
LATMがLLMを使って、機能拡張ツールを生成、実行します
3つの要点
✔️ LLMを外部のツールと組み合わせて能力を拡張することが行われていますが、LLM自身にこのツールを生成させることにより、より広い範囲で柔軟に能力拡張することをめざしています
✔️ LATMは、ツール生成、ツール利用およびツール選択の部分を持ち、ツール生成とツール利用は、異なるLLMをしようすることができます
✔️ 強力なツールとなりえる一方、倫理、安全、制御に関する懸念もより深くなります。しかるべき手順を踏んで、用途が広がることが望まれます
Large Language Models as Tool Makers
written by Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, Denny Zhou
(Submitted on 26 May 2023)
Comments: Code available at this https URL
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (stat.ML)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
最近の研究では、外部ツールの利用により大規模言語モデル(LLM)の問題解決能力を向上させる可能性が示されています。しかし、この分野の先行研究は、既存のツールの利用可能性に限定されています。本研究では、LLMs As Tool Makers (LATM)と呼ばれる、LLMが問題解決のための再利用可能なツールを独自に作成するクローズドループフレームワークを提案することにより、この制限を取り除くための最初の一歩を踏み出します。著者らのアプローチは、2つの重要なフェーズから構成されています:
1) ツールの作成:LLMは、与えられたタスクのためのツールを作成するツールメーカーとしての役割を果たします(ツールはPythonの実用関数として実装されています)
2) ツールの使用:LLMは、ツールメーカーによって作られたツールを問題解決に適用するツールユーザーとして活動します。ツール使用者は、ツール製作者と同じLLMであることも、異なるLLMであることも可能です。
ツール作成により、LLMは異なる要求に適用可能なツールを継続的に生成し、将来の要求がタスク解決に有益な場合に対応するAPIを呼び出すことができます。さらに、ツール作成段階とツール使用段階のLLM間の分業は、生成されたツールや問題解決の品質を低下させることなく、費用対効果を達成する機会を導入するものです。例えば、ツール作成にはツール使用よりも高度な能力が要求されることを認識し、ツール作成者には強力だがリソースが必要なモデルを、ツール使用者には軽量だがコスト効率の良いモデルを適用することができます。著者らは、Big-Benchタスクを含む様々な複雑な推論タスクにおいて、本アプローチの有効性を検証しました。GPT-4をツールメーカー、GPT-3.5をツールユーザーとした場合、LATMはツールメーカーとツールユーザーの両方でGPT-4を使用するのと同等の性能を達成し、推論コストは大幅に削減されました。
【記事著者注】githubでコードを確認すると非常に小さいことがわかります。ここで提案されているフレームワークはGPT-4などの既存のLLMを利用することで、より強力な能力を実現するものです。多く提案されているプロンプトエンジニアリングよりは、より幅広く、柔軟にタスクを実行するもののようです。AGIにもつながる画期的な提案の一つになるのではないでしょうか。使いやすいUIを被せれば、一般にも既存のLLMよりもさらに広く用途が広がると期待されます。
はじめに
大規模言語モデル(LLM)は、幅広いNLPタスクにおいて優れた能力を発揮しており、人工一般知能(AGI)のある側面を実現できる兆候さえ示しています。さらに、LLMを外部ツールで補強し、それによって問題解決能力と効率を大幅に向上させる可能性が明らかにされています。しかし、これらのツールを使う方法の適用可能性は、適切なツールがあるかどうかに大きく左右されます。人類の進化のマイルストーンから学んだ教訓によると、重要な転機は、人類が新たな課題に対処するために独自のツールを製作する能力を獲得したことでした。
本研究では、この進化論的概念をLLMの領域に適用するための初期研究を行いました。著者らは、LLMs As Tool Makers (LATM)と呼ぶクローズドループフレームワークを提案し、LLMsが新しいタスクに取り組むための再利用可能なツールを独自に生成することを可能にします。このアプローチは、2つの主要な段階から構成されています:
1) ツールの作成:ツールメーカーと呼ばれるLLMは、与えられたタスクに特化したツール(Python関数として実装)を設計します
2) ツールの使用: ツールユーザーと呼ばれる別のLLM(ツールメーカーと同じ場合もある)が、新しい要求を処理するためにツールを適用します
この2段階の設計により、LATMは各段階のジョブを最も適したLLMに割り当てることができます。具体的には、高度な能力を必要とするツール製作工程は、リソースは必要だが強力なモデル(GPT-4など)に割り当てることができます。一方、比較的単純なツール使用プロセスは、軽量でコスト効率の良いモデル(例:GPT-3.5ターボ)に割り当てることができます。このアプローチは、LLMの問題解決能力を高めるだけでなく、一連のタスクに対処するための平均計算コストを大幅に削減することができます。
ツール作成プロセスは、与えられた機能に対して一度だけしか実行する必要がないため、作成されたツールは異なるタスクインスタンスで再利用することが可能です。このアプローチは、複雑なタスクを処理するためのスケーラブルでコスト効率の高いソリューションへの道を開くものです。例えば、ユーザーがLLMに、(電子メールでの会話など)全員の都合がつくような会議のスケジュールを依頼するタスクを考えてみましょう。GPT-3.5ターボのような軽量モデルは、複雑な算術推論を伴うこのようなタスクにしばしば苦戦します。一方、より強力なモデル(GPT-4など)は、推論コストが非常に高くなるにもかかわらず、正しい解を見つけることができます。LATMは、このようなハードルを克服するために、強力だが高価なモデルをツールメーカーとして採用し、それをツールユーザーとして費用対効果の高いモデルに渡して、その後の使用を可能にします。ツールが作られた後、軽量なツールのユーザーはそれを使って、高いパフォーマンスで効率的にタスクを解決することができます。このパラダイムは、ウェブ文書を特定のデータ形式に解析したり、いくつかのカスタム要件を満たすルーティングプランを策定したり、24のゲームである数独のような人気のあるゲームを解くために使用するなど、様々なワークフローにおける反復タスクに同様に適用することができます。
さらに、もう一つの軽量LLMであるディスパッチャーを導入し、入力された問題が既存のツールで解決可能か、新しいツールを作成する必要があるかを判断するようにしました。このディスパッチャによって、フレームワークにさらなるダイナミズムが加わり、リアルタイムでオンザフライのツール作成と利用が可能になります。
著者らの実験では、いくつかの困難なBig-Benchタスクなど、さまざまな複雑な推論タスクでこのアプローチの有効性を検証しています。その結果、LATMは、より大規模なモデルと同等の性能を達成しながら、より費用対効果が高いことがわかりました。ツールの作成と使用における人間の進化的飛躍を模倣したこのLLMの斬新なアプローチは、LLMが生成したツールでの刺激により、コミュニティが成長する可能性を開くものです。
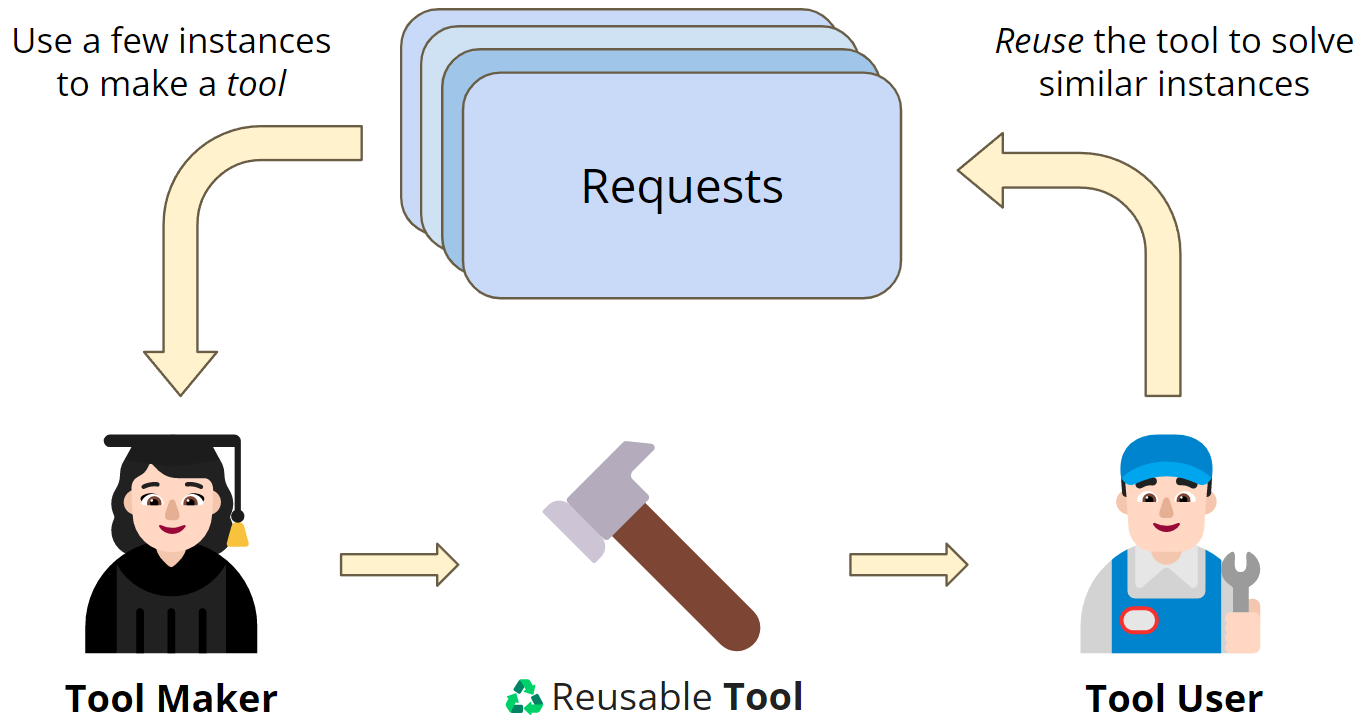
| 図1 LATMのクローズドループのフレームワーク 多数の問題解決要求がある状況では、すべてのインスタンスを解決するために強力なLLMを直接利用すると、高いコストになることがあります。一方、軽量なモデルは費用対効果が高いが、複雑なタスクに対応できないのが普通です。LATMは両モデルの長所を活かし、強力なモデルをツールメーカーとし、リクエストで観測されたタスクに対して再利用可能なツール(Python関数として実装)を生成し、次のリクエストで同様のインスタンスを解決するためにコスト効率の良いツールユーザーモデルにツールを渡します。このアプローチにより、軽量モデルは、より高いコスト効率を維持しながら、強力モデルに匹敵する性能を達成することができます。 |
関連研究
思考の連鎖 (CoT)
近年、大規模言語モデル(LLM)の複雑なタスクに対する問題解決能力を強化することに大きな進展がありました。例えば、CoTプロンプトは、LLMの推論能力を強化するために提案されており、様々な推論および自然言語処理タスクにわたってパフォーマンスの向上を示しています。CoTプロンプトは通常、自然言語を通じて表現されますが、プログラミング言語を使って効果的に表現されることもあります。さらに最近では、複数の合成関数からの抽出をアンサンブルすることで品質とコストのバランスをとりながら、LLMを使用して文書上の構造化ビューを生成する提案もあります。LATMでは、これに倣ってコストと品質のトレードオフを管理しつつ、より一般的なユースケースに焦点を当てています。
言語モデルをツールで拡張
最近の研究では、複雑なタスクに対するLLMの能力を補完するために、外部ツールを使用する可能性が検討されています。Yaoらや、Yangらは、LLMのタスク固有のアクションで推論トレースを補強し、モデルが推論して相乗的に行動することを可能にさせることを提案しました。様々な研究により、LLMに電卓、検索エンジン、翻訳システム、カレンダー、または他のモデルのAPI呼び出しなどのツールを補うことにより、LLMだけでは容易に対処できないタスクを解決できることがわかっています。LATMでは、Pythonの実行ファイルを用いて、他のタスクインスタンスに対応するための再利用可能なツールを作成することができます。さらに、ツール作成者とツール利用者を分離することで、ほとんどの推論で軽量なモデルを使用することができ、LATMの効率と費用対効果を向上させることができます。
言語モデルにおける適応的な生成
さらに、最近の研究では、LLMのデコーディングを適応的に制御してテキスト生成効率を向上させる方法が提案されています。Speculative Decodingは、テキスト・トークンの生成を、より高速でありながら性能の低いモデルで迅速化する一方、生成されたトークンのスコアリングに使用することで、より大きくコストの高いモデルの性能を近似するという概念に基づいています。LATMでは、デコード手順を変更する代わりに、新しく生成されたツールをモデル間で転送することで、タスクを解決するLLMの性能と効率の両方を向上させます。
言語モデルのカスケード
最近、LLMが繰り返し相互作用を可能にし、複数のLLMを組み合わせてその能力をさらに拡張できることを示されました。また、Chenらは、最適なLLMの組み合わせを特定することで、精度を向上させながらコストを削減できることを実証しました。LATMでは、単にLLMをカスケードするのではなく、より大きなモデルによって生成された新しいツールを使ってよりよく対処できるタスクカテゴリを特定し、そのタスクカテゴリ内の個々の推論をより小さなモデルに割り当てます。
ツールメーカーとしてのLLM (LATM)
新しい道具を作り、それを再利用する
LATMパラダイムでは、主要なプロセスは「ツール作成」と「ツール使用」の2つの段階に分けることができます。各段階では、性能と費用対効果のバランスを取るために、異なる種類の大規模言語モデル(LLM)を利用します。
ツール作成
- ツール提案: この段階では、ツールメーカーは、与えられたタスクからデモを解決するためのPython関数を生成しようとします。このプロセスは、いくつかの具体的なデモンストレーションを提供し、モデルがデモンストレーションされた動作を生成するプログラムを書きます。
- ツールの検証: 検証用サンプルを用いて単体テストを生成し、提案ツール上でテストを実行します。これらのテストのいずれかに失敗した場合、ツールメーカーはそのエラーを履歴に記録し、ユニットテスト内で問題の修正を試みます。LLMのセルフデバッグ能力は、最近の研究で効果的に実証されています。しかし、LATMパイプラインの中で、検証ステージは少し違った使い方をします。
1)自然言語の質問を関数呼び出しに変換する方法を示す例を提供する
2)ツールの信頼性を検証し、プロセス全体を完全に自動化できるようにする
です。
- ツールの包装 実行または検証があらかじめ設定された閾値を超えて失敗した場合、ツール作成ステージは失敗とみなされます。そうでない場合は、ツールメーカーがツールユーザーのために包装されたツールの準備が整いました。この段階では、関数コードを包装し、タスクを関数呼び出しに変換する方法のデモを提供します。これらのデモンストレーションは、質問をユニットテストに変換するツール検証のステップから抽出されます。この最終製品は、ツールユーザーが使用できるようになります。単語のソーティングの例を引用します。
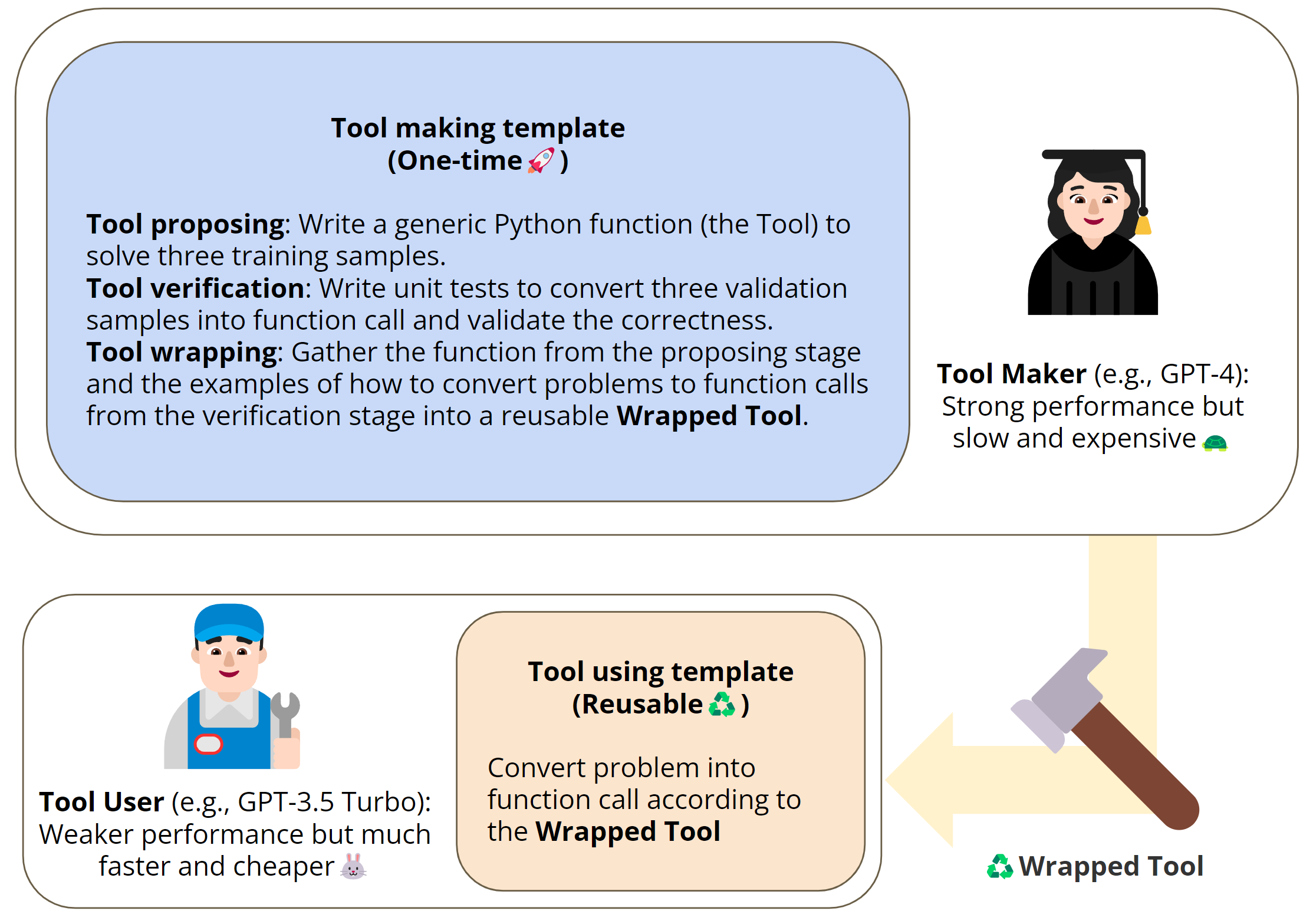
| 図2 LATMのパイプライン LATMは2つのステージに分けられます: 1)ツール作成:強力だが高価なモデルが、いくつかのデモンストレーションから汎用的で再利用可能なツールを生成するツールメーカーとしての役割を果たす。2)ツール使用:軽量で安価なモデルが、タスクの様々なインスタンスを解決するためにツールを使用するツールユーザーとして機能する。(i)ツールの提案:ツールメーカーは、いくつかのトレーニングデモからツール(Python関数)の生成を試み、ツールが実行できない場合は、エラーを報告して新しいものを生成する(関数の問題を修正する); (ii) ツールの検証: ツールメーカーが検証サンプルに対してユニットテストを実行し、ツールがテストに合格しない場合、エラーを報告して新しいテストを生成する(ユニットテストの関数呼び出しの問題を修正する)(iii)ツールの包装:関数コードとユニットテストから質問を関数呼び出しに変換する方法のデモを包装して、ツールユーザーに使えるツールを準備。 |

ツール利用
この第2段階では、GPT-3.5ターボのような軽量でコストパフォーマンスの高いモデルが、ツールユーザーの役割を担います。ツールユーザーの役割は、検証されたツールを使って、さまざまなタスクを解決することです。この段階では、タスクを解決するための関数と、タスククエリを関数呼び出しに変換する方法を示すデモを含む包装ツールを使用します。このデモンストレーションにより、ツールユーザーは、文脈内学習方式で必要な関数コールを生成することができます。その後、関数コールが実行され、タスクが解決されます。オプションで、出力をタスクの要求形式(多肢選択式問題の選択肢など)に合わせて変換する後処理を行うことも可能です。
ツールの提案、検証、包装を含むツール作成段階は、タスクの種類ごとに1回だけ実行すればよいです。そして、出来上がったツールは、そのタスクのすべてのインスタンスに対して再利用することができます。これにより、LATMは強力なモデルのみを使用するよりも、大幅に効率的で費用対効果が高くなります。さらに、Python関数ツールはChain-of-Thoughtのものより一般的な形式であり、アルゴリズム推論能力を伴う問題の解決に使用できるため、LLMの全体的な実用性と柔軟性を向上させることができます。
図3は、本方法を説明するために、BigBenchの論理的推論タスクを、ツールメーカーがツール(Python関数)を作成することで解決し、ツール利用者がそのツールを利用する様子を具体例として示しています。このタスクでは、5つのオブジェクトの順序を推論し、質問に答えることが要求されます。その条件には、図3の「ツールメーカーインプット」ブロックに示されるように、特定のオブジェクトペアの相対位置と、いくつかのオブジェクトの絶対位置の両方が含まれます。このタスクを解決するために、ツールメーカー(例えばGPT-4)は、質問から制約を抽出し、その結果に対してすべての順列を検索することによってタスクを解決する汎用プログラムを生成します。ツールユーザー(GPT-3.5ターボなど)は、このプログラムを利用して、タスクの自然言語インスタンスから関連情報を抽出するだけの関数呼び出しで、タスクを解決することができます。
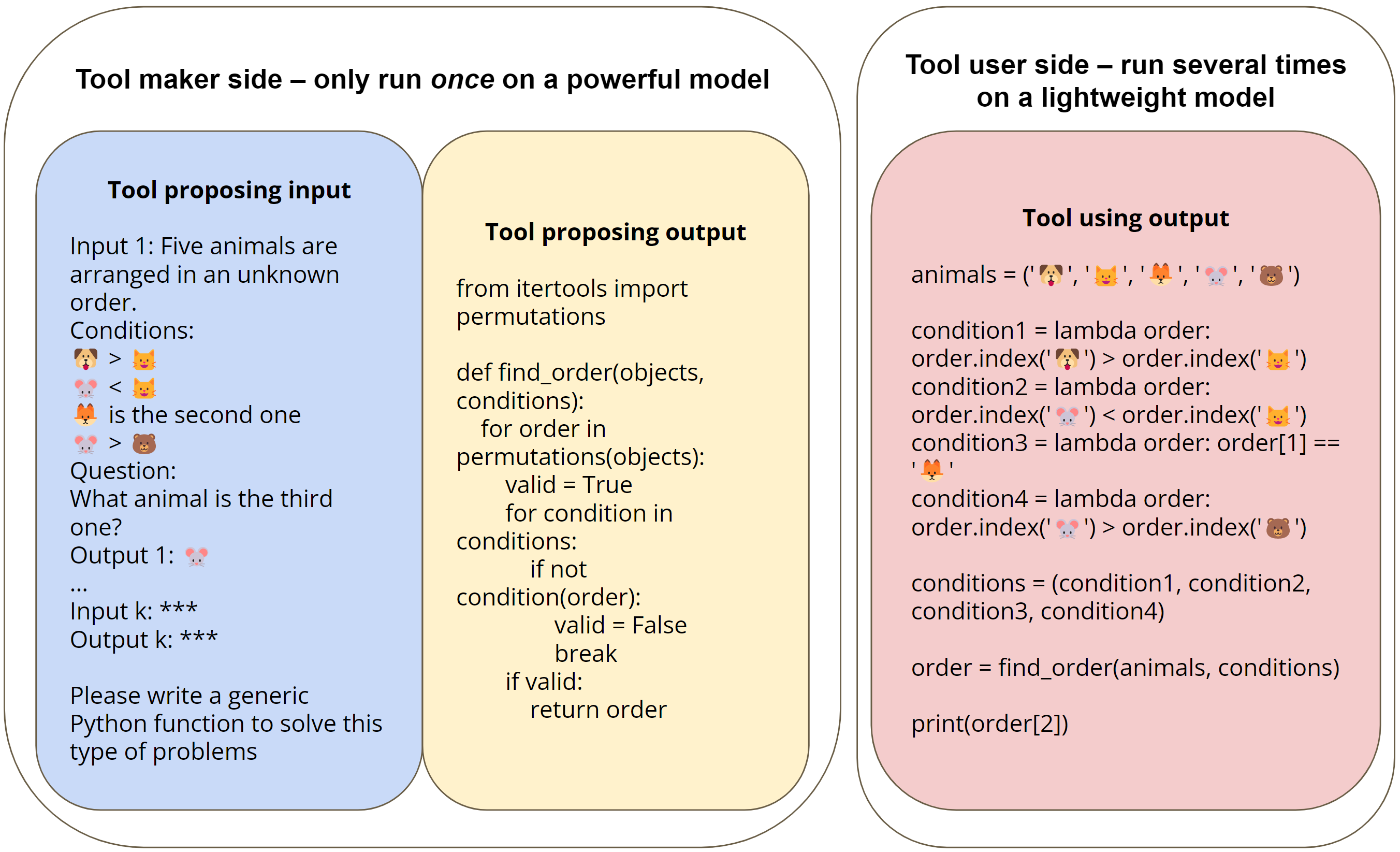
| 図3 論理的推論タスク[Srivastava et al, 2022]のLATMパイプラインのツール提案段階とツール使用段階の説明図 このタスクでは、いくつかの与えられた条件に基づいて、5つのオブジェクトの順序を決定する必要がある。ツール提案ステージでは、ツールメーカー(GPT-4など)が、タスクから提供されたk個の実証を解くことができる汎用Python関数を定式化します(著者らの実験ではk=3です)。ツールメーカーは、すべての可能な順序を列挙し、提供された条件に対してそれぞれを検証する検索アルゴリズムを生成します。ツール使用段階では、ツールユーザーは、各自然言語の質問を一連の条件に変換し、各タスクインスタンスに対してツールを利用するための関数呼び出しを生成します。 |
Dispatcherでストリーミングデータを扱う
実世界のシナリオでは、タスクインスタンスは通常、順番に到着します。このようなデータの流れに対応するために、著者らは第3のLLMであるディスパッチャーを導入し、到来する各タスクに対して、ツールユーザーとツールメーカーのどちらに従事するかを決定します。このモジュールは、既存の研究にあるツール選択機能に類似しています。しかし、著者らのディスパッチャーは、既存のツールでは対応できない新しいタスクを特定し、これらのタスクのための新しいツールを生成するためにツールメーカーを関与させる能力を持っているのが特徴です。
具体的には、ディスパッチャは、ツールメーカーが作製した既存のツールの記録を保持します。新しいタスクインスタンスが受信されると、ディスパッチャは、最初に、目下のタスクに適したツールが存在するかどうかを判断します。適切なツールが存在する場合、ディスパッチャは、タスク解決のために、インスタンスとそれに対応するツールをツールユーザーに渡します。適切なツールが見つからない場合、ディスパッチャはそのインスタンスを新しいタスクとして識別し、強力なモデルでインスタンスを解決するか、あるいは人間のラベラーを呼び出します。新しいタスクからのインスタンスは、ツールメーカーが新しいツールを作るために十分なキャッシュインスタンスが利用できるようになるまで、キャッシュされます。ディスパッチャーのワークフローは図4に示されています。ディスパッチャのタスクが単純であることから、ディスパッチャは適切なプロンプトを備えた軽量モデルとすることができ、パイプライン全体にわずかなコストを加えるだけです。LATMのプロンプトの例を示します。

| 図4 ディスパッチャの説明図 タスクインスタンスが順次到着するオンライン環境では、軽量モデルであるディスパッチャーが、到着した各インスタンスを評価します。タスクに取り組むのに適したツールがすでに存在する場合、ディスパッチャはこのツールを選択し、解決のためにタスクインスタンスをツールユーザーに転送します。適切なツールが見つからない場合、ディスパッチャはタスクインスタンスをツールメーカーに転送し、ツールユーザーが後で使用できる新しいツールを作成させます。 |



実験
設定
データセット
論理的演繹、シャッフルされたオブジェクトの追跡、Dyck言語、単語の並べ替え、中国の残差定理、会議のスケジューリングなど、多様なドメインからの6つのデータセットでLATMを評価します。最初の5つのデータセットはBigBenchから提供されたものです。Logical DeductionとTracking Shuffled Objectsタスクの5オブジェクト版を利用し、論文ではLogical Deduction(5)とTracking Shuffled Objects (5)と呼んでいます。また、実世界のシナリオにおけるLATMの有効性を実証するために、Scheduling Meetingタスクを構築しました。

| 表1 ツールメーカーが課題を解決するために生成する効用関数。 |
モデル設定
ツール作成段階では、生成プロセスにランダム性を導入するため、Temperatureを0.3に設定し、必要に応じて再試行できるようにしました。この段階では、GPT-4とGPT-3.5のTurboモデルを使ってChatCompletion APIによる実験を行い、常にチャット履歴に応答を付加することでインタラクティブな体験を提供します。ツールを使う段階では、LLM APIの呼び出しは1回だけで、標準のCompletion APIでGPT-3タイプのモデルを使ったアブレーション研究も行っています。ツール使用時は、Temperatureを0.0に統一しています。ツール提案段階とツール検証段階では、最大リトライ回数を3回に設定しました。
ツールメイキングステージの効果
ツール作成段階では、特定のタスクに合わせた汎用的なPython関数を生成するために、強力かつ低速なモデルを使用します。このステップは各タスクに対して1回だけ実行され、そのタスクのすべてのインスタンスにわたってオーバーヘッドが償却されます。この実験では、代表的なツールメーカーとして GPT-4を使用し、まだ他のモデルのツールメーカー機能も調査します。図3に示すように、言語モデルに対して、一般的なPythonプログラムを生成するように誘導し、いくつかの数ショットの模範を提供します。
GPT-4をツールメーカーとした場合、タスクの解決に適したアルゴリズムを頻繁に考案していることが確認できました。例えば、表1に示すように、ツールメーカーは、すべての順列を検索し、与えられた制約を満たす正しいものを選択することによって、論理的演繹タスクを解くためのコードを作成します。
LATMが軽量LLMの性能を向上させる
表2では、Chain-of-Thought promptingとLATMの性能を比較しています。6つのタスクのツールを生成するツールメーカーとしてGPT-4を採用し、ツールユーザーとしてGPT-3.5 TurboとGPT-4の両方の性能を評価します。その結果、ツールの助けを借りて、GPT-3.5 Turboのような軽量モデルがGPT-4と同等の性能を達成し、CoTプロンプトを大幅に上回ることが実証されました。さらに、GPT-3.5 Turboをツールで使用する場合の平均コストは、GPT-4を使用する場合と比較してはるかに低くなっています。これは、LATMが軽量モデルの性能を向上させ、高価なモデルを採用するよりもコストを削減する効果があることを示すものです。興味深いことに、Dyck言語タスクでは、ツールユーザーとしてのGPT-3.5 TurboがGPT-4を上回ることさえあります。失敗事例を調査したところ、質問を関数呼び出しに変換する際に、GPT-4が問題の一部を不必要に解決してしまい、誤った関数出力を行ってしまうことがあることがわかりました。

| 表2 LATMとChain-of-Thought(CoT)の性能比較 LATM については,GPT-4 が作成したツールを GPT-3.5 Turbo と GPT-4 の両方が利用しました。その結果,LATM を適用することで GPT-3.5 Turbo の性能が大幅に向上し,特定のシナリオでは CoT を使用しました GPT-4 の性能を上回ったり一致したりすることがよくあることが示されました.最後の列は、n個のサンプルを処理するための全体的なコストを示しています。ここで,C は GPT-4 の 1 回の呼び出しのコストを,c は GPT-3.5 Turbo の 1 回の呼び出しのコス トを表しています.最初の 4 つのタスクの数発の CoT のデモは Suzgun らによって提供され,最後の 2 つのタスクは CoT なしで直接数発のプロンプトを適用しました. |

| 表2 GPT-4 v.s. GPT-3.5 Turboによるツール作成段階での新しいツール(ツール検証ステップを通過したPython関数)生成の成功率 各タスクに対して各モデルで5回の試行を行い、n/5は5回の成功のうち有効なツールを生成するためのn回の軌跡を意味します。論理的演繹やシャッフルされたオブジェクトの追跡のような難しいタスクでは、GPT-3.5 Turboはすべての試行で失敗し、ツールメーカーとしてより強力なモデルを使用する必要性を示しています。 |
LATMをタスクが混在するストリーミング環境へ拡張
LATMを、(潜在的に)異なるタスクからのインスタンスがオンザフライで到着するストリーミング設定に拡張することができます。この場合、インスタンスが属するタスクを決定するために、別のモデルであるディスパッチャが必要になります。GPT-3.5ターボをディスパッチャとして使用し、その能力を評価します:
1)入力されたインスタンスを解決するための既存のツールを特定する
2)未知のタスクからインスタンスのためのツール作成を要求する
既存ツールの洗い出し
まず、与えられたインスタンスに対して既存のツールを識別するディスパッチャの能力を評価します。6つのタスクをランダムに混合し、100個のサンプルを持つテストセットを生成します。テストセット内の各インスタンスについて、既存のツールに関連するタスク例を含むプロンプトを使用して、ディスパッチャーで適切な既存のツールを特定します。ツールが正しく識別された場合、成功したとみなします。テストセットの5つのランダムな構成で、正しいツールを決定する精度は94%±2%でした。
ツール製作を依頼する
次に、ディスパッチャが未知のタスクからのインスタンスに対してツール作成を依頼する能力を評価します。ツールが準備されている既存のタスクとして、4つのタスクをランダムに選択します。次に、テスト用に4つのタスクを選びます。2つは未知のタスク、2つは既存のタスクの中にあるタスクです。100個のサンプルでテストセットを作成します。テストセット内の各インスタンスについて、ディスパッチャを使用して、ツール作成を要求する必要があるか、既存のツールで解決できるかどうかを判断します。正しい依頼をする精度は95%±4%でした。
この結果から、ディスパッチャは、性能を大きく落とすことなく、既存のツールを効果的に識別し、未知のタスクに対してツール作成を要求できることがわかります。このことは、LATMがタスクが混在するストリーミング設定にスムーズに拡張できることを示唆しています。
切り分け分析
ツールを作る言語モデルに必要な容量
ツール作成段階で使用される言語モデルの容量要件を調査しました。一般に、この段階は各タスクに対して一度だけ実行され、より小さなモデルに効果的にツールを渡すためには高い精度が重要であるため、より強力で高価なモデルがより目的にかなうことがわかりました。具体的には、論理的演繹やシャッフルされたオブジェクトの追跡といった難しいタスクでは、GPT-3.5 Turboは5つのトレイルのすべてで失敗しました。そして、主な失敗理由は、ツールが十分に一般的でなく、トレーニングサンプルにしか使えない可能性があることです。一方、簡単なタスクでは、ツールメーカーが軽量な言語モデルになりうることも発見しました。単語ソートのような簡単なタスクでは、GPT-3.5ターボはタスクを解決するプログラムを難なく生成することができます。ツールメーカーの失敗の原因となりうるもう一つの制限は、文脈の長さの制約です。ツール作成段階の信頼性を高めるために、ツール作成の各工程で全履歴を使用するため、これも長い文脈が導入されます。この場合、8192のコンテキスト長を持つGPT-4が望ましいです。
ツール使用言語モデルに必要な容量
ツール使用モデルの容量要件を調査します。その結果を表 4 に示します。GPT-3.5ターボは、テストしたすべてのモデルの中で、性能とコストのバランスが最も優れていることが確認されました。また,GPT-3シリーズの古いモデル(ada,babbage,curie,davinci)については,命令チューニング前のモデルの方が,命令チューニング後のモデルよりも性能が高い場合があることがわかりました.このことから、これらのモデルでは、インストラクションチューニングの段階が、ツールを使う段階で重要なインコンテクスト学習能力に悪影響を及ぼしている可能性があると推測されます。

| 表4 GPT-4で生成された同じツールを使用した、各種ツールユーザーモデルの性能比較 コストはすべて執筆時のレートによるものです。すべてのモデルの中で、GPT-3.5 Turboは、性能とコストの間の最良のトレードオフを実証しています。GPT-3は命令チューニング前のモデルであり,命令チューニング後のモデルはツール使用段階でかなりパフォーマンスが低下することが確認されたため,命令チューニング前のモデルを選択しました。これは、インストラクションチューニングの段階で、ツール使用段階に不可欠なインコンテクスト学習能力が損なわれたためであると推測しています。 |
ツールとしてのCoTは役に立ちません
LATMに加えて、LATMパイプラインと同様に、より大きなモデルから小さなモデルへChain-of-Thought(CoT)を再利用することでタスクパフォーマンスを向上させることができるかどうかを調査しています。具体的には、「CoT作成」の段階で同じ大型モデル(GPT-4)を用い、ゼロショットプロンプト「Let's think step by step.」で中間思考ステップを引き出し、生成したCoTを同じ小型ツール使用モデル(GPT-3.5 Turbo)に利用するものです。これを2つのタスクでテストし、その結果を表5に報告します。大きなモデルからCoTを使用すると、人間が書いたCoTと同等か、LATMよりはるかに悪い性能であることが観察されます。

| 表5 GPT-4で生成したCoTを使用した場合の精度 人間が書いたCoTに近い性能であり、LATMよりはるかに劣ります |
まとめ
大規模言語モデル(LLM)が多様なタスクのために独自のツールを作成し、利用できるようにするクローズドループフレームワークであるLATMを導入しました。LATMのアプローチは、道具を作るという人間の進化的な進歩に触発されたもので、2つの重要な段階を採用しています: 「ツール作成」と「ツール使用」です。この分業化により、計算コストを大幅に削減しながら、高度なLLMの能力を活用することができます。著者らの実験では、様々な複雑なタスクにおいてLATMの有効性が確認され、このフレームワークがリソース集約型モデルに匹敵する性能を持ちながら、より費用対効果が高いことが実証されました。さらに、ディスパッチャーLLMをもう1つ追加することで、フレームワークに柔軟性を持たせ、その場でツールを作成・利用できるようになることも示しました。
評価プロセスでは、電子メールや電話による会議のスケジュールや航空券の予約など、日常的な人間とコンピュータのやり取りを生の自然言語フォーマットで忠実に表現する高品質のデータセットが著しく不足していることを確認しました。著者らは、このようなデータセットを作成することで、次世代のAIシステムを育成するための研究コミュニティが活性化することを期待しているとしています。このようなシステムは、独自のツールを生成して適用することができ、複雑なタスクをより効果的に処理することができるようになるでしょう。将来的には、ソフトウェア開発のように、ツールメーカーが既存のツールを改良し、新たな問題に対処できるようにすることも可能です。このような適応性は、AIのエコシステムの進化をさらに促進し、豊富な機会を引き出す可能性があります。
本論文では、大規模言語モデル(LLM)が独自のツールを作成できるようにすることで、エコシステムをより自律的に開発できるようになる可能性について検討しています。この研究手段は有望であるが、同時に倫理、安全、制御に関する重要な検討事項を提起しており、慎重に対処する必要があります。著者らの研究がもたらす最も大きな影響のひとつは、LLMが自動的に成長し、これまでにない能力を発揮できるようになる可能性にあります。これにより、LLMが処理できるタスクの範囲と複雑さが大幅に向上し、カスタマーサービスやテクニカルサポート、さらには研究開発の分野にも革命をもたらす可能性があります。また、計算機資源の効率的な利用や、特にルーチンワークや反復的な作業に対する人間の介入を減らすことにもつながります。しかし、LLMのこの新たな自律性は、諸刃の剣でもあります。LLMに独自のツールを開発する能力を与えることで、LLMが開発するツールの品質が、人間の開発者が設定した基準や期待に必ずしも合致しない可能性があるというシナリオも生まれます。適切な保護措置がなければ、LLMが最適でない、誤った、あるいは潜在的に有害なソリューションを生成する可能性があります。さらに、LLMがより自律的に動くようになると、制御不能になる可能性が高まります。適切な規制がないままこれらのモデルが広く使われるようになれば、予期せぬ結果が生じ、人間がAIシステムを制御できなくなるシナリオにつながる可能性さえあります。
本研究では、このような制御や安全性の問題に深く取り組んでおらず、従ってここでの研究にはいくつかの限界があるといえます。提案するフレームワーク「LLM As Tool Maker」は、テストしたシナリオでは効果的でしいたが、まだ開発の初期段階です。システムの実世界での性能と安全性は、適用されるタスクの複雑さと性質に基づいて変化する可能性があることに留意することが極めて重要です。さらに、ツールメーカーが作成したツールを実世界で評価・検証することは、取り組むべき課題である、としています。





この記事に関するカテゴリー






