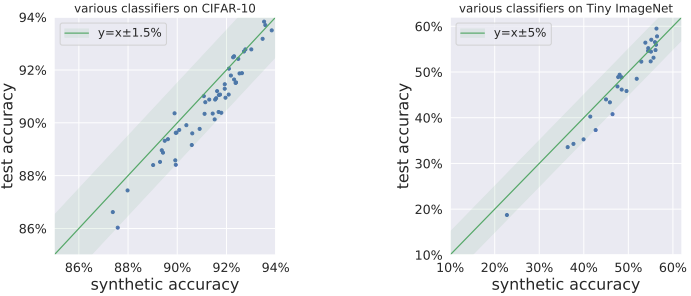
如图所示,对于这两个数据集,合成数据的准确率始终位于所使用的各种分类器的测试准确率附近,并被发现作为一个良好的预测器。
PGDL竞赛中的评估
然后对NeurIPS 2020竞赛中关于预测深度学习泛化的任务进行了类似的尝试。
然而,由于这项任务的目标是预测泛化差距,而不是测试准确度,上述算法1已经做了相应的修改。其他实验设置(如使用的GANs)与之前相同。结果如下。
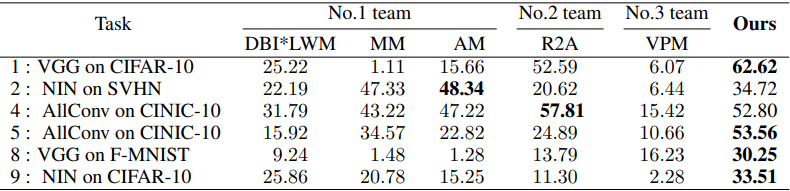
这里,除了GANs没有被成功训练的任务外,其他任务的结果都被展示出来。
总的来说,所提出的方法明显优于前三个团队。应该注意的是,没有对所有任务进行超参数搜索,所以额外的调整可以进一步提高性能。
DEMOGEN BENCHMARK中的评价
深度模型概括基准(DEMOGEN)的结果如下
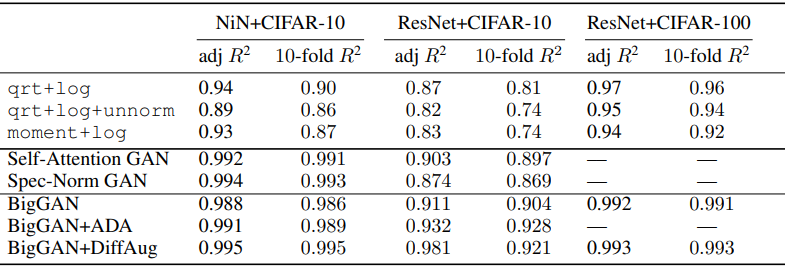
该表显示了使用各种GAN模型时获得的结果。总的来说,使用GANs的预测显示出非常好的结果。
GAN样本和测试集的相似度。
为了分析为什么GAN样本在预测测试准确性方面表现出良好的特性,我们研究了GAN产生的合成数据和测试集之间的相似性。为此,数据集之间的相似性是由一个名为 "类条件Frechet距离 "的指数来衡量的。
这里,对于一个给定的特征提取器$h$,两个集合$S,/tilde{S}$之间的距离由以下公式给出
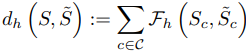
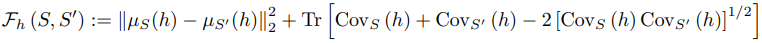
该定义的细节在原始文件中给出。根据这个指标衡量的合成数据集、训练集和测试集的分布之间的距离关系如下。
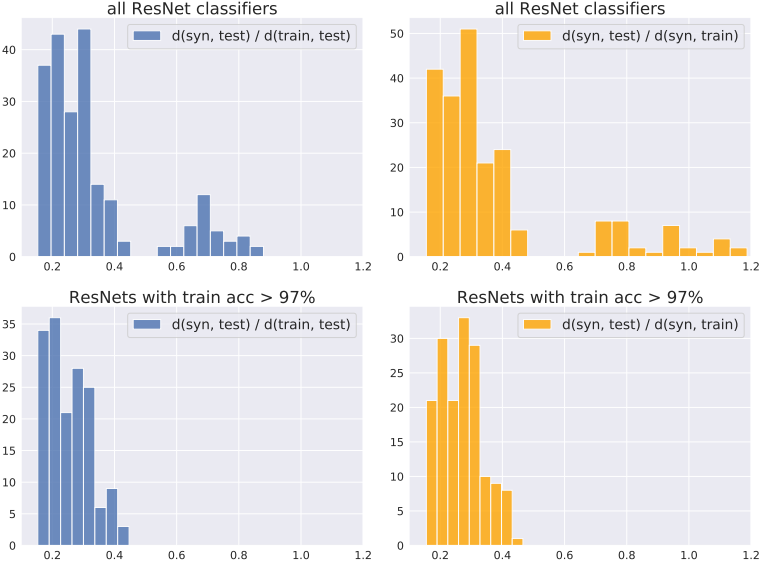
这里,图的上半部分显示了当包括准确率低的分类器时,分布之间的距离比率,而下半部分显示了当只有显示准确率为97%以上的分类器被用作特征提取器时,分布之间的距离比率。一般来说,存在$d_h(S_{syn}, S_{test})< d_h(S_{syn}, S_{train})$的趋势,特别是在使用表现良好的分类器时。
这表明,合成数据集比训练集更接近测试集。考虑到GANs的训练是为了提高$S_{syn}$和$S_{train}$之间的相似度,这个结果相当令人惊讶。
为了进一步验证这一结果,在GAN模型中使用不同模型作为分类器而不是Discriminator的情况下,同样的分布间距离结果如下。
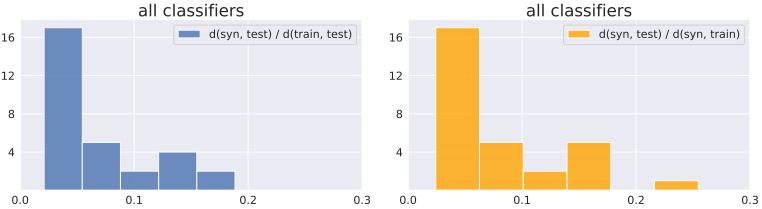
在这种情况下得到了类似的结果,再次显示了合成数据集比训练集更接近测试集的现象。
数据扩增的有效性。
最后,训练GANs时和训练分类器时,有无数据增强的测试和合成数据准确性的图示如下。
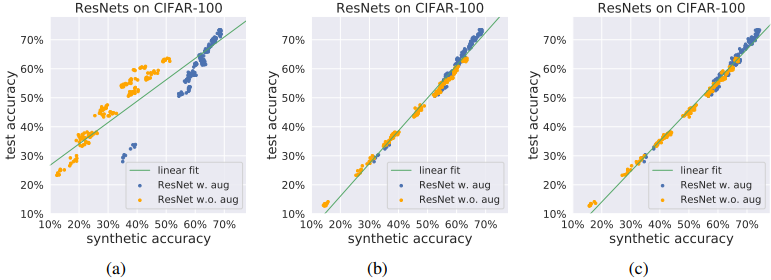
图(a)显示了只对真实图像样本应用增强训练的GAN的结果,(b)没有增强和(c)有可区分增强。此外,如果在训练分类器时有数据增量,则将这些点绘制成蓝色,如果没有增量,则绘制成橙色。总的来说,结果显示,数据增强并不总是有利于概括预测。
当对真实和虚假图像都进行微分增强,并在不操纵目标分布的情况下对判别器进行正则化时,可能会获得最佳结果。
摘要
在这篇文章中,我们描述了针对使用GANs生成的合成数据进行泛化预测的新兴想法的研究,并获得了有用的结果。一般来说,已经得到了令人惊讶的反直觉的结果,例如GAN生成的分布比训练集更接近测试集。
这是一项有趣的研究,可以成为进一步研究的催化剂,包括通过新的理论进行理解。



与本文相关的类别






