
在没有注释数据的领域下,固有表象识别!
三个要点
✔️ 使用弱监督学习技术在没有标签数据集的领域进行固有表象识别
✔️ 用多标签函数和隐藏马尔科夫模型对域外数据集进行标签处理
✔️ 在两个数据集中,比传统的域外固有表象识别模型的性能提升7%
Named Entity Recognition without Labelled Data: A Weak Supervision Approach
written by Pierre Lison,Aliaksandr Hubin,Jeremy Barnes,Samia Touileb
(Submitted on 30 Apr 2020)
Comments: Published by ACL 2020
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG); Machine Learning (stat.ML)
介绍
命名实体识别(NER)是从文本中提取人名、地名和日期等特征表达式的任务。它使用模型将文本中的每一个单词标注为一个人<PERSON>或一个日期<DATE>。不是专有名词的词用<O>来表示。这项任务是各种任务的内容之一,如
- 机器翻译
- 对话模式
- 问题解答
- 信息提取
- 文件匿名化
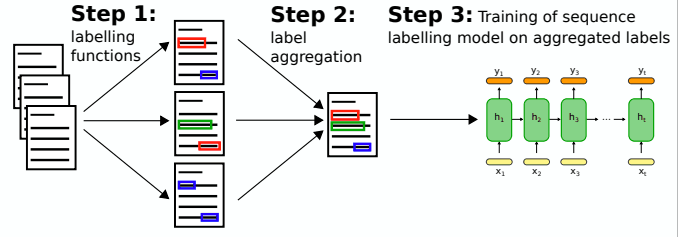
虽然本征识别是一项如此重要的任务,但众所周知,如果目标域与源域不同,其性能会迅速恶化。另一方面,如果有与目标域相匹配的训练数据,转移学习对于特征代表识别也是有效的。因此,在本文中,我们介绍了一种在没有目标域的训练数据时,自动标记目标文本的方法。大致来说,我们可以通过以下两步对目标文本进行自动标注。
- 用多种标签功能给文本贴标签
- 用隐藏马尔科夫模型将不同的标签数据聚合成一个数据。
而通过对这些聚合数据的训练模型,他们可以对没有训练数据的领域的文本进行特征识别。
他在这里介绍的方法在GitHub上是开源的。
https://github.com/NorskRegnesentral/weak-supervision-for-NER
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别






