知道最好的训练模型,准确率高,速度快! 一个预测模型可转移性指标的LEEP来了,!
3个要点
✔️提出LEEP这个度量标准,它能高精度地预测哪些学习到的模型应该用于转移学习,以产生准确的模型。
✔️计算速度更快,因为我们只需要使用学习的模型对目标域的数据进行一次预测。
✔️第一个与最近提出的Meta-Transfer Learning的准确率显示出高度相关的度量。
LEEP: A New Measure to Evaluate Transferability of Learned Representations
written by Cuong V. Nguyen, Tal Hassner, Matthias Seeger, Cedric Archambeau
(Submitted on 27 Feb 2020 (v1), last revised 14 Aug 2020 (this version, v2))
Comments: Accepted to the International Conference on Machine Learning (ICML) 2020.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
首先
众所周知,深度学习模型由于其相比传统方法有非常好的预测精度,已经被应用到我们日常生活的各个方面。特别是在图像识别、自然语言处理、语音识别等领域,深度学习模型已经取得了比传统方法更高的精度。深度学习模型之所以有这么好的准确率,原因之一是模型已经获得了一种机制来提取对预测非常重要的特征。
另一方面,众所周知,提取这些特征的机制是通过对大量数据的训练获得的。这意味着,要实现深度学习模型的准确性,需要大量的数据。换句话说,要实现深度学习模型的准确性,需要大量的数据。转移学习"是解决这一问题的一个非常有效的方法。转移学习通过重用已经在大量数据上训练过的模型的特征提取部分,使得即使在有限的数据量下也能达到准确率。一般来说,在1000万张图像上训练的1000个类的模型,称为ImageNet(以下简称"训练模型"),其参数会被重复使用,只有实际执行预测的部分会被替换和重新学习。
现在,这给我们带来一个问题。对于我的数据集,什么是最好的训练模型?这里,我们假设训练原始学习模型的数据是固定的(如上面的ImageNet)。比如解决深度学习模型梯度消失问题的ResNet,以及可以在CPU上运行的MobileNet。
当然,如果你有足够的计算资源,你可以使用所有可能的模型重新学习,并选择其中精度最好的一个。但是,一般企业没有这么丰富的计算资源,他们只能在有限的计算资源内选择和重新学习他们认为好的模型。如果能找到一个计算量小的次优模型,对企业是非常有利的。给定一个训练好的模型和一个目标数据集(待再训练的数据集),本研究的目标是选择一个次优的训练模型,用少量的计算量在目标数据集上达到良好的精度。为此,我们提出了LEEP作为度量标准,并成功地选择了最佳模型,其精度高于传统方法。我们来看看什么是LEEP,它是如何工作的。
相关研究
转化学习
元转折学习是2018年提出的一个很新的研究领域。元转移学习的目标是学习如何从源任务转移到目标任务。用字母表达可能听起来不太对,但教育心理学的研究表明,这是人类每天都在做的事情。比如,我们考虑一个擅长下棋的孩子。那孩子了解到,在国际象棋中获得的经验其实可以应用到数学和拼图中。在孩子成长的过程中,会有很多经验(用工具搭桌子、和朋友玩得很好等),当面对一个新的、未知的任务A时,就能用所学的知识判断出B可以用什么任务来帮助解决任务A,如何解决。换句话说,我们可以学习如何在任务之间转移。换句话说,他们正在学习如何在任务之间转移。下图显示了转移学习、多任务学习、持续学习和元转移学习的区别,实验表明,LEEP是衡量这种元转移学习准确性的良好指标。
![]()
任务空间代表
任务空间表示是试图用一个向量来表示一个很模糊的东西,叫做任务。例如,一个叫TASK2VEC的方法很有名,在AI-SCHOLAR中也有报道。它将任务表示为向量,通过测量向量之间的距离,可以确定模型训练的数据集应该用于转移学习。然而,TASK2VEC通过训练一个称为探针网络的大型模型,并将其应用于目标数据,获得了任务的表示。这意味着它的缺点是需要大量的计算资源。 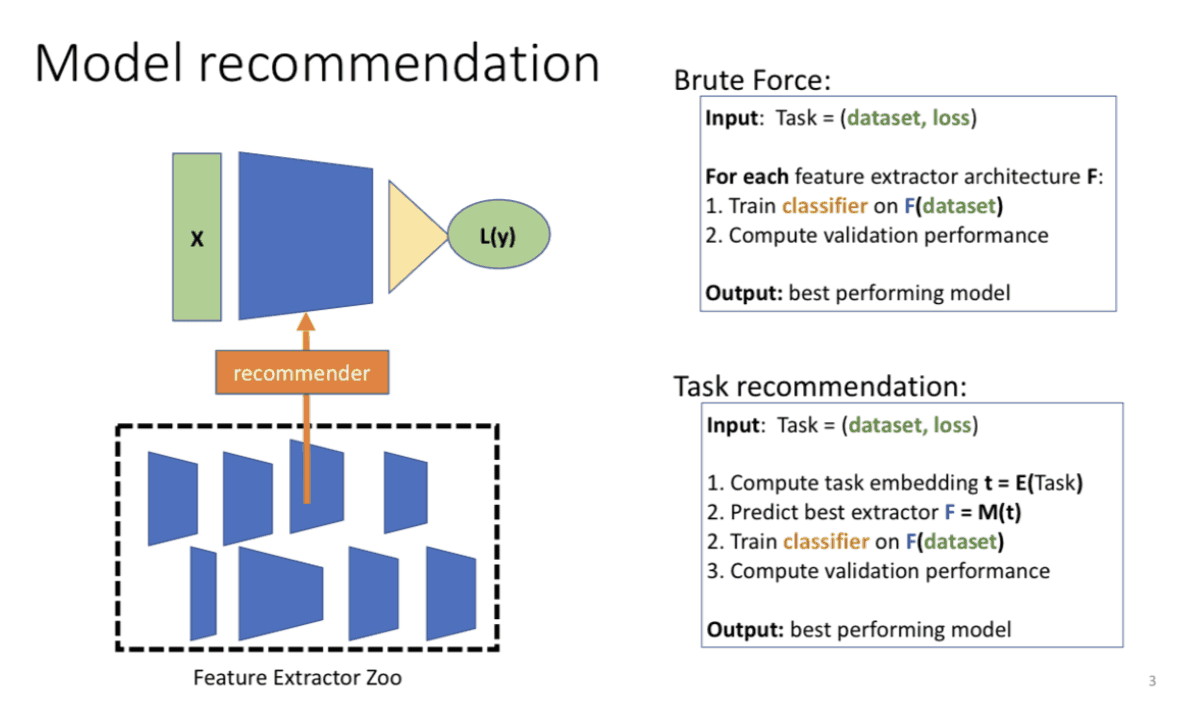
建议的方法
现在我们来看看提案法。所提出的方法包括三个步骤:
(一)用学习的模型计算目标数据集的虚标分布。
(ii)计算哑标z的条件概率$P(y|z)$。
3)根据虚标分布和$P(y|z)$计算LEEP。
我们将详细了解这些步骤。
(1)计算目标数据集与所学模型的虚标分布。
让$θ$成为一个训练模型。例如,$θ$是用Imagenet训练的模型。这个模型的输出表示z。我们也将目标数据集表示为D={(x1,y1),(x2,y2)...(xn,yn)}。在这里,我们使用$θ$来计算目标数据集的虚标分布$θ(xi)$。当然,$θ(xi)$与目标数据集的标签在语义上是无关的,因为我们没有对训练的模型进行任何改变。
(ii) 计算虚拟标签z的条件概率$P(y|z)$。
为了计算虚拟标签z的条件概率$P(y|z)$,我们首先计算y和z的同步概率分布。计算公式如下:
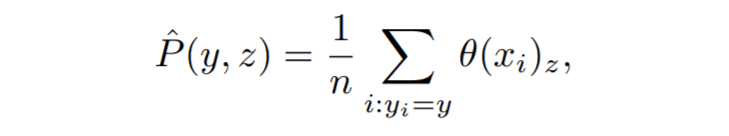
为了计算y和z的同步概率分布,我们是取满足yi=y的所有虚标分布之和。换句话说,我们是在计算给定标签y的数据的分布。如果我们能计算出同步概率分布,那么我们就可以按照贝叶斯定理计算出我们可以计算出条件概率$P(y|z)$。由贝叶斯定理可知条件概率$P(y|z)$可计算如下。
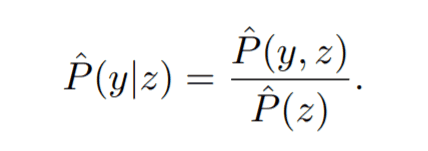 其中分母可由同步概率分布计算出如下结果
其中分母可由同步概率分布计算出如下结果
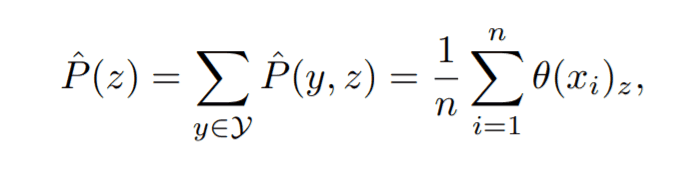 (3) 虚标分布并由$P(y|z)$计算LEEP。
(3) 虚标分布并由$P(y|z)$计算LEEP。
我们已经计算了$θ(x)$和$P(y|z)$,让我们考虑一个预测x的标签的分类器。首先,我们从虚拟标签分布中计算出标签z。然后,使用标签z由$P(y|z)$计算y。这意味着,$P(y|x,θ,D)$ = $ΣP(y|z)θ(x)$,相当于从概率分布中计算y(Σ为所有z的计算结果。)LEEP的定义是取该EEP的日志,并对目标数据集进行平均。
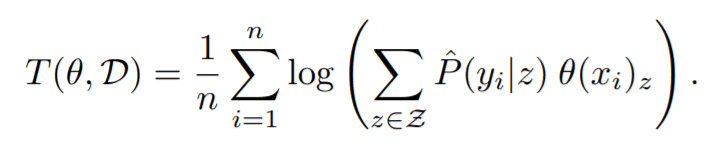
直观地讲,LEEP是在一个训练好的模型$θ$和一个目标数据集D上计算出来的,是衡量$θ$与D的接近程度,通过观察LEEP的理论属性,我们可以看到这部分的正确性。
理论上的考虑
首先,我们将$θ$分解为特征提取机制$ω$和分类器$h$。换句话说,$θ$=($ω$,$h$)。接下来,我们考虑只替换分类器部分,在D中重新训练。在这其中,我们考虑的是选择最佳分类器的问题。可以用以下公式表示:
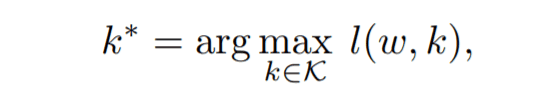
其中$l$是D中的平均对数似然,$K$是分类器k的集合。假设$K$包含EEP,则T($θ$,D)≤$l($ω$,k*)$-属性(1)。这意味着T($θ$,D)≤$l($ω$,k*)$-$l($ω$,k*)$为均值对数似然的最大值,且由于$T($θ$,D)包含在$K$中,所以性质(1)成立。这意味着LEEP是平均对数似然的最大值的下限。
以下属性说明了LEEP与最近公布的衡量可转移性的方法--负条件熵(NCE)之间的关系。对于目标数据集D中的每一个输入xi,我们计算虚标zi=argmax$θ(xi)$,其中Y=(y1,y2...yn),Z=(z1,z2...zn),如下。
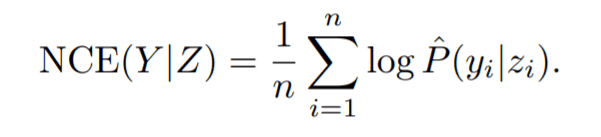
在这个NCE(Y|Z)和LEEP之间,T($θ$,D)≥NCE(Y|Z)+$Σlogθ(xi)$/n--属性(2)成立。(见原论文附录的说明。)由性质(1)和(2)可知,LEEP是D中最优模型($ω$,k*)的平均对数似然,而NCE(Y|Z)+$Σlogθ(xi)$/n.由于已知均值对数似然与模型的精度相关,而且更被证明比NCE更接近均值对数似然(在NCE研究中得到了证明),我们可以证明LEEP与模型的精度有一定的相关性。
实验
LEEP与传输精度
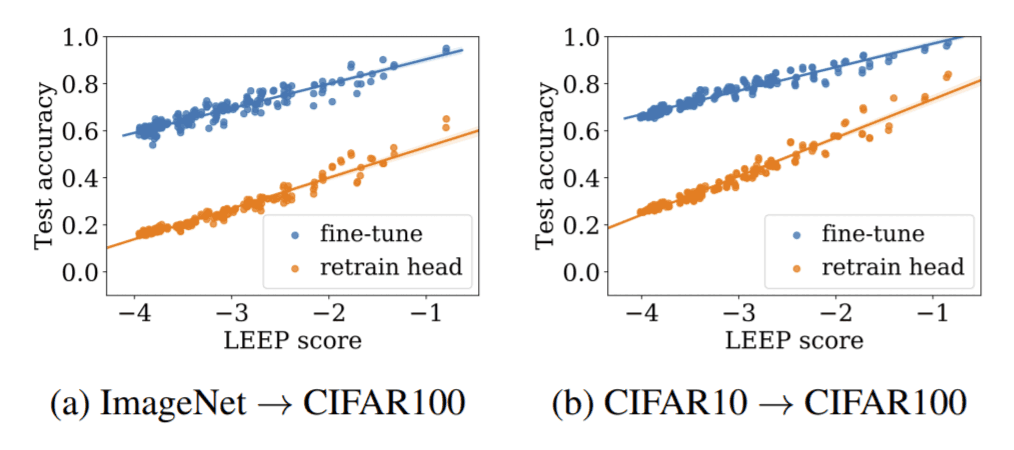
在本实验中,我们使用在ImageNet上训练的ResNet18和在CIFAR10上训练的ResNet20作为训练模型。我们将这两个模型转移到CIFAR100上进行训练。在这个实验中,我们比较了转移训练模型在200个不同任务上的准确率和LEEP(我们从CIFAR100中随机选择2~100个类,并对它们进行迭代,建立200个不同的数据集)。在本节中:他们正在试验两种类型的模型:Re-train head(只替换分类器,只重新训练分类器部分)和Fine-tune(替换分类器,重新训练整个模型)。见下图。可以看到,对于两个训练过的模型,LEEP的准确率和重新训练过的模型高度相关。
LEEP与微调模型的融合。
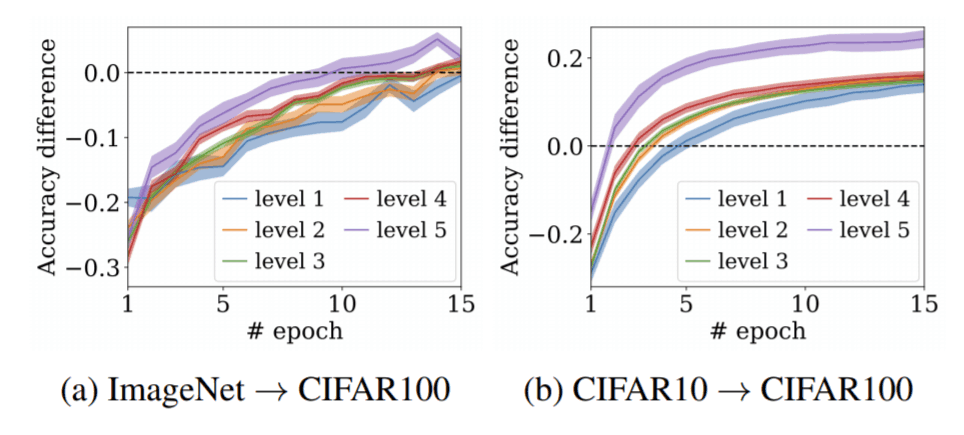
在接下来的实验中,我们使用LEEP来预测微调模型的收敛速度,为了衡量微调模型的收敛速度,我们从数据集中随机选择5个类作为Reference模型,并使用类中的所有样本从头开始训练。微调模型从CIFAR100中选取与上述相同的5个类,每个类用50张图片进行训练。请看下图。图中黑色虚线(0.0)是划痕模型与精调模型精度差为0的区域。另外,level1~5是指将LEEP的数值分为5个等级,等级越大,LEEP的数值越大。下图显示,当LEEP值越大,收敛速度越快。
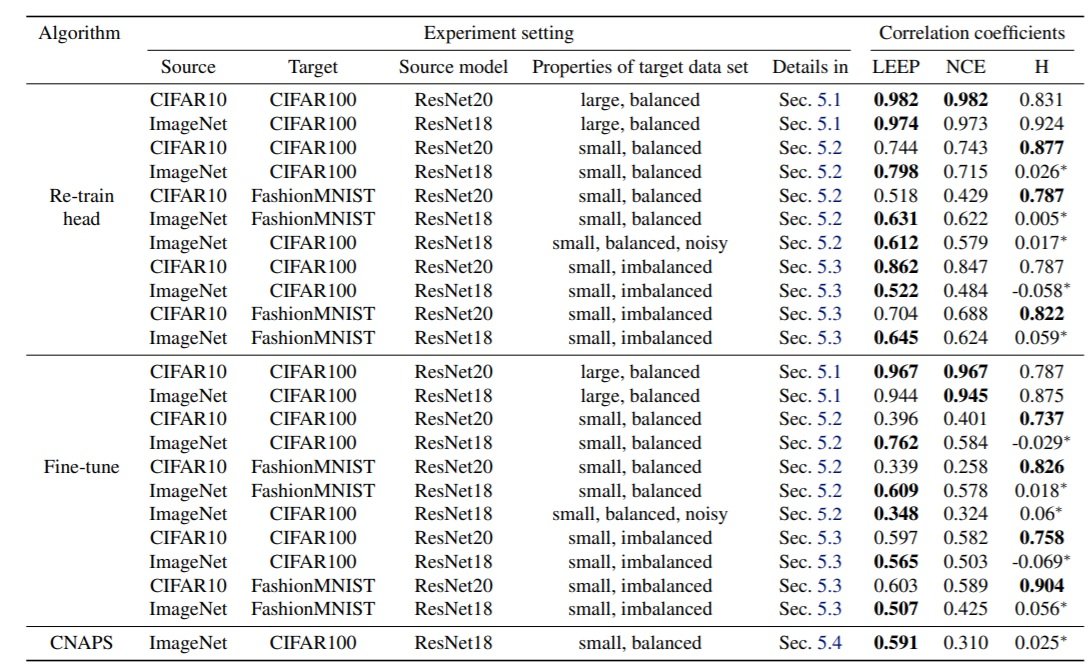
LEEP、NCE、H评分、CNAPS的比较。
在接下来的一组实验中,我们研究了转移学习的最新指标(NCE、H分数)和最新的元转移学习方法CNAPS和LEEP的数值之间的相关性。在这个实验中,对目标数据集D增加了限制:大表示使用整个数据集进行再训练,小表示只使用数据集的一部分进行再训练,imblanced表示在30~60之间改变每个类的样本数。从下面的数据可以看出,LEEP与最新的方法相比,表现出很高的相关性。
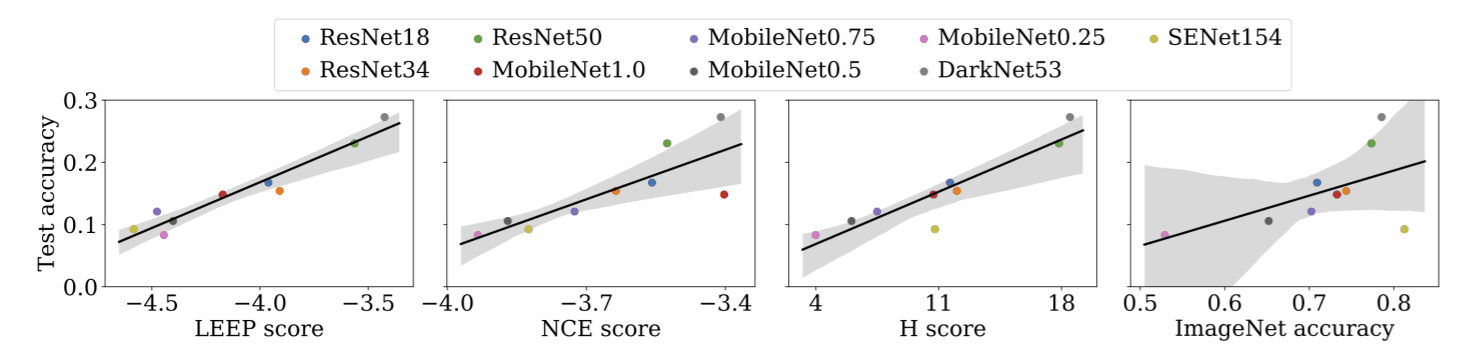
LEEP用于源模型选择
这就是本文的主题:利用LEEP进行模型选择。我们使用的训练模型有ResNet、MobileNet、SENet和DarkNet。从下图中可以看出,与其他方法相比,LEEP准确地预测了模型的准确性。换句话说,模型的准确度与LEEP值高度相关,所以如果使用LEEP值高的模型,预测再训练模型的准确度会很高。(例如,NCE不能很好地预测MobileNet1.0。
摘要
本文介绍的工作提出了一个度量标准LEEP,可以高效、高精度地预测最优学习模型。实验结果表明,9种不同模型的LEEP值分别为与每个模型的再训练精度高度相关。换句话说,通过使用LEEP,我们可以在有限的计算资源下选择一个次优的模型架构。因此,转移学习是深度学习模型使用中非常重要的技术。在这种转移学习中,这样一种可以不经过训练就能预测选择哪种学习模型的技术将非常有用。这是一个非常有趣的研究领域,你为什么不看看呢?



与本文相关的类别




