
TwiBot-22,一个用于检测Twitter机器人用户的基于图形的大型数据集,现在可以使用了!
三个要点
✔️ 创建了TwiBot-22,一个基于图形的Twitter机器人检测基准,其注释质量比现有数据集好得多
✔️ 包括TwiBot-22在内的9个数据集的35个代表性基线模型使用
✔️ 与所有现有数据集和基线模型的比较实验表明,TwiBot-22可以作为一个全面的评估基准 ,重新实施和重新评估
TwiBot-22: Towards Graph-Based Twitter Bot Detection
written by Shangbin Feng, Zhaoxuan Tan, Herun Wan, Ningnan Wang, Zilong Chen, Binchi Zhang, Qinghua Zheng, Wenqian Zhang, Zhenyu Lei, Shujie Yang, Xinshun Feng, Qingyue Zhang, Hongrui Wang, Yuhan Liu, Yuyang Bai, Heng Wang, Zijian Cai, Yanbo Wang, Lijing Zheng, Zihan Ma, Jundong Li, Minnan Luo
(Submitted on 9 Jun 2022 (v1), last revised 12 Feb 2023 (this version, v6))
Comments: NeurIPS 2022, Datasets and Benchmarks Track
Subjects: Social and Information Networks (cs.SI); Artificial Intelligence (cs.AI)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
Twitter机器人检测是一项在Twitter内检测机器人账户(自动用户)的任务,它在检测假新闻和保持在线通信安全方面引起了人们的关注。
现代检测方法通常利用Twitter网络的图形结构,这使得它们能够对训练数据中不存在的、以前的方法无法检测到的新Twitter机器人有良好的表现。
然而,现有的用于Twitter机器人检测的数据集很少是基于图的,而且现有的少数数据集也存在着数据量有限、图结构不完整和注释质量低等问题,这种缺乏大图基础的缺失阻碍了基于图的僵尸检测模型的开发和评估。
本文通过一个全面的基于图的Twitter机器人检测基准TwiBot-22来解决这些问题,该基准比现有的数据集具有更好的注释质量,并提供了Twitter网络上的各种图结构。本节介绍了本文提出的
推特机器人检测
从假新闻、选举干扰和阴谋论的传播中可以看出,推特机器人对社会的负面影响,多年来规模不断扩大,这些社会问题促使人们开发出防止推特机器人负面影响的模型。
现有的Twitter机器人检测模型一般都是基于特征的,并提出了从用户信息(如元数据、用户时间线和关注关系)中提取数字特征的方法。
随后,研究人员还提出了基于文本的方法,开发了文字分析方法,如单词嵌入、RNN和预训练的语言模型,以分析推文内容,识别恶意。
然而,有人提出挑战,现代Twitter机器人经常复制真实用户的常规推文,并在其间插入恶意内容,使这些基于文本的方法不那么有效。
在此背景下,随着图神经网络的出现,近年来,人们开始关注基于图的Twitter僵尸检测模型的发展,它将用户解释为节点,将关注关系解释为边,使GCN、R-GCN和RGT等方法能够这使得GCN、R-GCN和RGT等方法能够用于基于图的僵尸检测。
尽管与现有的方法相比,这些基于图的方法能够更好地解决各种挑战,例如能够检测到新的Twitter机器人,但它们没有得到现有数据集的很好支持,特别是存在三个问题,如下图所示,即(a)数据集结构有限,(b)图结构不完整结构和(c)注释质量低,如下图所示。
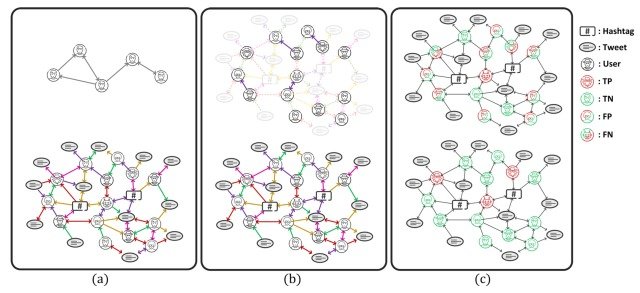
为了解决这些问题,本文提出了TwiBot-22,一个基于图形的大型数据集。
TwiBot-22。
现有数据集的一个共同问题是,数据集只包含少数类型的机器人,而在现实生活中,Twitter同时存在着各种各样的用户和机器人。
为了解决这些问题,TwiBot-22使用广度优先搜索来收集用户,用多样性意识的抽样来增加获得的用户,使之能够包含各种类型的用户和机器人。这种搜索的结果被用来确定用户和机器人的数量。
这使得TwiBot-22比现有最大的数据集大五倍,包含92,932,326个节点(用户)和170,185,937条边(跟随关系)。
然后,所有的数据都由一个自动注释模型进行注释,使用的数据是让机器人检测专家对TwiBot-22中随机选择的1000个用户进行注释。
TwiBot-22和现有数据集的比较见下图。
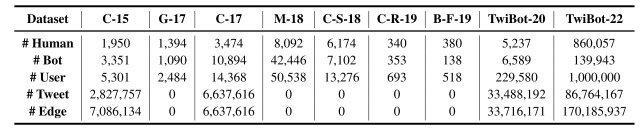
因此,可以看出,与现有的数据集相比,TwiBot-22由一个非常大的和多样化的用户和机器人组成。
实验
在本文中,针对上表中比较的九个数据集,包括TwiBot-22,重新实施了35种基线方法,并进行了如下图所示的比较实验。
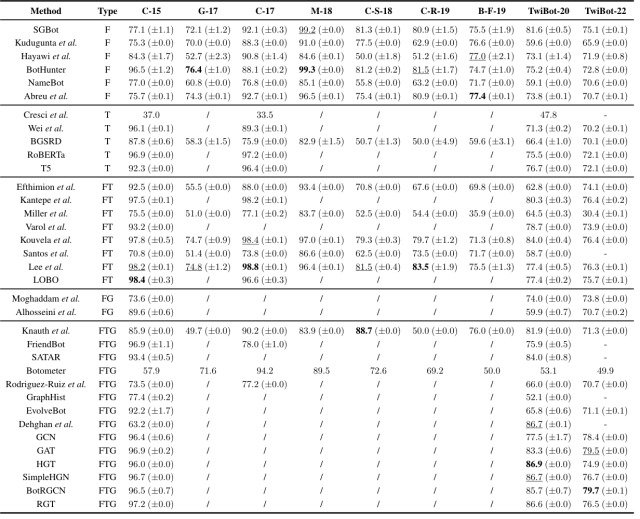
这一比较实验的结果可以总结为以下几点。
- 基于图的方法通常比基于特征或文本的方法更有效,事实上,TwiBot-20和TwiBot-22的前五个模型都是基于图的方法。
- 虽然大多数现有的数据集不包括Twitter用户的图形结构,以支持基于图形的方法,但TwiBot-22支持所有的基线方法,并作为一个综合评估基准。
- 在所有基线方法中,针对TwiBot-22的准确率平均比TwiBot-20低4.8%,表明Twitter机器人检测是一项需要进一步研究的任务。
特别是关于第三个发现,作者指出,僵尸检测模型也需要不断改进,才能检测到这些,因为Twitter的僵尸通过技术改进不断逃避检测。
摘要
它是怎样的?在这篇文章中,我们提出了一篇论文,提出了TwiBot-22,一个新的大规模数据集,用于基于图形的Twitter机器人检测。
涉及TwiBot-22的综合比较实验表明,该数据集是一个有效的评估基准,但在Twitter机器人检测任务中,以下问题仍未得到解决
- 如何识别机器人集群?(新的Twitter机器人已经被确认为通过分组行动和相互合作而形成集群)。
- 如何结合多模态的用户特征来提高检测精度?
- 如何评估一个模型的可普遍性?
作者表示,他将在TwiBot-22的基础上重点解决这些问题,未来会发生什么值得关注。
本文介绍的数据集和基线模型架构的细节可以在本文中找到,如果你有兴趣的话,可以参考。



与本文相关的类别
