使用G-buffers和渲染管线生成逼真的图像!
三个要点
✔️ 使用G-buffers和渲染管线生成逼真的图像
✔️ 分析导致布局坍塌的工件发生情况
✔️ GTA V场景成功过渡到逼真的场景
Enhancing Photorealism Enhancement
written by Stephan R. Richter, Hassan Abu AlHaija, Vladlen Koltun
(Submitted on 10 May 2021)
Comments: Accepted by arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR); Machine Learning (cs.LG)
code:

研究概要
这项研究的重点是合成图像(在计算机上代表真实世界的图像)的真实性。重点主要是使游戏世界看起来像真实世界,研究将提出的方法应用于《侠盗猎车手5》,以生成一个现实的游戏世界为例。
传统的方法是使用渲染技术改进卷积网络,以获得中间层的表示,然后在这个网络上使用最新的对抗性目标函数,学习实现多个感知层面的超级分辨率。以实现多个感知层面的超分辨率。
然而,在以前的研究中,这很难控制,会产生各种假象(生成的图像中的假象或杂质),导致假象的出现。因此,在本研究中,我们提出了一种在训练过程中对图像斑块进行采样的方法,以及深度网络的多层结构,并成功地提高了真实性,产生了稳定的图像。
综合性的照相写实方法的建议
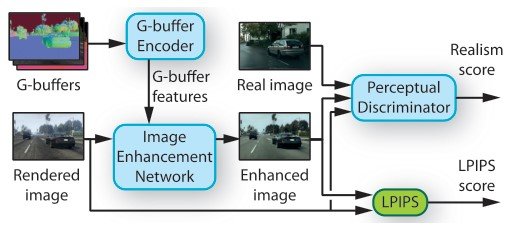
拟议方法的概要
建议的方法由三个网络组成。1)图像增强网络,(2)中间层的渲染缓冲区(G-buffers),以及(3)感知辨别器。最后,我们对数据集进行分析,以防止在对抗性训练过程中由人工制品引起的布局崩溃。
图像增强网络
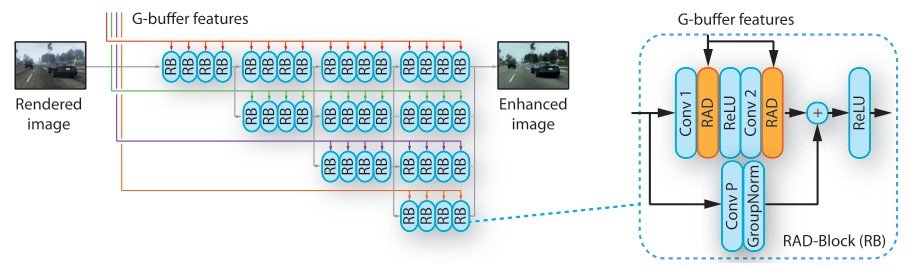
图像增强网络以HRNetV2为基础,擅长预测任务。 它将渲染过的图像和G-buffer特征(稍后描述)作为输入,输出真实的图像。输入的G-缓冲区被分为不同的分辨率,HRNet通过处理这些不同分辨率的多个分支来并行处理图像。图片中的颜色对应于不同的分辨率)。
在这项研究中,我们以两种方式改进HRNet。
- 第一个分叉卷积被常规卷积所取代,以处理全分辨率并保留图像细节。
- 在残余区块中,批量规范化层被渲染感知的去规范化(RAD)模块所取代
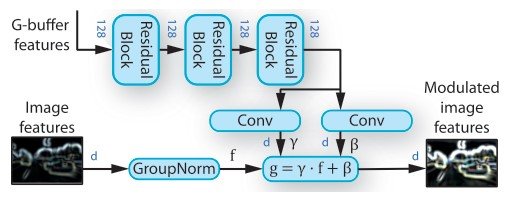
渲染感知的去规范化(RAD)。渲染感知的去规范化(RAD)。
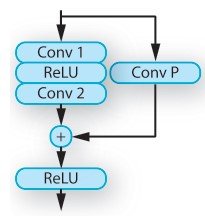
RAD是一个负责根据外部信息调整特征向量的模块。特别是,它是一个从场景表征中学习权重的模块,并使用两个住宅区块对从G-buffer编码器网络获得的特征向量进行转换。住宅区块用于G-buffer编码器和RAD,由卷积层、光谱诺拉化和ReLU组成。它由卷积层、光谱诺拉化和ReLU组成。
变换后的特征被用来学习元素比例$gamma$和移动权重$beta$。正如你在下图中看到的,权重代表了归一化图像特征的仿生变换的参数。($g = \gamma \dot f + \beta$) 其中,输入的外部信息是通过渲染得到的图像的地理、物体、光线和语义信息的特征向量。对于每个RAD模块,我们使用三个住宅区对G-缓冲区的特征向量进行转换。
目标函数
图像增强网络是用两个目标函数训练的。
- 使用LPIPS损失对输入和输出图像之间的结构差异进行处理(LPIPS得分
- 感知判别器评估输出图像的真实性(真实性得分)。
与传统方法相比,我们在真实和合成图像斑块中使用了一种特定的采样技术,以减少学习时的显著伪影数量。
渲染管线
实时渲染通常在渲染过程中加入了多个通道。G-buffers的一个特点是,它们可以学习理解语义信息,而不需要被赋予这种信息([S. R. Richter等人。G-buffers能够在不提供语义信息的情况下学习理解语义信息([S. R. Richter et al., A. Shafaei et al. ] ),通过捕捉地理和物体特征并将其输入网络,可以更准确地进行从伪图像到真实图像的转换。
提取G型缓冲区
这项研究的目标是获得《侠盗猎车手5》游戏中的G-buffers。我们使用了从计算机游戏中提取渲染资源的技术([S. R. Richter et al, S. R. Richer et al., P. Kr¨ahenb ¨uhl]),并提取带有地理结构(表示法、深度)、物体(着色器ID、反射率、透明度)、亮度(近似亮度和发射率)等信息的G型缓冲区。,天空),以及其他信息性的G型缓冲区被提取出来。

此外,从G-缓冲区
- 使用物体表面的视点向量逐个检查像素的反射,并提取反射向量
- 计算曲面和这个反射矢量的点积
我是。
结果可以在正文的第4.4节(G-buffers有帮助吗?)中看到,如果没有G-buffers的信息,低维特征的计算是粗糙的,而加入G-buffers后,VIPER数据集中所有维度的特征都可以再现真实的场景。在VIPER数据集中。
在 "如何摄取G-buffers?"的实验中,简单添加G-buffers(concat)的结果是比使用SPADE模块([14])而不是RAD模块的网络有更好的整体性能。用SPADE模块而不是RAD模块连接网络。此外,使用SPADE模块的网络在数据集上产生的结果变化很大,有些是现实的,有些是完全失败的。另一方面,使用RAD模块的拟议方法始终产生高度准确的结果。

G-buffers 编码器
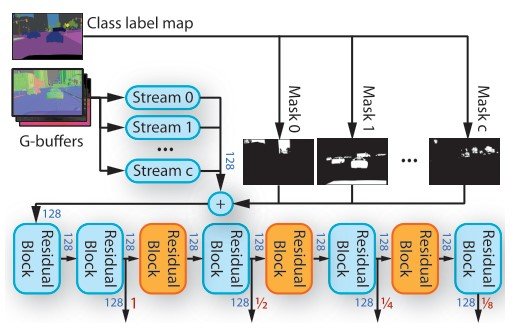
G-buffers提取材料信息、深度图像、正常图像、彩色图像中的连续深度值,以及树木和天空等稀疏的连续信息。为了处理G型缓冲区的每个信息,我们使用一个G型缓冲区编码器,如上图所示。G-buffers编码器有多个网络流,每个流由两个剩余块组成(图8)。由于这种剩余区块的机制,我们可以进行多尺度的训练。
设$f_c$为对象类$c$为目标时流的特征张量,$m_c$表示为对象的掩码。然后对该对象进行遮蔽。($Sigma_c m_c \cdot f_c$)
一个物体的ID与来自语义分割图的多个类别标签进行分组。这使得G-buffers能够将对象类型映射到流中。输出的特征张量通过RAD模块被图像增强网络输入。
知觉辨别器
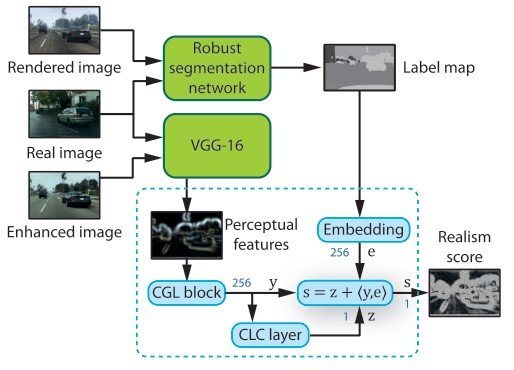
在训练图像增强网络的同时,输出图像的真实性由一个感知判别器来评估。这个判别器由一个强大的语义分割网络(MSeg)、一个知觉特征提取网络(VGG-16)和多个判别器网络组成。
这个分割网络被应用于目标数据集和未被改变的渲染图像。这使我们获得了真实和合成图像的语义信息。请注意,如果我们在合成图像上进行训练,我们将失去对现实数据的通用性。另外,我们没有对分割网络使用反向传播,因为它对生成真实图像没有必要。
通过将VGG应用于真实的、高精度的图像,我们可以获得每个维度的抽象信息的感知特征,并根据感知水平来应用网络。
分析由人工制品引起的布局变化
在对抗性设置中,鉴别器将图像标记为真实或虚假,以便在训练中识别它们。然后,它在这个梯度上进行反向传播,增加噪音,以便生成器能够产生更真实的图像。
在这里,如果人脸和真实图像可以用假的特征来识别,例如,如果更多假的GTA V空图像被训练,并且在Cityscapes数据集中的相同像素位置有一棵树,那么在GTA V的空位置就会生成一棵树。

从上面的概率深度图可以看出,数据集是用均匀分布来训练的,所以如果采样地点的信息不同,生成的信息也会不同。

对应补丁的取样
上述分析表明,在GTA和Cityscapes中随机取样图像的结果是与预期不同的布局,即使获得相同的对象信息。
因此,我们在此提出一种不同的抽样技术。首先,我们尝试只裁剪总显示图像的7%。第二,我们调整采样的斑块,使判别器所显示的物体分布稳定。计算的方式是,如果裁剪的补丁的像素和VGG16提取的特征张量的余弦相似度高于0.5,则两个补丁是匹配的。(更多细节,请参考论文)
鉴别器是PatchGAN的那个。(哪个判别器?)上述的投影层在较高维度上的准确性较低,而自适应反向传播在最高维度上的准确性较高。

实验
在我们的实验中,我们使用内核感知距离(KID) 来评估真实性,它测量语义结构之间的距离,但并不直接测量真实性,而且可能忽略渲染图像中的信息。这就是为什么我们使用概念网络。因此,我们提出了一种方法,用VGG的不同层的特征来替代入网得到的特征。(最大平均差异的平方(MMD))这使我们可以考虑感知图像的质量。([Q. Chen, R. Zhang])
为了使数据集之间用于获取特征的斑块分布一致,我们从每个数据集的语义标签图中提取1/8的图像大小的斑块,并进一步降样。然后,合成数据集(在这种情况下,GTA V)中的向量在真实数据集中使用最近的邻居搜索配对的斑块。这就产生了补丁的以下语义对应关系。

与以往研究的比较
在这一节中,我们提供了与以前的研究在逼真度上的比较:对于需要语义分割标签作为输入的方法,我们使用MSeg[72]提出的合成图像和真实图像,并提出了我们使用了一个类似的鲁棒性分割网络作为鉴别器。
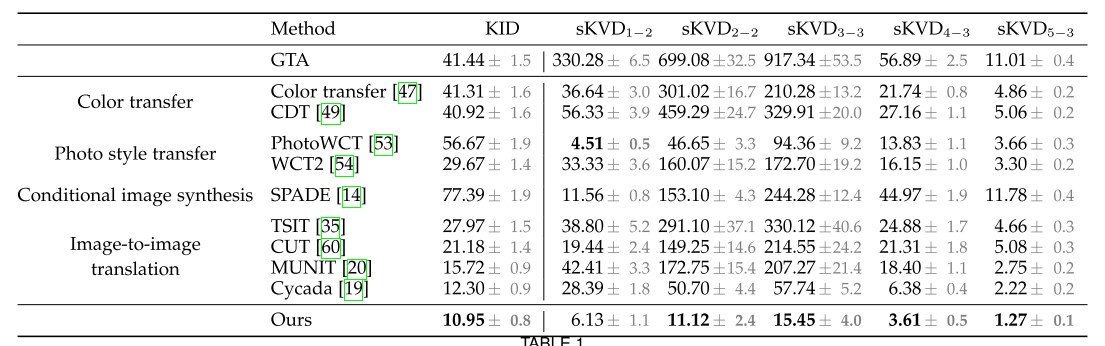
我们看一下表1中的结果。作为一个比较的实验,
- 颜色转换器(它能很好地生成颜色吗?
- 照片风格转移(图像风格是否成功生成)。
- 有条件的图像合成(在某些条件下,图像是否能被重现
- 图像到图像的翻译(图像是否可以在另一个领域生成)。
我们正在做四件事
颜色转移是与颜色转移(Color Transfer)和颜色分布转移(CDT)相比较。这些方法限制了像素的颜色,使其难以提高纹理的表现力,并造成假象(见下图)。因此,我们看到低维特征的评估有了更大的改进。

照片风格转换与快速照片风格转换(PhotoWCT)和当前SoTA小波变换(WCT2)的闭合形式(存在解决方案的方程)解决方案进行了比较。每种方法都需要一个风格图像和一个针对源图像和风格图像的语义分割图;与颜色转移不同的部分是,它不转化像素颜色,而是转化学到的高维从语义分割中得到的特征空间。因此,这种转变比色彩转移更有力。
然而,照片风格转移依赖于风格图像与输入图像的匹配。因此,当输入图像发生变化时,照片风格转移可以通过交互式学习合成环境而产生不真实的颜色过渡和暂时不稳定的图像。
条件性图像合成与最强大的SPADE进行了比较。我们在准备好的城市图像上对其进行训练,结果显示SPADE的准确性低于任何一种方法。其原因是,仅从语义分割图中合成照片比简单地修改图像更困难,而SPADE被训练为将图像合成到城市景观数据集中的图像,这意味着在城市景观和GTA之间因为场景布局的分布有过渡性。
图像到图像的翻译与Cycada 和其他各种方法进行了比较,其中Cycada专门用于将合成图像转化为现实的照片。这种方法使用像素级的循环一致性,具有低维特征的循环一致性和语义一致性损失(处理语义标签来存储合成图像的信息)。
在这些方法中,Cycada给出了最好的准确性,但它使用的语义信息多于知觉损失(视觉感知的差异),但如图所示,它产生了不相关的对象。这可能是由于分割网络是在未改变的合成图像上预先训练的,并且在训练图像合成网络的过程中没有更新。(图11)
摘要
在这项研究中,来自G-buffers的信息被很好地纳入了特征空间,并使用渲染技术训练了图像增强网络,该网络是一个在每个尺度上生成高精度图像的网络。这被认为是逼真任务成功的一个因素。此外,通过比较数据集的概率密度分布进行的分析可能已经捕捉到了导致人工制品发生的因素。也许在未来的某一天,《GTA》和其他视频游戏将与现实生活没有任何区别



与本文相关的类别


