
事前学習済みモデルをGANに!? StyleGAN2-ADAをも凌ぐProjected GANとは!?
3つの要点
✔️ 最先端モデル「Projected GAN」について解説
✔️ 事前学習済みモデルの特徴表現をDiscriminatorに利用
✔️ FIDスコア・収束速度・サンプル効率全てで既存手法を凌駕
Projected GANs Converge Faster
written by Axel Sauer, Kashyap Chitta, Jens Müller, Andreas Geiger
(Submitted on 1 Nov 2021)
Comments: NeurIPS 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
Generative Adversarial Networks(GAN)は、画像生成をはじめとして大きな成功を収めていますが、学習の不安定さや膨大な計算コスト、ハイパーパラメータの調整などの様々な課題を抱えています。
本記事で紹介する論文では、Discriminatorに事前学習済みモデルの表現を適切に利用することで、生成画像の質・サンプル効率・収束速度を向上させ、StyleGAN2-ADAやFastGAN(本サイトの解説記事)を凌ぐ優れた結果を示しました。

提案手法(Projected GAN)
GANは生成器(Generator $G$)と識別器(Discriminator $D$)からなります。
ここで、$G$は単純な分布(通常は正規分布)$P_z$からサンプリングされた潜在ベクトル$z$から、対応するサンプル$G(z)$を生成します。
また$D$は、実サンプル$x~P_x$と生成されたサンプル$G(z)~P_{G(z)}$を識別するよう学習されます。
このとき、GANの目的関数は以下の式で表されます。

提案手法であるProjected GANでは、実画像・生成画像を識別器の入力空間に変換する特徴投影器(feature projectors)の集合$\{P_l\}$を導入します。このとき、先述した目的関数は以下の式で置き換えられます。

ここで、$\{D_l\}$は$\{P_l\}$内の異なる特徴投影器$P_l$に対応する識別器の集合となります。次に、生成器・識別器・特徴投影器のより具体的な構成について解説します。
モデルの概要
Projected GANのうち、生成器は既存のGAN手法(StyleGAN2-ADA、FastGANなど)のものを利用します。そのため、ここでは識別器$D_l$・特徴投影器$P_l$に焦点を当てて解説します。
マルチスケールの識別器
導入で説明したとおり、Projected GANは識別器に事前学習済みモデルの表現を利用します。
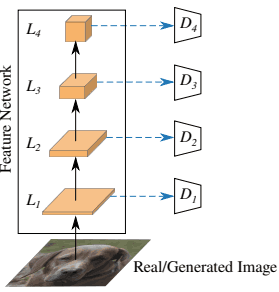
具体的には、事前学習済みのネットワーク$F$のうち4つの層(解像度はそれぞれ$L_1=64^2,L_2=32^2,L_3=16^2,L_4=8^2$)から特徴を得ます。そして、それぞれの解像度の特徴を特徴投影器$P_l$に通し、シンプルな畳み込みアーキテクチャを対応する識別器$D_l$として導入します。大まかには以下のような構成となります。
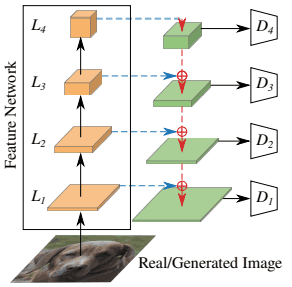
この図のように、事前学習済みモデルの各層の表現$L_1,..,L_4$について、それを特徴投影器に通したものが対応する識別器$D_1,...,D_4$に入力されます。また、識別器$D_l$は(ダウンサンプリング層の数を調整することで)出力解像度が全て$4x4$に設定されており、これらのロジットは合計されて全体の損失が計算されます。
また、識別器のアーキテクチャは以下の通りです。

表について、DB(DownBlock)はカーネルサイズ4、ストライド2の畳み込みとBatchNorm、LeakyReLU(傾き0.2)からなります。また、全ての畳み込み層にspectral normalizationが適用されています。
ランダムな特徴投影器
次に、特徴投影器は二つの要素、CCM(Cross-Channel Mixing)・CSM(Cross-Scale Mixing)からなります。これらはランダムかつ固定されており、学習時に更新されることはありません(学習時にはGeneratorとDiscriminatorのみが更新されます)。
・CCM(Cross-Channel Mixing)
CCM(Cross-Channel Mixing)は、事前学習済みのモデルから得られた特徴に対し、$1x1$のランダムな畳み込み演算を行い、チャンネルレベルで特徴をミックスします。これは、以下の図における青い矢印に対応します。
この畳み込み層の重みは、Kaiming 初期化によってランダムに初期化されます。
・CSM(Cross-Scale Mixing)
CSM(Cross-Scale Mixing)は、以下の図で表されるように、異なる解像度の特徴をミックスするような$3x3$の畳み込み層とBilinearアップサンプリング層による処理からなります。
CSMは図の赤い矢印に対応します。この処理を追加することにより、アーキテクチャはU-Net様になります。
重みはCCMと同様ランダムに初期化されます。
事前学習済みモデルについて
特徴表現抽出に用いる事前学習済みモデルとしては様々なモデルが考えられますが、元論文での実験では以下のモデルが利用されています。
これらのうち、最も良好な結果を示したのはEfficientNet(lite1)であったため、言及がない場合はEfficientNet(lite1)を採用しています。
実験結果
最先端のモデルとの比較
実験でははじめに、既存の最先端GANモデルとの比較結果について紹介します。ここでは、StyleGAN2-ADA、FastGANをベースラインとして比較を行います。
評価指標にはFID(Fréchet Inception Distance)を利用します。(元論文の付録では、KID、SwAV-FID、precision and recallなどの異なる評価指標についての結果も報告されています。)
・収束速度とサンプル効率
まず、LSUN-ChurchとCLEVRデータセットにおける収束速度・サンプル効率について比較します。このとき、収束速度についての比較結果は以下の通りです。
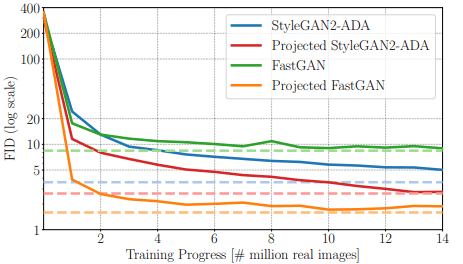
図について、Projected StyleGAN2-ADA・Projected FastGANは、Generatorとして対応するアーキテクチャを利用したProjected GANにあたります。
図の通り、FastGANは早期に収束しますがFIDスコアは高い値で飽和してしまいます。StyleGAN2-ADAは収束が遅いですが、FIDは低い値にまで下がります。提案手法であるProjected GANは、収束速度・FIDともに良好であり、特にFastGANのアーキテクチャを利用した場合は顕著な改善が見られます。
驚くべきことに、88M枚の画像を学習させたStyleGAN2-ADAの性能(図の青い点線)を、Projected FastGANは1.1M枚の時点で達成しており、提案手法の有効性が明らかになったといえます。
その性能の高さから、以降ではFastGANのGeneratorに採用したモデルを提案手法とし、これをProjected GANと呼びます。次に、サンプル効率の比較は以下の通りです。
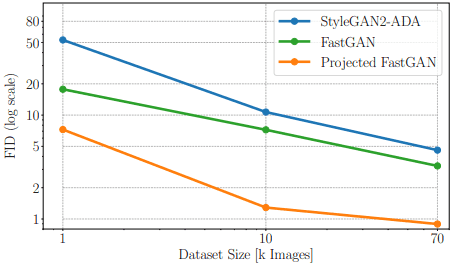
図の通り、データセットが小さい場合における性能についても、既存手法と比べて非常に良好であることが示されました。
・大規模・小規模データセットにおける比較
次に、様々な大きさ・解像度のデータセットにおける比較結果は以下の通りです。
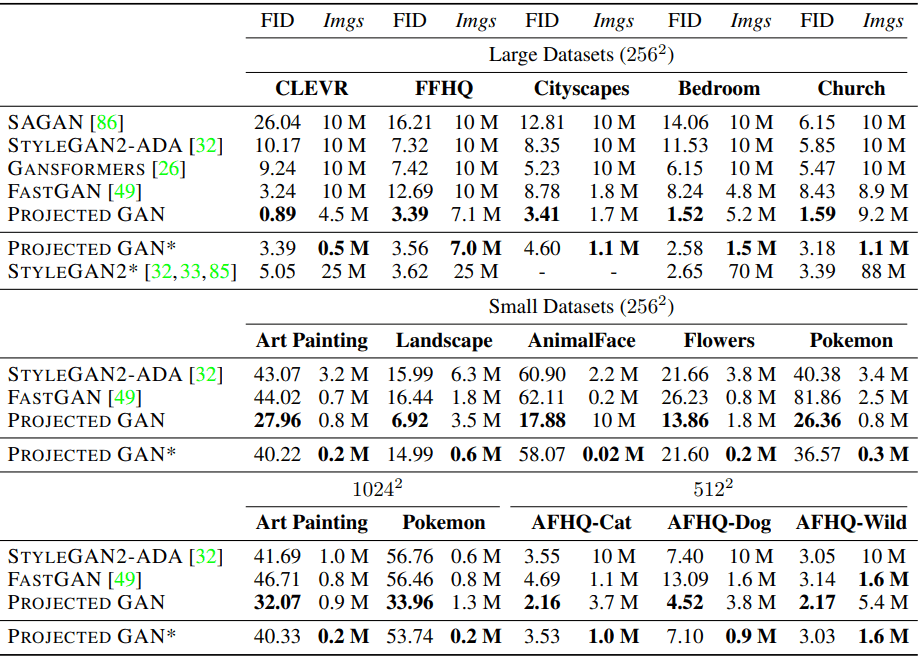
表のうち、PROJECTED GAN*は、提案手法が既存のモデルの最高性能を超えるタイミングを示しています。
例えばCLEVRでは、0.5M枚の画像を学習させた時点で、過去の文献における最も低いFIDスコアを凌駕したことが示されています。
表の通り、大規模・小規模データセット(Large/Small Datasets)、解像度($256^2,512^2,1024^2$)のどの場合についても、提案手法はFIDスコア・データ効率ともに既存手法を大きく上回る結果を示しました。
また、事前学習済みモデルとして、ImageNetで学習させたEfficientNetが一貫して利用されているにも関わらず、様々なデータセットで良好な結果が得られています。これは、ImageNetで学習させたモデルの特徴の汎用性を表しているといえます。
アブレーション研究
以降ではアブレーション研究を行います。はじめに、特徴抽出器として用いる事前学習済みモデルの比較結果は以下の通りです。

表の通り、ImageNet top-1精度とFIDスコアとの相関は小さいようで、EfficientNet-lite1が最も良好な結果を示しました。比較的小規模なモデルでも高い性能を発揮できることは、全体の計算コストを削減する上で有益な特徴であるといえます。
また、識別器・特徴投影器についてのアブレーション結果は以下の通りです。
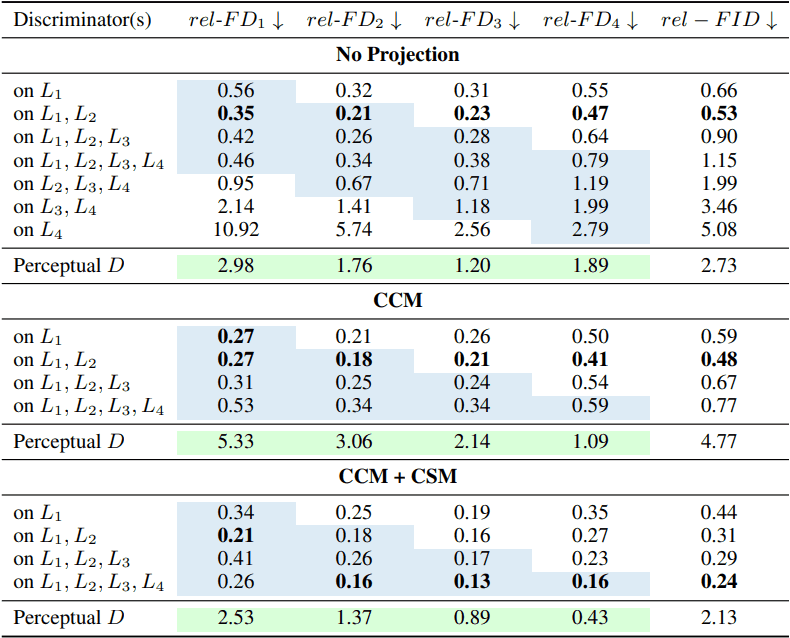
総じて、マルチスケールの特徴を利用すること、CCM・CSMからなる特徴投影器を利用することで、より優れた結果が得られることが示されました。
まとめ
StyleGAN2-ADAのような既存の最先端GANモデルは、学習に莫大な計算コストを要するなどの課題を抱えています。
本記事で紹介した論文では、事前学習済みモデルの特徴を利用することにより、生成画像の質・サンプル効率・収束速度全てについて、既存の最先端モデルを大きく上回る結果を示しました。
この結果は、より優れた画像生成を実現したのみではなく、大きな計算資源を持たない人々にとっても、最先端のGANモデルを作成・研究することを可能にしたといえます。ただし、提案手法は以下の図のように、顔以外の部分がうまく生成されなかったり、アーティファクトを含む画像が生成される場合もあります。


このような課題も残されていますが、提案手法のような効率・質ともに優れたGANモデルの出現は(ディープフェイク等の悪用リスクが高まる可能性もあるとはいえ)より多くの人々がこの領域の成長に携わることにも繋がり、非常に重要・有益な研究だと言えるでしょう。
公式コードも公開されているため、元論文と合わせて確認してみてはいかがでしょうか。



この記事に関するカテゴリー






