重新思考表格数据的深度学习模型
三个要点
✔️ 考察表格式数据上的深度学习方法的现状
✔️ 提出一个基于ResNet和Transformer的基线
✔️ 与现有深度学习方法、GBDT和基线的比较实验
Revisiting Deep Learning Models for Tabular Data
written by Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, Artem Babenko
(Submitted on 22 Jun 2021 (v1), last revised 10 Nov 2021 (this version, v2))
Comments: NeurIPS 2021
Subjects: Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
梯度提升决策树(GBDT)是最受欢迎的表格数据方法之一,但也有很多关于将深度学习用于表格数据的研究。
然而,在表格数据领域,现有的深度学习方法还没有得到充分的比较,部分原因是没有既定的基准(如图像识别的ImageNet或自然语言处理的GLUE)。因此,诸如深度学习方法在表格数据上的有效性以及GBDT和深度学习方法哪个更胜一筹等问题仍然不清楚。
在这篇文章中,我们介绍了一个简单的表格数据的基线方法和一个多样化的任务集,对表格数据上的深度学习方法进行了详细的检查。让我们看看下面的内容。
表格式数据问题的模型
首先,我们介绍了对表格数据问题进行性能比较实验的模型。
MLPs
MLP(多层感知器)由以下公式表示
$MLP(x) = Linear (MLPBlock (...(MLPBlock(x))))$)
$MLPBlock(x) = Dropout(ReLU(Linear(x)))$
储备网
接下来,我们介绍一个基于ResNet的简单基线,它主要用于计算机视觉任务。这可以用以下公式表示
$ResNet(x) = 预测 (ResNetBlock (...(ResNetBlock (Linear(x)))))$)
$ResNetBlock(x) = x + Dropout(Linear(Dropout(ReLU(Linear(BatchNorm(x))))))$)
$Prediction(x) = Linear (ReLU (BatchNorm (x))$
ResNetBlock引入了一个类似于现有ResNet的跳过连接。
FT-变压器
接下来,我们介绍FT-Transformer(特征标记转换器),它是对Transformer架构的修改,适用于表格数据,已成功用于各种任务,包括自然语言处理。粗略的结构如下图所示。
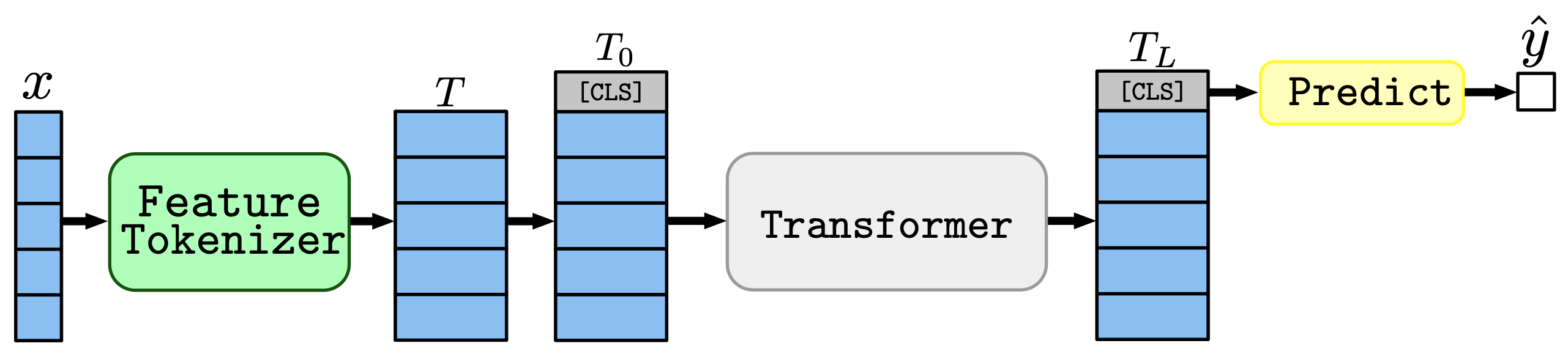
作为一个整体,输入的$x$首先被特征标记器转换为嵌入的$T$,然后添加了[CLS]标记的$T0$被传递到转换器中。然后根据最后一个[CLS]标记所对应的表示进行预测。
关于特征代码器
特征标记模块将输入的$x$转换为R^{k×d}$中的嵌入$T\。
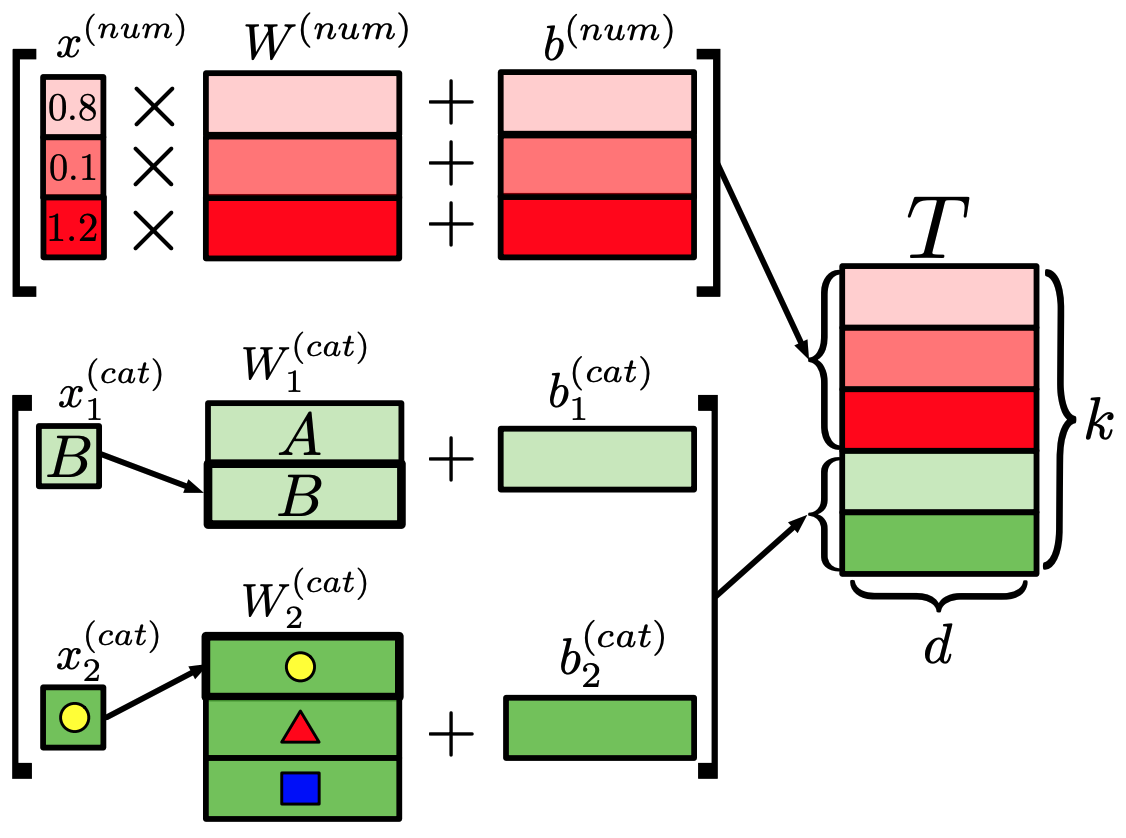
在这种情况下,根据输入的$x$是数字数据($x^{(num)}$)还是分类数据($x^{(cat)}$),会进行不同的处理,如下式所示。
$T^{(num)}_j = b^{(num)}_j + x^{(num)}_j δcdot W^{(num)}_j δin R^d$
$T^{(cat)}_j = b^{(cat)}_j + e^T_j W^{(cat)}_j in R^d$。
$T = 堆栈 [T^{(num)}_1, ... , T^{(num)}_{k^{(num)}} , T^{(cat)}_1 , ...。 , T^{(cat)}_{k^{(cat)} ]/in R^{k×d}$
其中$k$是特征的数量,$e^T_j$是与分类特征相对应的单热向量。
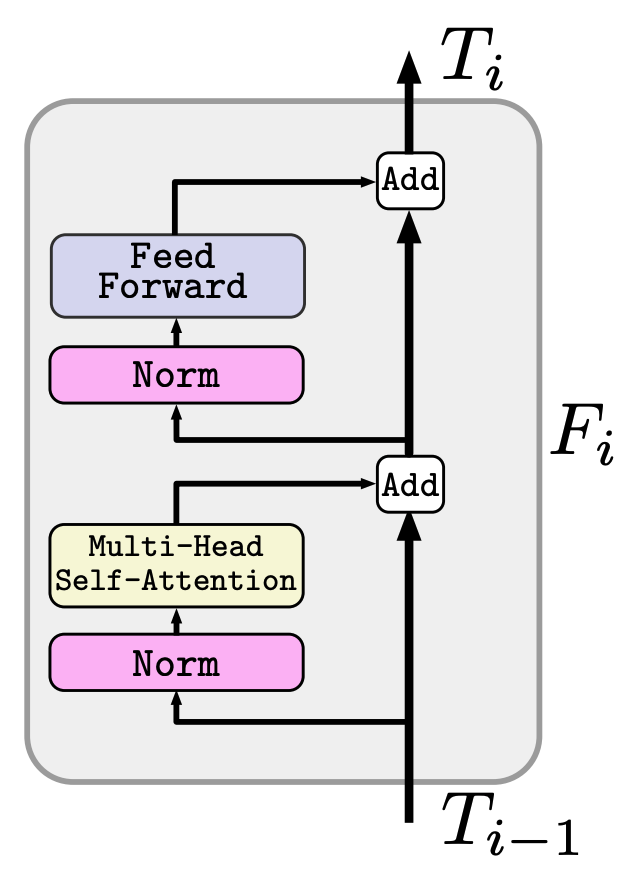
关于Tranformer
变压器过程由$L$变压器层$(F_1,...,F_L)$组成,如下图所示。,F_L)$,如下图所示。
关于预测
使用通过转化器获得的[CLS]标记表示,通过以下公式描述的过程进行预测。
$hat{y} = Linear(ReLU(LayerNorm(T^{[CLS]}_L))))$)
作为注意事项,FT-Transformer与MLP和ResNet相比有一些挑战,如训练所需的大量资源和难以应用于大量的特征。
(这可以通过使用更有效的变形器变体来改善)。
其他型号
在专门为表格数据设计的现有模型中,以下是用于比较实验的模型
实验结果
在本节中,我们比较了不同架构的性能。我们不采用独立于模型的方法,如预学习或数据增强。
数据集
在实验中,我们使用了11个不同的数据集,如下图所示。

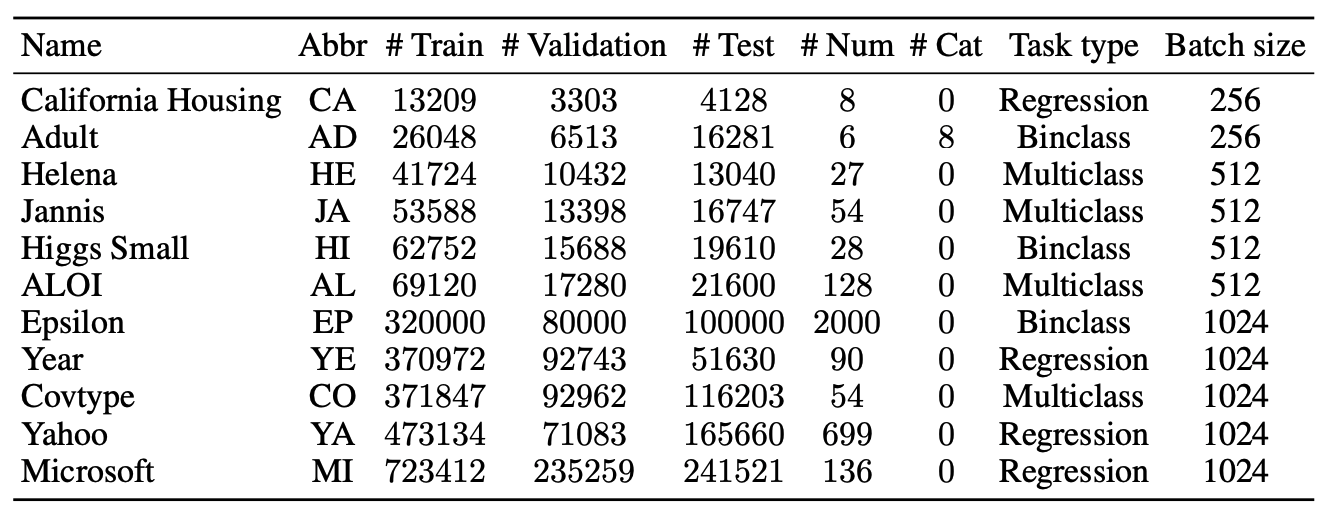
(RMSE代表均方根误差,Acc代表准确度。)
为了评估性能,我们用不同的随机种子进行了15次实验。在集合设置中,15个模型被分为5组,每组5个,并使用每组内预测的平均值(其他设置见原始论文)。
深度学习模型的比较
深度学习模型的实验结果如下
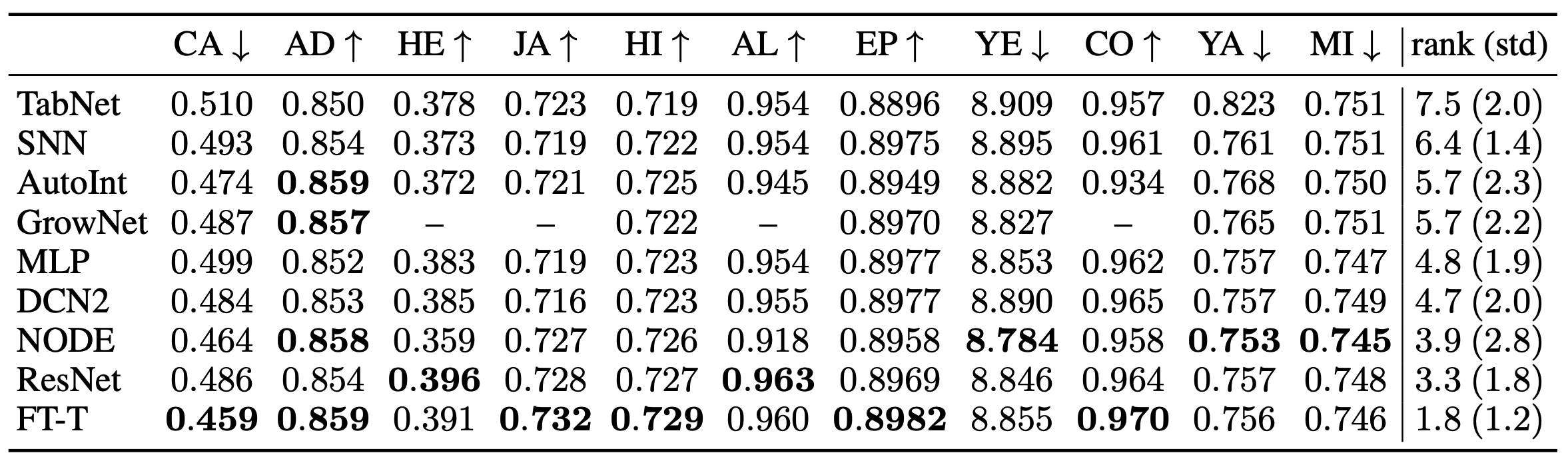
表格右侧的排名显示了每个模型的平均排名。
在本文介绍的基线中,FT-Transformer(FT-T)在大多数任务中表现最好,因此是一个非常强大的模型。
ResNet也被认为是一个有效的基线,尽管它很简单,但显示的结果仅次于FT-Transformer。在其他方法中,NODE显示了最好的结果。集合设置的结果也显示在下面。

在集合设置中,ResNet和FT-Transformer显示了更好的结果。
深度学习模型和GBDT的比较
下一步是将深度学习模型与GBDT进行比较。然而,我们将忽略速度和硬件要求,比较每种方法所能达到的最佳性能。
由于GBDT包括一个集合技术,深度学习模型也使用集合设置的结果进行比较。结果如下
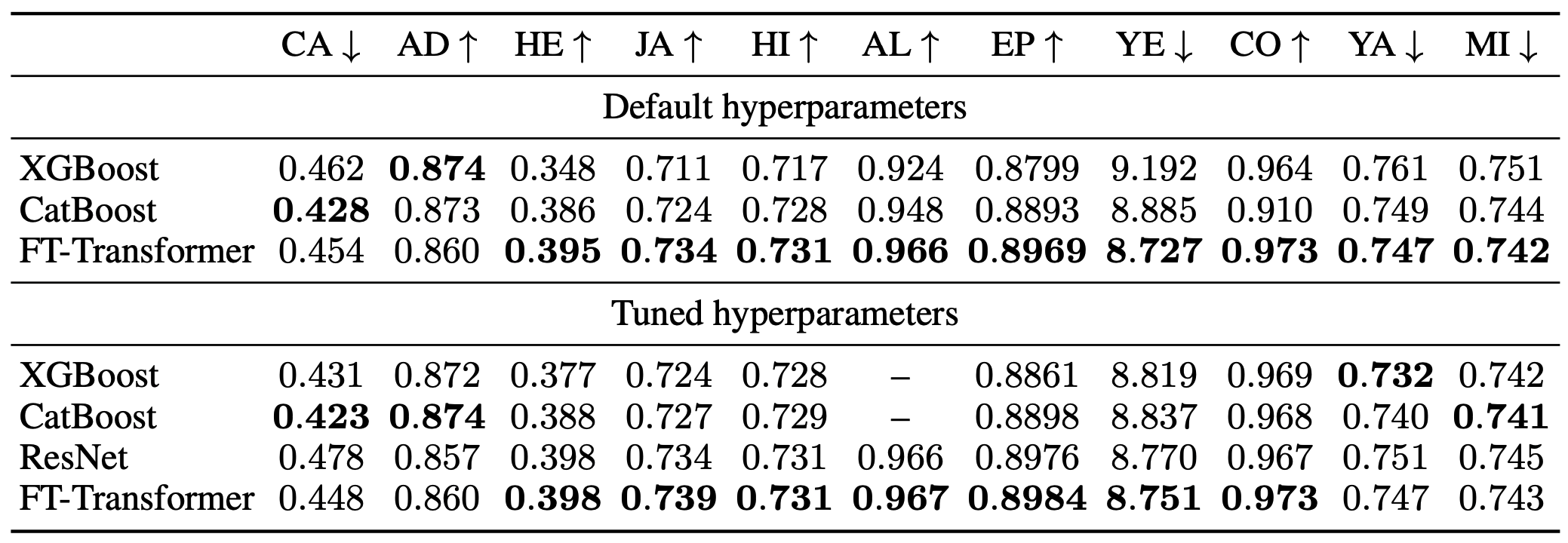
默认的超参数显示了默认的超参数设置,调整的超参数显示了超参数调整后的模型结果。
FT-Transformer在默认乐器和调音乐器上的表现同样出色,这表明无需调音也可以建立一个优秀的合奏模型。
我们还发现,GBDT在一些任务中的调谐设置表现更好,不能排除深度学习模型总是优于GBDT的情况。
(如果只比较任务的数量,似乎深度学习模型更胜一筹,但这可能只是因为该基准偏向于更适合深度学习模型的问题)。
然而,FT-Transformer在所有的任务中都表现良好,与其他方法相比,它是一个更通用的表格数据模型。
一般来说,我们不能说总有一种方法是DL模型和GBDT之间的最佳解决方案。也可以说,未来对深度学习方法的研究应该集中在GBDT优于深度学习方法的数据集上。
FT-Transformer和ResNet的比较
为了比较FT-Transformer和ResNet的普遍性,我们将使用一个合成任务进行实验。
具体来说,对于代表30个随机构建的决策树的平均预测的$f_{GBDT}$和具有三个随机初始化隐藏层的MLP的$f_{DL}$,我们创建了以下合成数据。
$x ~ N(0, I_k), y = α\cdot f_{GBDT}(x) + (1 - α) \cdot f_{DL}(x)$
这个合成任务被认为在$alpha$较大时更适合于GBDT,而在$alpha$较小时更适合于深度学习方法。
该合成任务中不同方法的比较如下
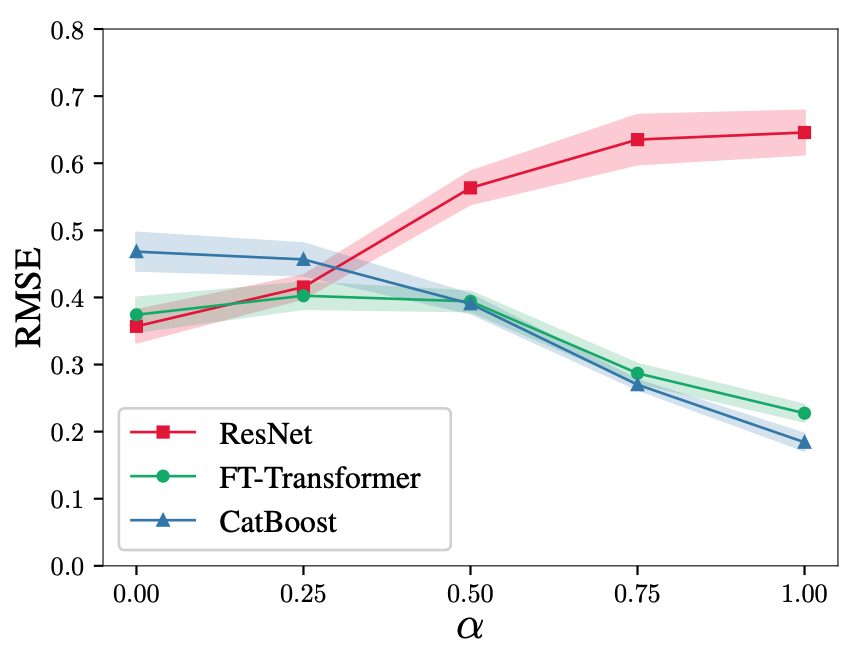
从图中可以看出,在面向GBDT的设置中,ResNet的性能明显恶化,而FT-Transformer则普遍表现良好,揭示了FT-Transformer的普适性。
最后,ResNet和FT-Transformer的学习时间比较如下。

一般来说,FT-Transformer需要更多的时间来训练,特别是在具有大量特征(YA)的数据集上,FT-Transformer的高计算成本是未来需要改进的一个重要问题。
摘要
在本文中,我们在表格数据上实验了深度学习模型,引入了一个简单的基线,并与现有的方法进行了比较。
它包括关于表格数据深度学习方法的各种信息,如基于ResNet的模型,它是表格数据深度学习方法的一个有用的基线,FT-Transformer是Transformer在表格数据中的应用,以及与当前深度学习方法和GBDT的比较。它包含了很多关于该方法的信息,官方代码也是可用的。如果你有兴趣,请你也看看原始论文。



与本文相关的类别
