
通过结合扩散模型生成合成图像。
三个要点
✔️ 提出了一种使用扩散模型生成合成图像的方法。
✔️ 通过将扩散模型视为一个基于能量的模型,它可以使用逻辑产物和否定句在不同的领域进行组合。
✔️ 在多个数据集上进行了实验,结果在数量上和质量上都超过了基线模型。
Compositional Visual Generation with Composable Diffusion Models
written by Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, Joshua B. Tenenbaum
(Submitted on 3 Jun 2022 (v1), last revised 17 Jan 2023 (this version, v6))
Comments: ECCV 2022. First three authors contributed equally.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
语言输入的扩散模型,如DALLE-2,可以从自然语言句子中生成非常精细的图像,但它们在理解物体之间的关系等概念的组合方面存在不足。因此,本文提出了一种结合扩散模型来生成合成图像的方法。
技术
通过扩散建模降低噪音。
去噪扩散概率模型(DDPMs)是一种去除噪声的生成模型。如果输出图像${\bf x}_0$是由高斯分布产生的噪声${\bf x}_T$以$T$步骤生成的,那么噪声乘法的正向过程$q({\bf x}_t|{\bf x}_{t-1})$和去噪的反向过程$p({\bf x}_{t-1}|{\bf x}_{t})$是如下的。
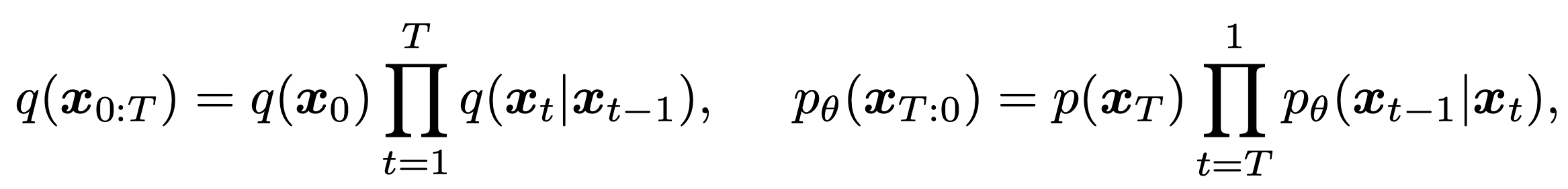
其中$q({\bf x}_0)$是真实数据分布,$p({\bf x}_T)$是正态高斯分布。生成过程$p_{\theta}({\bf x}_{t-1}|{\bf x}_t)$学习近似反向过程,以产生真实图像。每个生成过程都会学习均值和方差参数,表示如下。
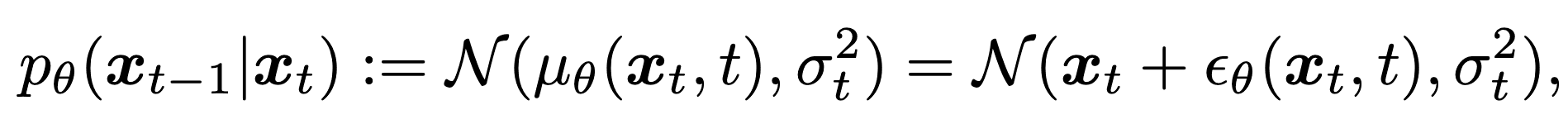
也就是说,${\bf x}_{t-1}$是噪声${\bf x}_t$加上扰动项${\epsilon}_{\theta}({\bf x}_t,t)$的平均值$\mu_\theta({\bf x}_t, t)$和方差${\sigma}_t$。它的参数化和表达方式如下。
基于能源的模式
基于能量的模型(EBM)是一种生成模型,其中${\bf x}\in {\mathbb R}^D$是由一个归一化的概率密度表示的,例如
$$p_\theta({\bf x})\propto e^{-E_\theta({\bf x})}$$
其中$E_\theta({\bf x})$是一个神经网络。在基于梯度的MCMC过程中,生成的图像使用Langevin动力学进行细化,如下所示。
$${\bf x}_t={\bf x}_{t-1}-\frac{\lambda}{2}\nabla_{\bf x}E_\theta({\bf x}_{t-1})+{\mathcal N}(0,\sigma^2)$$
将上述方程与扩散模型中的生成过程的方程相比较,可以看出它们在数学上是相似的。
扩散模型是基于能量的模型。
如上所述,扩散模型学习了一个降噪网络$\epsilon_\theta({\bf x}_t,t)$来生成图像,而EBM是通过能量梯度$\nabla_{\bf x}E_\theta({\bf x}_t)\propto \nabla_{\bf x}\log p_\theta(\bf x)$产生。由于这两个项都是由于数据分布的分数造成的,它们可以被看作是数学上的等价物。因此,EBM可以结合起来并应用于扩散模型。
现在,给定$n$个独立的EBM $E^1_\theta({\bf x}),\cdots ,E^n_\theta({\bf x})$,这些可以合并得到一个新的EBM如下。
$$p_{compose}({\bf x})\propto p_{\theta}^1({\bf x})\cdots p_\theta^n({\bf x})\propto e^{-\Sigma_iE_\theta^i({\bf x})}=e^{-E_\theta({\bf x})}$$
其中$p_\theta^i$は${\bf x}$的概率密度。生成的图像如下。
$${\bf x}_t={\bf x}_{t-1}-\frac{\lambda}{2}\nabla_{\bf x}\Sigma_iE_\theta^i({\bf x}_{t-1})+{\mathcal N}(0,\sigma^2)$$
以类似的方式,扩散模型中的生成过程可以表示为:
$$p_{compose}({\bf x}_{t-1}|{\bf x}_t)=\mathcal N({\bf x}_t+\Sigma_i \epsilon^i_\theta({\bf x}_t,t),\sigma_t^2)$$
扩散模型可以通过将$\epsilon_\theta({\bf x},t)$参数化为EBM的梯度来结合。
合成图像的生成
为了生成一个复合图像,具有独立概念的扩散模型${\bf c}_i$被组合起来。使用的运算符是逻辑连接(AND)和否定(NOT)。
和
$$p({\bf x}|{\bf c}_1,\cdots ,{\bf c}_n)\propto p({\bf x},{\bf c}_1,\cdots ,{\bf c}_n)=p({\bf x})\Pi_i p({\bf c}_i|{\bf x})=p({\bf x})\Pi_i\frac{p({\bf x}|{\bf c}_i)}{p({\bf x})}$$
将上面得到的生成过程的公式代入,我们得到以下公式。
$$p^*({\bf x}_{t-1}|{\bf x}_t):=\mathcal N({\bf x}_t+\epsilon^*({\bf x}_t,t),\sigma_t^2),$$
$$\epsilon^*({\bf x}_t,t)=\epsilon_\theta({\bf x}_t,t)+\alpha \Sigma_i(\epsilon_\theta({\bf x}_t,t|{\bf c}_i)-\epsilon_\theta({\bf x}_t,t))$$
其中$\alpha$是温度参数。
不
你想否定的概念为$\tilde{{\bf c}}_j$。
$$p({\bf x}|not\ \tilde{{\bf c}_j},{\bf c_1},\cdots ,{\bf c}_n)\propto p({\bf x}, not\ \tilde{{\bf c}_j},{\bf c}_1,\cdots, {\bf c}_n)=p({\bf x})\frac{\Pi_i p({\bf c}_i|{\bf x})}{p(\tilde{{\bf c}_j}|{\bf x})^\beta}=p({\bf x})\frac{p({\bf x})^\beta}{p({\bf x}|\tilde{{\bf c}_j})^\beta}\Pi_i\frac{p({\bf x}|{\bf c}_i)}{p({\bf x})}$$
$$\epsilon^*({\bf x}_t,t)=\epsilon_\theta({\bf x}_t,t)+\alpha\{-\beta(\epsilon_\theta({\bf x}_t,t|\tilde{\bf c}_j)-\epsilon_\theta({\bf x}_t,t))+\Sigma_i(\epsilon_\theta({\bf x}_t,t|{\bf c}_i)-\epsilon_\theta({\bf x}_t,t))\}$$
其中,$\alpha,\beta$是温度参数。
结果
用这种方法和基线模型为不同领域的数据集生成了图像并进行了评估。
自然语言绑定
我们比较了使用训练好的GLIDE模型生成自然语言句子组合的结果。可以看出,该方法生成的图像更加准确,如第一张 "北极熊 "和第三张 "bangalows"。

物体关联
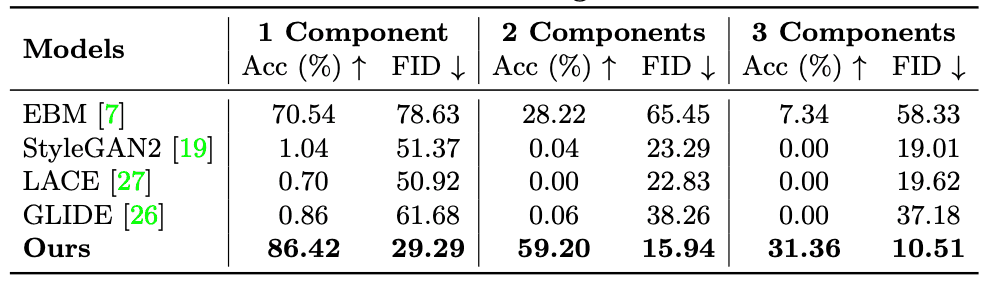
该图像是由物体的二维位置生成的。从下图可以看出,该方法也能正确生成基线模型中的失误。下表还显示,Acc和FID都有明显的更新。

客体关系
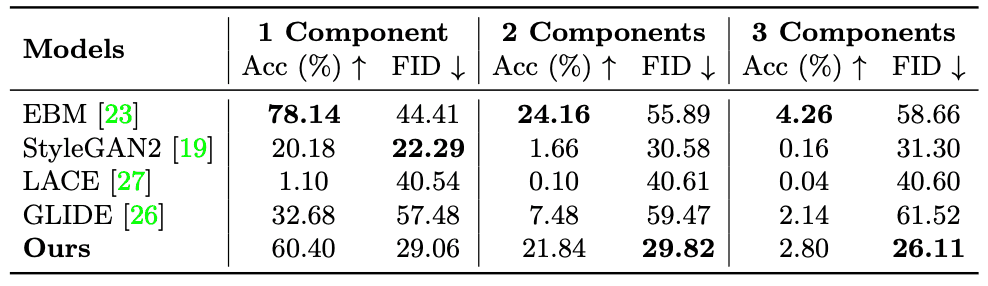
这些图像是由描述物体间位置关系的句子生成的。下图显示,EBM和这种方法的再现效果很好。下表还显示,这种方法的Acc比不包括EBM的模型要高得多,同时保持了较低的FID,而EBM的FID则更高。

摘要
在本文中,图像是通过结合扩散模型生成的。结果表明,通过将扩散模型看作是一个基于能量的模型,结合复杂概念的图像可以成功地生成,而且精度很高。一个局限性是,结合在不同数据集上训练的扩散模型可能会失败,这可以通过更好地实现EBM结构来改善。



与本文相关的类别






![OmniGen] 只需一个生成模型就能完](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2024/omnigen-520x300.png)