不同人收到的建议的质量是否有变化?处理推荐系统中的偏见。
三个要点
✔️ 提出了四种区分主流和利基用户的方法
✔️ 证明在传统推荐模型中,主流用户比小众用户更准确的偏见
✔️ 三种建议的消除偏见的方法。
Fighting Mainstream Bias in Recommender Systems via Local Fine Tuning
written by ,
(Submitted on 15 February 2022)
Comments: WSDM '22
Subjects: Information Retrieval (cs.IR)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
推荐系统在缓解信息过载的问题上发挥着重要作用,它将用户与更好的项目联系起来。
大多数推荐系统,包括旧的线性模型和最近的神经网模型,都是通过预测用户的偏好来进行推荐的,其依据是协同过滤(CF)。
CF的关键思想是通过寻找与目标用户有类似兴趣的用户,从用户的行为中推断出其偏好。因此,推荐的质量在很大程度上取决于推荐模型找到类似用户的难易程度。
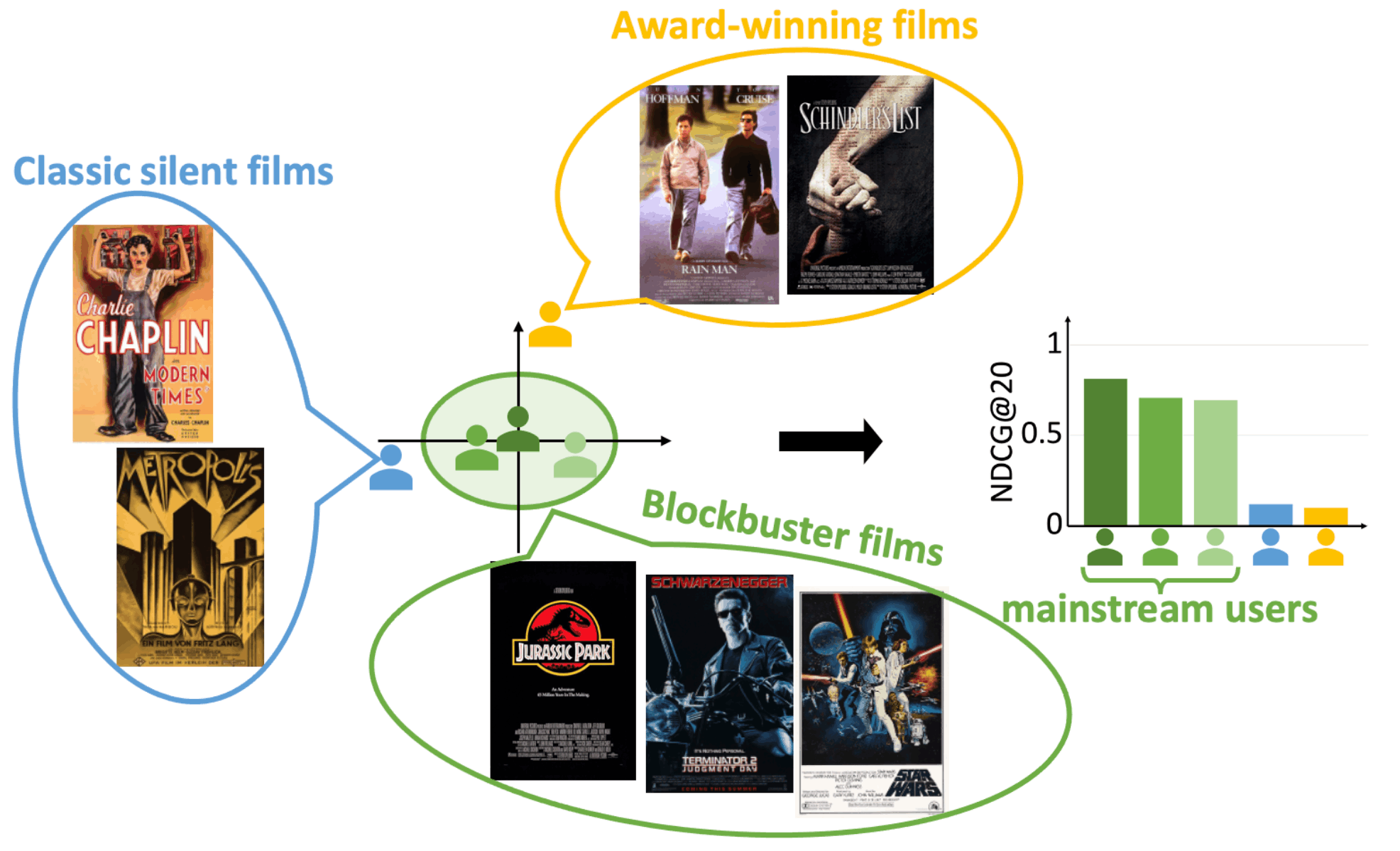
上图显示了三个主流用户和两个小众用户:三个主流用户倾向于青睐热门大片,在最近的变异自动编码器(VAE)模型中具有较高的推荐精度(NDCG@20)。相比之下,两个面向小众的用户(一个喜欢老式默片,一个喜欢80年代末的获奖影片)的推荐准确率较低。
非主流的小众用户往往很难找到类似的用户,导致推荐质量较低。
这种推荐模型偏向主流用户而非小众用户的趋势被称为主流偏见。
计算出用户的主流分数
作者首先提出了一个主流分数,表明每个用户的主流程度,以分析主流偏见对推荐的影响。为了计算主流得分,我们考虑了四种基于离群点检测技术的方法。
让我们逐一看一下这四种方法。
基于相似性的
在基于相似性的方法中,用户与目标用户的相似度越高,主流分数就越高。
对于所有的用户对,用户之间的相似度是通过Jaccard相似度计算的。这里,用户之间的相似度表示为$J_{u,v}$。
目标用户$u$和另一个用户$v$之间的平均相似度是主流得分。
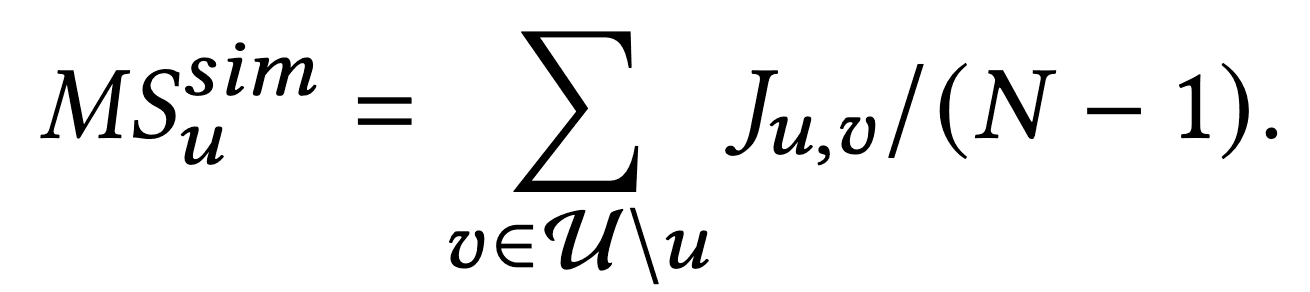
基于密度的
基于密度的方法从其邻近地区的密度来确定一个样本是否为离群点。在这项研究中,著名的局部离群因子法(LOF)被用来识别离群者(小众用户);LOF用减号标记,因为数值越高表明样本是离群者。
![]()
基于分配的
基于分布的方法是根据物品被偏好的概率分布向量$d$和目标用户偏好的物品的历史向量$O_u$之间的相似性来计算的。在这种情况下,$d$是所有用户的物品偏好历史的平均值。另外,$cos()$代表余弦相似度。
![]()
基于DeepSVDD的
DeepSVDD是一种基于深度学习的离群算法 深度支持向量数据描述。它通过一个神经网络将样本数据映射到一个超球体上,并将远离超球体中心的样本视为离群值。这里$DeepSVDD\left(O_{u}\right)$是超球上用户$u$的向量,$c$是代表超球中心的向量。
![]()
显示出主流的偏见
为了观察主流偏见,根据先前的主流得分,对用户进行升序排序,并将其分为五个大小相同的子组。
下表显示了将VAE应用于MovieLens 1M并对每个子组的NDCG@20进行平均的结果。这里,"低"、"中低"、"中"、"中高 "和 "高 "是主流得分最高的组别,依次为 "低"、"中低"、"中高 "和 "高"。

从表中可以看出,对于这四种方法,主流得分越高,对该组的推荐准确率越高。
结果显示,作者提出的所有方法都能识别小众用户,导致推荐准确率低,而且推荐模型引入了严重的主流偏差。
作者还试验了其他模型,如MF、BPR和LOCA,以及其他数据集,如Yelp和Epinions,并证实观察到相同的趋势。
建议的解决方案
提出了两种全局方法和一种局部方法来缓解主流偏差。
全局方法是在训练模型时为小众用户训练一个权重较大的模型,而局部方法是为不同的用户训练定制的局部模型。
全球方法论
分布式校准法(DC)
DC是一种基于数据增强的方法,生成与现有利基用户相似的合成数据,使利基用户成为训练数据集的主流。
具体来说,首先使用上述方法之一来确定利基用户。例如,在DeepSVDD的案例中,主流得分最低的50%的用户被认为是小众用户。然后,我们通过获得给定利基用户$u$的类似用户,得到一个校准的分布向量$p_u$。
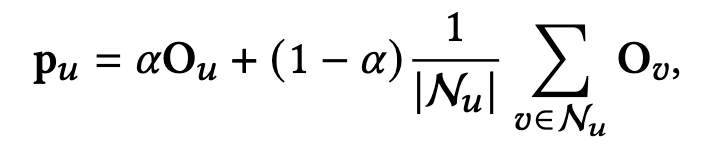 在这种情况下,$/mathcal{N}_u$是由Jaccard相似度决定的相似用户集合,$0\leq α\leq 1$是控制用户$u$的偏好历史权重的超参数。
在这种情况下,$/mathcal{N}_u$是由Jaccard相似度决定的相似用户集合,$0\leq α\leq 1$是控制用户$u$的偏好历史权重的超参数。
最后,根据这个分布向量$p_u$对用户进行采样。在这个扩展数据集上训练的模型使我们能够提高利基用户的重要性,并减轻主流用户的影响。
加权损失法(WL)
WL是一种直接增加损失函数中利基用户的权重的方法;以VAE模型为例,损失函数将如下
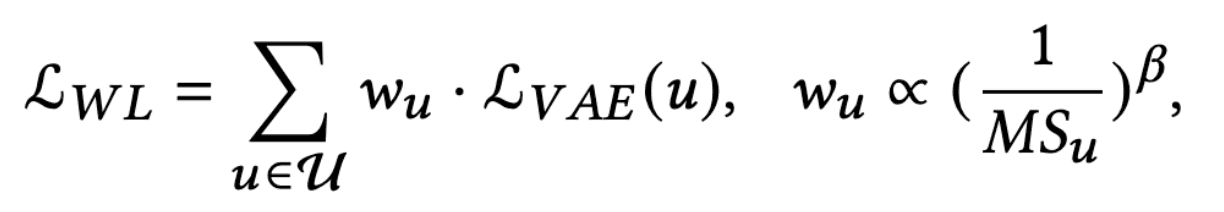
其中$mathcal{L}_{V A E}(u)$是用户$u$的原始VAE损失,$w_u$是用户$u$的权重。u$的权重是$left(\frac{1}{M S_{u}}right)^{\beta}$,其中$\beta$是一个控制消除偏差强度的超参数。$beta$越大,去除偏差的效果越强,而0意味着没有去除。
这种加权的损失函数增加了利基用户的重要性。
本地方法
全局性的方法可能会导致权衡,比如对小众用户的推荐准确度较高,但对主流用户的准确度较低。因此,作者建议采取地方性方法。
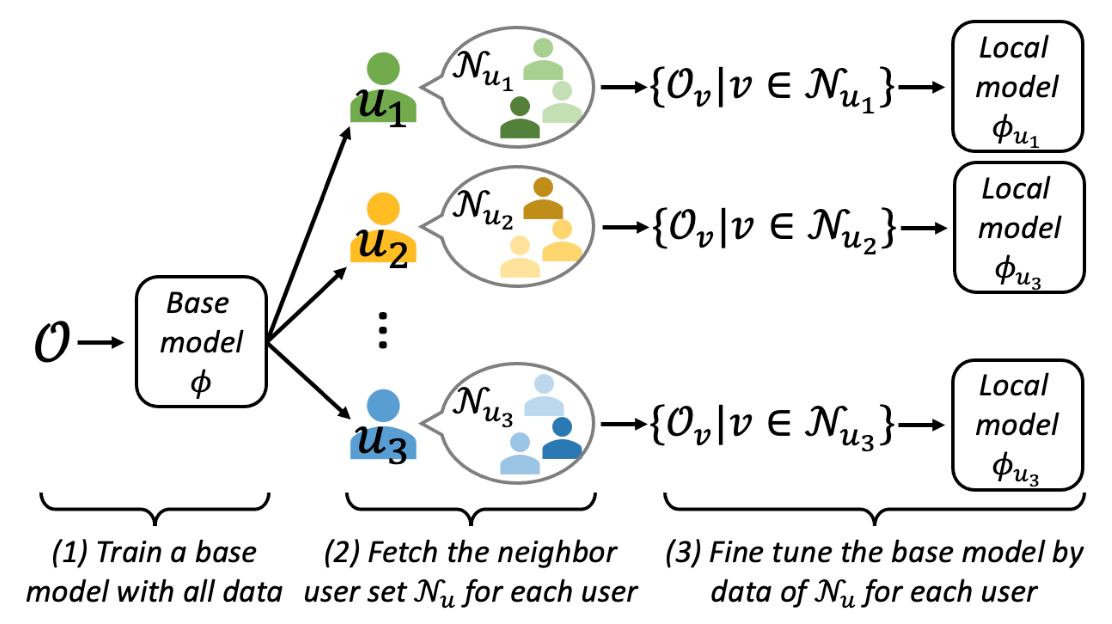
局部微调(LFT)
建议使用本地推荐方法来解决主流偏见。本地推荐方法的想法是选择锚用户,并为每个锚用户学习一个专门的锚模型。
LFT分为三个步骤。
- 用所有数据集训练基础模型$phi$。
- 与目标用户$u$有类似偏好的相邻用户。从$mathcal{N}_{u}$来看,只有偏好历史数据的子数据集创建$O_{mathcal{N}_{u}}==left\{O_{v} mid v\in \mathcal{N}_{u}right\}$。
- 使用子数据集$O_{mathcal{N}_{u}}=left\{O_{v}\mid v\ in \mathcal{N}_{u}right\}$对用户$u$的基础模型进行微调。
这样一来,微调后的$u$的局部模型$phi_{u}$可以使小众用户较少地受到主流用户和其他小众用户的影响。
实验
实验是在ML1M、Yelp和Epinions数据集上进行的。
使用VAE作为基础模型,并在一个模型上进行了实验,其中所提出的方法被应用于VAE。全球方法包括分布校准(DC)和加权损失(WL)。本地方法包括作为基线的最新的本地协作自动编码器(LOCA)、提出的本地微调(LFT)方法及其集合版本、LFT模型的集合版本(EnLFT)。

结果显示,作者提出的LFT实现了出色的准确度NDCG@20,与VAE相比,在 "低"、"中低 "和 "中 "组的准确度明显提高。对于主流用户群,如 "中高 "和 "高",也可以看到准确度的提高。
这表明,LFT不仅对小众用户有效,而且对主流用户也有效。
全局性的方法,如DC和WL,对小众用户来说更准确,但对主流用户来说则不太准确。
摘要
情况如何?我们提出了一种计算主流分数的方法,展示了主流偏见,并提出了三种减轻偏见的方法。我们觉得,关注主流偏见,比如主流用户从推荐系统中受益,而小众用户没有完全受益,是实现公平推荐系统的一个重要视角。
在未来,我们希望看到更多关于公正的推荐系统的偏见的研究。



与本文相关的类别

![[Chat-REC] 拟议的基于 LLM](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/chat-rec-520x300.png)


