一种对缺失数据具有鲁棒性的外推任务生成模型[材料信息学]。
三个要点
✔️ 通过 "想象 "和补充缺失数据来提高预测准确性
✔️ 在使用小型数据库寻找未知数时,可进行重要的外推预测
✔️ 与线性回归相比,准确度提高30%以上,是唯一实用的外推模型。
A Generative Model for Extrapolation Prediction in Materials Informatics
written by Kan Hatakeyama-Sato, Kenichi Oyaizu
(Submitted on 27 Feb 2021)
Comments: Published on arxiv.
Subjects: Computational Physics (physics.comp-ph)
code:
本文所使用的图片要么来自该文件,要么是参照该文件制作的。
简介
MI预测是有希望的,因为它们在某些情况下比传统的基于理论的预测或计算模拟更准确。特别是,MI通常更适合于复杂系统的理论计算,在这种情况下,成本可能会爆炸性增长。
然而,在许多情况下,传统的MI方法只能从有限的物质的有限信息中预测一种属性。因此,最好能有更灵活、更像人类的算法,并且因此,最好能有一个更灵活、更像人类的算法,并能获得和使用广泛的物质知识。
在MI中,可用的数据(信息)数量往往是有限的。转移学习是解决这个问题的有力方法,但要收集合适的数据进行预训练可能很困难。实验室实验最多提供~104条数据。在计算科学中获得的数据与实验数据有本质的不同,而且计算科学使用了许多近似值,所以要获得 "完全再现 "现象的数据并不容易。(如果你不介意这些问题的细节,它可以在一定程度上做到......)
因此,目前对能够用少量数据进行稳健预测的方法需求很大。
本研究提出的生成模型需要广泛的数据输入,而不是只看某个解释变量x和目标变量y之间的关系。然后,它使用一个小而不完整的数据库,通过 "想象力 "产生额外的数据进行训练,以预测各种属性。
此外,在这项研究中,我们将进入在MI中寻找未知因素的最重要的 "推断任务"。外推任务很困难,除了线性回归外,在MI领域很少有对 "外推 "具有鲁棒性的实用方法。
描述符的选择
分子描述符、指纹、神经网络输出和与结构有关的属性(如分子的轨道能量)被用来描述有机分子。然而,由于每个描述符都是独立开发的,因此在描述符的选择上没有明确的准则。在这项研究中,我们首先在有机分子数据库(包括H、C、N、O、S、P和卤素在内的160种小分子的小型数据库)中筛选了描述符。
记录的实验值是沸点、熔点、密度和粘度。这些物理特性值是用以下描述符算法学习和预测的。
- 二维或三维几何分子描述符(降二维或三维)。
- 指纹(FPs
- 考虑实验值的描述符(HSPiP)
- 神经描述符
- 用半经验分子轨道方法(如PM7)计算的单分子的特性
神经描述符是通过从图结构所代表的分子结构中预测上述四个参数来预学习的。XGB(Extreme Gradient Boosting)被用作模型,利用每个描述符来学习目标分子的物理特性,据说这对处理小型数据库中的非线性关系很有帮助。顺便说一下,我们在这个训练中还使用了其他三个实验值作为解释变量((例如为了预测沸点,我们用以下几个变量作为解释变量熔点、密度和粘度)。)
预测有机分子的沸点所产生的每个描述符的预测误差显示在下面的(a)中。
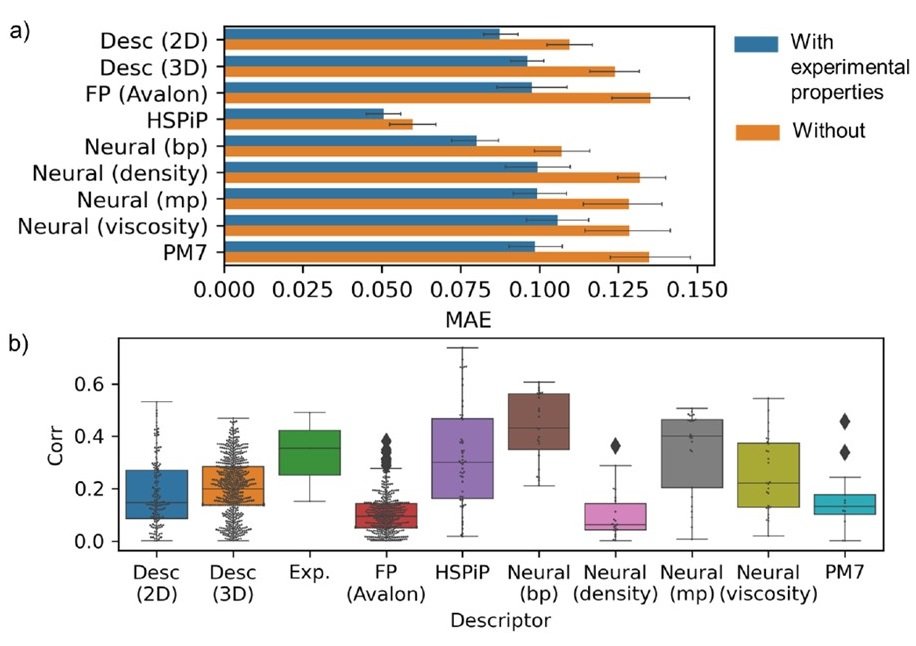
(b)显示了解释变量(用描述符描述分子的结果)和目标变量(沸点)之间的相关性比较。
HSPiP描述符是表现最好的,而预先训练的Nrural描述符也表现良好。此外,当我们在解释变量x中不仅放入描述符,还放入熔点(蓝条)等实验参数时,其性能要比单纯的描述符好得多。此外,在在神经描述符中在预测沸点时,经过训练的熔点也表现良好。这可能是由于两个参数之间有很强的关联性。然而,在在神经描述符中迁移学习并不总是能带来好的结果。这是由于以下事实广泛的物理参数以及我们的数据库规模小。
另外,目的是材料从沸点到熔点、粘度、密度等。的有效描述符也会发生变化。因此,没有一个描述符是在所有情况下都有效的。
然而,当另一个实验值被添加到x中时,性能得到了改善,这意味着实验值是一个很好的描述符。另一个测试表明,当解释变量和目标变量之间存在较强的线性相关性时,性能会有所提高(见上文(b))。因此,为了在像这样的小数据库上进行机器学习,我们需要在解释变量和目标变量之间有很强的关联性。
模型的建立和评估
实验值是有效的解释变量,但与使用一般描述符或模拟相比。测量成本。由于这个原因,实验值的数据库往往漏洞百出。
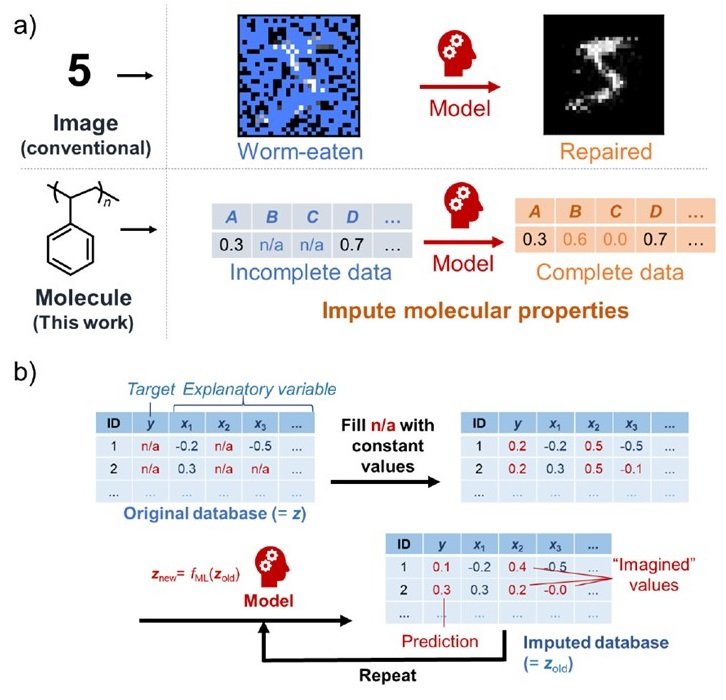
我们提出了一个生成模型,它的特点是对有洞的数据库具有鲁棒性。以图像修复为例,这种生成式模型可以通过 "想象 "被虫蛀的图像中的缺失数据来预测原始图像。这可以通过考虑观察变量之间的关系来实现,就像人类一样。在这篇文章中,我们将把这种技术用于材料数据库。通过 "想象 "缺失值的分配过程是这样的
- 首先,数据库中的x和y的孔被一个常数所取代(z老) 在数据库中。
- 然后我们用数据方差的模仿记录来训练提议的模型(znew =fML(zold))。
- 模型得到的预测结果(z新)与第一个常数(z老)被替换为
- 如此反复,直到达到收敛。
这一系列的过程使打孔的数据库变得完整。
与描述符的选择一样,从结构信息中预测了四个特性。在这种情况下,我们使用Desc 2D(二维几何分子结构的描述器)作为描述器。为了重现孔洞的形成,我们创建了一个数据库,在0、30和60%时随机删除数据。这些数据是为了测试推断任务,我们用目标变量值最高的前20%的数据被用作测试数据,其余的被用作训练数据。其余的被用作训练数据。
作为一个生成模型,我们使用了一个名为 "蒙特卡洛流量(MCFlow)"的基于流量的模型作为分配器。这个框架在一连串的分配任务上实现了最先进的性能,包括图像修复。据说适当的随机性和可逆的映射函数在预测中发挥了重要作用。与其他深度生成模型如自动编码器和GANs相比,这个框架可以在小型数据库中进行更准确的分配,这就是我们使用它的原因。
有了这个生成模型在数据损失率为0.6的数据集上对沸点进行外推预测,MAE小于0.2,而XGB的MAE约为0.3。这可能是因为XGB不适合推断。大多数决策树型的回归模型,包括随机森林和集合模型,都有一个独特的分类专用算法。因此,它们不适合用于外推任务,其结果一般与XGB的结果相似。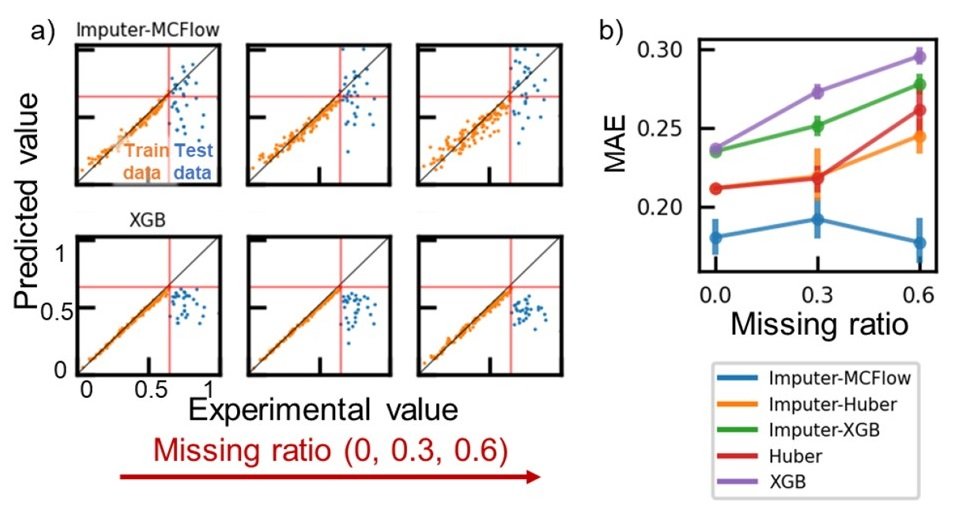
冒名顶替-XGB:以某种方式填补缺失值的结果,如平均值,并用XGB模型进行预测。
外推法领域的唯一实际应用是线性回归。损失数据由平均值代替,并使用Huber损失函数构建线性回归模型,同进行了预测。结果显示,MAE在0.20和0.25之间,比XGB好,但不如MCFlow好。因此,MCFlow模型可能是线性回归的一个很好的外推选择。
生成模型首先使用映射函数fmap将原始输入数据z转换成相同维度的向量zmap。然后通过多层感知器将zmap转换为^zmap,进行最大密度估计。那么并用反函数fmap-1重构z。
(*fmap被设计成一个可逆函数)。
有趣的是,解释(潜伏)变量在经过上述转换后,往往与客观变量有更强的关联性。这种提取"解释变量和目标变量之间的基本线性 "的能力被认为是实现高外推精度的一个强有力的促进因素。
同样的预测任务是用GAN、自动编码器(AE)和变异自动编码器进行的。结果显示,GAN没能学会。这是因为GAN未能学习,可能是因为它只有大约150个训练数据,尽管它有深度学习。AE和VAE的准确性并不差,但它们在外推范围内没有预测性。
基于流量的模型和自动编码器之间的这种性能差异可以归因于可逆转换和不可逆转换模型之间的差异。
MissForest,一个随机森林分配器,比其他流行的模型给出了更好的外推预测性能,即使是小数据库。这个框架是生成模型的衍生物,因为它从输入数据中估计出Z的分布。
如上所述,MCFlow表现出了出色的外推性能,但进一步优化超参数和网络结构将提供更好的外推和内插预测性能。
各种物理性能的预测性能
为了研究生成模型的性能,使用了几个数据库来预测物理特性。使用的数据库涵盖了12000种化合物和超过25种不同的物理特性,如玻璃化温度、比热、粘度、蒸汽压力等,包括许多缺失的数值。这个数据库已经被本生成模型用来通过替代缺失值进行预测。一个二维分子描述符被用作描述符,并在加入目标变量以外的属性后重复回归任务,以预测各种属性。前20%的目标变量被用来评估外推任务,随机选择的20%被用来评估内推任务。
作为一个例子,从大约100个数据集预测一个有机分子的粘度,MCFlow显示在外推中损失函数值比Huber(使用Huber损失函数建立的线性回归模型)改进了近30%,在内插中也有类似的结果。在内插法方面也得到了类似的结果。
此外,还用繁殖率和配合率作为评价指标进行了评估,定义如下
召回率=外推区域内准确预测的百分比
精确度=插值区域中没有错误地找到一个性能良好的候选值的比例。
Huber的结果是0%,而MCFlow给出的数值分别为19%和75%(见上文b)。考虑到推断任务的难度,MCFlow的数值为19%是一个很好的第一步。
当使用的数据数量少于100个时,MCFlow更胜一筹,但当使用的数据数量超过100个时,MCFlow和Huber的预测精度变得相似。这可能是由于当数据数量超过100个时,每个预测器都得到了足够的信息。然而,由于通过实验建立数据库的成本和精力,MCFlow是更好的模型,因为它可以用较少的数据量进行更准确的预测。
与其他模式的比较
线性回归,如Huber,是一个简单而稳健的模型,但其使用是有限的。这是因为由许多不同元素组成的复杂的化学和物理现象并不总是适合于线性回归。
只有在预训练所需的数据量足够时,才能应用转移学习。使用图结构作为描述符的模型是强大的方法,但在数据量较小的情况下同样不能应用。此外,转移学习和图结构模型都有一个缺点,即预测是黑箱式的,使研究人员难以理解材料的结构和性能之间的相关性。另一方面。拟议的生成模型比这两者都有优势。另一方面,拟议的生成模型比这两者都有优势,因为结构和属性之间的相关性被更明确地表示为一个 "生成的数据库"。
此外,基于流动的生成模型在推断任务方面表现出色。另一方面,其他MI中使用的算法往往是专门用于插值任务的。
摘要
在本文中,我们提出了一个生成模型,可以替代和预测不同物质的各种信息。通过对缺失数据的 "想象",我们能够提高内插和外推任务的预测精度。这与我们人类的做法非常接近。特别是,由于推断任务是寻找未知数中最重要的任务,希望这项研究的结果将导致MI的突破。



与本文相关的类别
.jpg)


![[材料信息学]CGCNN-转移学习模型在](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2021/物性値のデータ不足に対応3-min-520x300.png)
![[材料信息学]通过个体剩余学习成功地挖掘](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2021/individual_residual_learning-min-520x300.png)
