
グラフ表現とSMILES表現の両方を用いた逆合成解析モデルGTA
3つの要点
✔️ 逆合成のタスクを扱う深層学習モデルとしてはsequence-to-sequence (seq2seq)やグラフニューラルネットワーク (GNN)に基づくものが主流であり、本論文ではこれらを融合したGraph Truncated Attention (GTA)を提案
✔️ GTAでは化学物質をグラフ表現と文字列表現の2つの表現として表し、両方の表現を利用した新しいgraph-truncated attention法によって逆合成を行いました。
✔️ 本モデルはUSPTO-50kベンチマーク、USPTO-fullデータセットで最先端の結果を達成
GTA: Graph Truncated Attention for Retrosynthesis
written by Seo, S.-W., Song, Y. Y., Yang, J. Y., Bae, S., Lee, H., Shin, J., Hwang, S. J., & Yang, E.
(Submitted on 18 May 2021)
Comments: AAAi2021
Subjects: Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
逆合成(Retrosynthesis)とは、逆反応経路を見つけることで与えられた生成物分子に合成される反応物分子群を予測するタスクです。特に有機化学においては合成経路を見つけることは新しい化合物を発見するのと同じくらい難しいため重要な課題です。逆合成の概念の登場以来、化学者は逆合成分析にコンピュータを用いて、高速かつ効率的な反応物候補の探索を試みています。
近年、様々な化学タスクで深層学習が成功を収めてきたことや、大規模データセットが公開されてきたことにより、深層学習を用いたデータ駆動型の方法で逆合成問題に取り組む研究が出現し始めています。この深層学習ベースのアプローチは人間の介入や事前知識・専門知識なしにタスクを解決する可能性があり、時間効率と費用効率の高いアプローチとなり得ます。最近の深層学習を用いた逆合成のアプローチはテンプレートベースとテンプレートフリーに分類できます。ここで言うテンプレートとは、原子単位のマッピング情報を使って、反応物質がどのように生成物に変化するかを記述したルールセットを指します。当然、テンプレートをモデルに反映させるためには専門知識が必要となりますが、そのおかげで現在の最先端のテンプレートベースモデルはテンプレートフリーモデルに比べて高い性能を示しています。しかし抽出されたテンプレートに含まれていない反応はテンプレートベースモデルではほとんど予測されないため、汎化能力に乏しいです。またテンプレートを実験的に検証するには7万テンプレートで15年かかるなど多くの時間が必要となる欠点もあります。データから直接学習するテンプレートフリーモデルは、抽出されたテンプレートを超えて汎化できる強みとテンプレートの検証に関する問題がないという強みがあります。最初に提案されたテンプレートフリーモデルは与えられた生成物の文字列表現から反応物の文字列表現を予測するseq2seqモデルが用いられました。Seq2seqモデルとして双方向LSTMやMulti-head self-attention、Transformerなどが使われています。現在も学習率スケジューリングを組み入れたり、潜在変数を追加するなどして改良が続けられています。グラフ表現を用いた最近のテンプレートフリーモデルはgraph-to-graph (G2Gs)と呼ばれます。G2GsはUSPTO-50kデータセットに対して最先端の性能を報告した一方、化学者がラベル付けした原子マッピングを必要とするなど、テンプレートベースのモデルと同様の手順をいくつか持ち、テンプレートフリーモデルの利点を活かしきれていませんでした。GTAモデルはこれらのモデルとは異なり、初めてグラフ表現と文字列表現の二重性に着目し、Transformerモデルにパラメータを追加することなく逆合成解析をしました。
表記
以下、$P$を生成分子、$R$を反応分子、$G(m)$を分子$m$のグラフ表現、$S(m)$を分子$m$のSMILES表現とします。SMILESはSimplified molecular-input lineentry systemの略で、分子を文字の列で表現する表記法で、分子特性予測や分子設計、反応予測などに広く利用されています。 例えばフランとエチレンからベンゼンを合成する反応は下図のように表記されます。
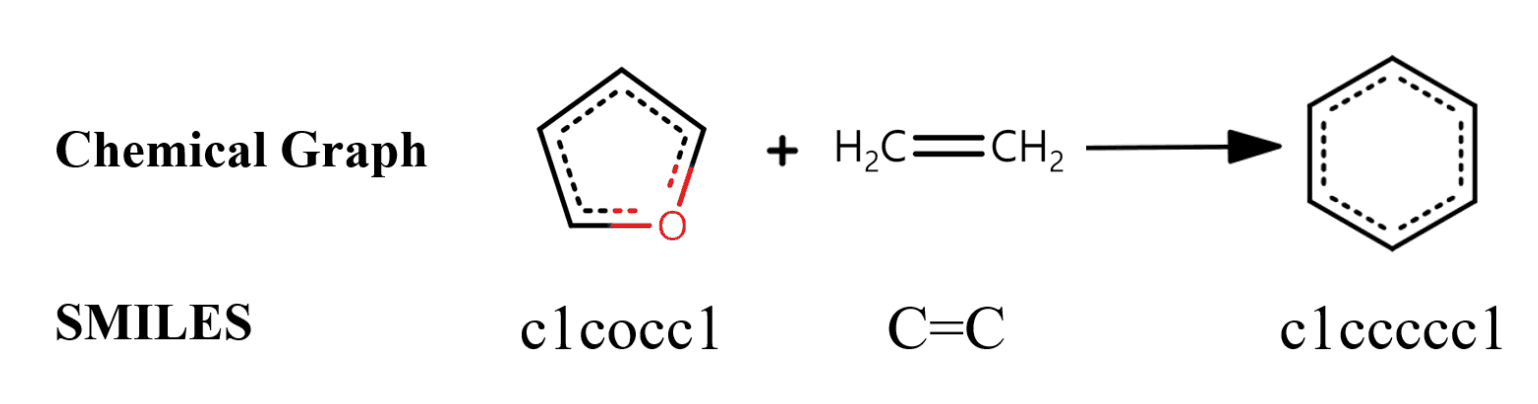
Transformer
Transformerはアーキテクチャは、self-attentionによってトークンの長距離依存関係を学習できるため、機械翻訳などの多数の自然言語処理タスクの解決に現在デファクトとなっています。逆合成タスクにおいてはMolecular Transformerが反応物の集合$\left\{R_1、R_2、\dots\right\}$から生成物$P$のSMILES表現上での「翻訳」タスクを行いました。Transformerは式で表わすと以下のようになります。
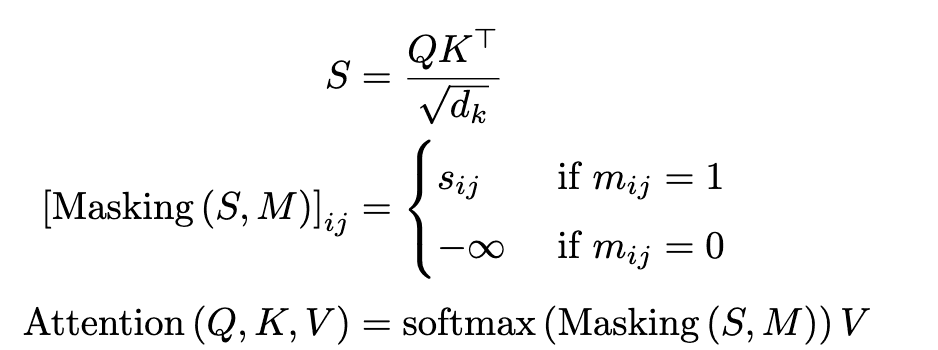
ただし、$Q\in\mathbb{R}^{T_m\times d_k}$、$K\in\mathbb{R}^{T_m\times d_k}$、$V\in\mathbb{R}^{T_m\times d_v} $は学習するパラメータ、$S=\left(s_{ij}\right)$はスコア行列、$M=\left(m_{ij}\right)\in\left\{0、1\right\}^{T_m\times T_m}$はマスク行列です。マスク行列$M$は各注意モジュールの目的に応じてカスタマイズします。
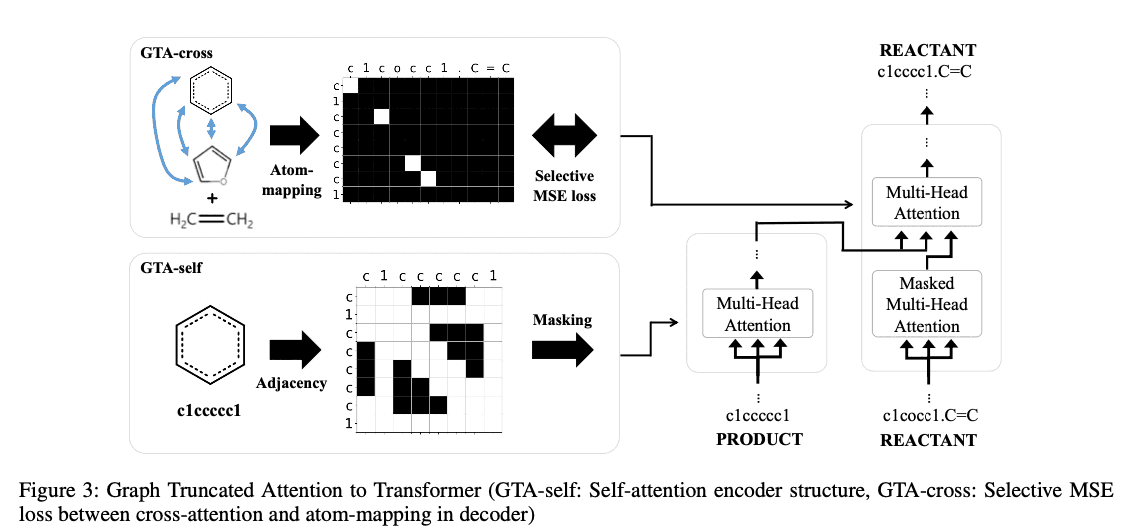
Graph-truncated attention
GTAの目的は、Transformerのself-attention、及びcross-attention層にグラフ構造の情報を入れることです。本研究では事前学習済み言語モデルにおけるマスクの利用の最近の成功に触発されて、グラフ情報から生成したマスクを用いて注意機構の計算を行います。GATではself-attention層でのマスクとcross-attention層でのマスクの2つを考えます。
Graph-truncated self-attention (GTA-self)
分子グラフ上の原子$i$と$j$間の距離が$d$である場合(あるいは原子$i$と$j$が$d$ホップ隣接である場合)、$m_{ij} = 1$とします。 $d$はハイパーパラメータであり、実験では$d=1,2,3,4$を使用しました。距離行列が$D=\left(d_{ij}\right)$と与えられれば$h$番目のヘッドに対応するマスクは
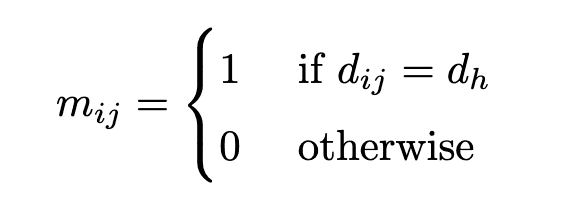
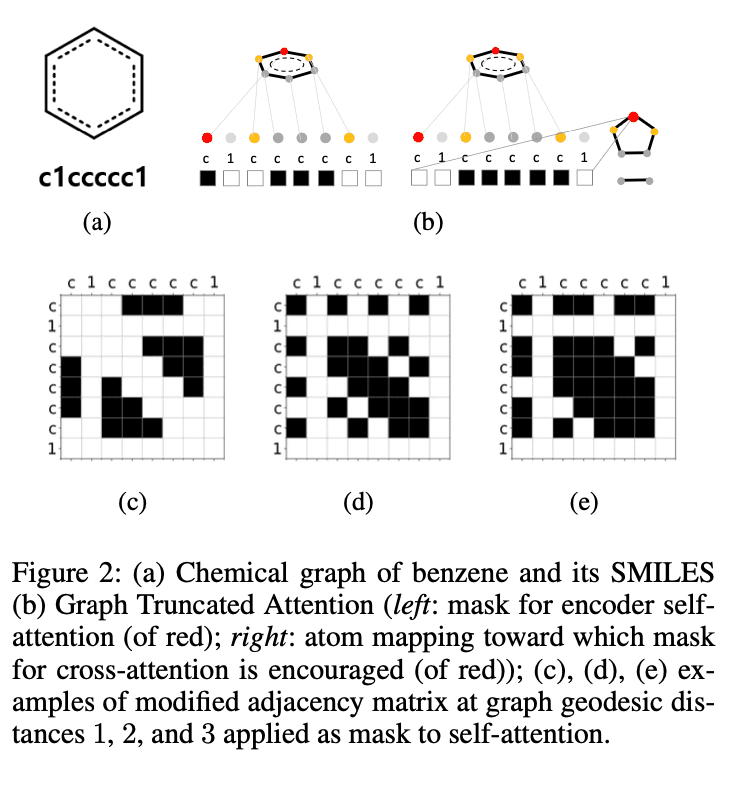
となります。すべてのヘッドが$d_h=1$であるときはGraph Attention Network (GAT)と同じになります。実験ではヘッドのインデックス$h$を用いて$d_h=\left(h\text{ mode }4\right)+1$と設定しました。例として、Figure 2の(b)の左にベンゼンの赤色の原子に対する$d_h=1$のマスクが示されています。
Graph-truncated cross-attention (GTA-cross)
反応は分子を完全に分解して全く新しい生成物を作る過程ではなく、生成物と反応物の分子は通常かなり共通の構造を持っています。したがってcross-attention層を考えるのは自然な考えです。しかし生成物と反応物間の原子マッピングをどのように行うかは容易ではなく、化学分野では活発な研究テーマとなっています。本研究では簡略化のため、標準的なRDkitで実装されたFMCSアルゴリズムを使用します。FMCSアルゴリズムで求めた生成分子と反応分子間の(部分的な)原子マッピングを元に、マスク$M=\left(m_{ij}\right)\in\left\{0,1\right\}^{T_R\times T_P}$を
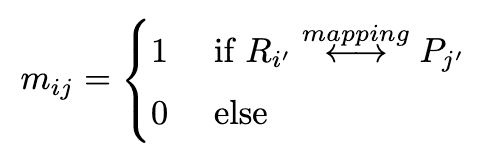
と定義します。ここで$i'$は$S(m)$の$i$番目のトークン対応するグラフ$G(m)$の頂点のインデックスであり、$R_{i'}$はグラフ$G(R)$の頂点、$P_{j'}$はグラフ$G(P)$の頂点を表しています。Figure 3に示すように、Cross-attention用のマスクは対応する原子が原子マッピングによってマッチングされた場合に1、それ以外の場合に0とします。ここで上式によって生成したマスクは、原子マッピングが不完全であるという点、推論時のシーケンス生成時に不完全なSMILESを作るという点で、マッピングを見つけることは困難です。よって徐々に完全な原子マッピングを学習するよう以下の損失関数を用いました。
$$\mathcal{L}_{\text {attn }}=\sum\left[\left(M_{\text {cross }}-A_{\text {cross }}\right)^{2} \odot M_{\text {cross }}\right]$$
ここで$M_{\text {cross }}$は上式で定義したマスク行列、$A_{\text {cross }}$はcross-attentionの行列です。
損失関数
最終的にGTAの全体的な損失は$\mathcal{L}_{\text{total}}=\mathcal{L}_{\text{ce}}+\alpha\mathcal{L}_{\text{attn}}$となります。GTA-selfの損失項がないように思われますが、GTA-selfによって生成されるself-attentionがモデルの出力を通じてクロスエントロピー損失$\mathcal{L}_{\text{ce}}$に寄与するので、GTA-selfの効果は暗黙的に組み込まれています。実験では$\alpha$は$1.0$としています。
実験結果
実験は化学反応のオープンデータセットであるUSPTO-50kとUSPTO-fullを用いました。
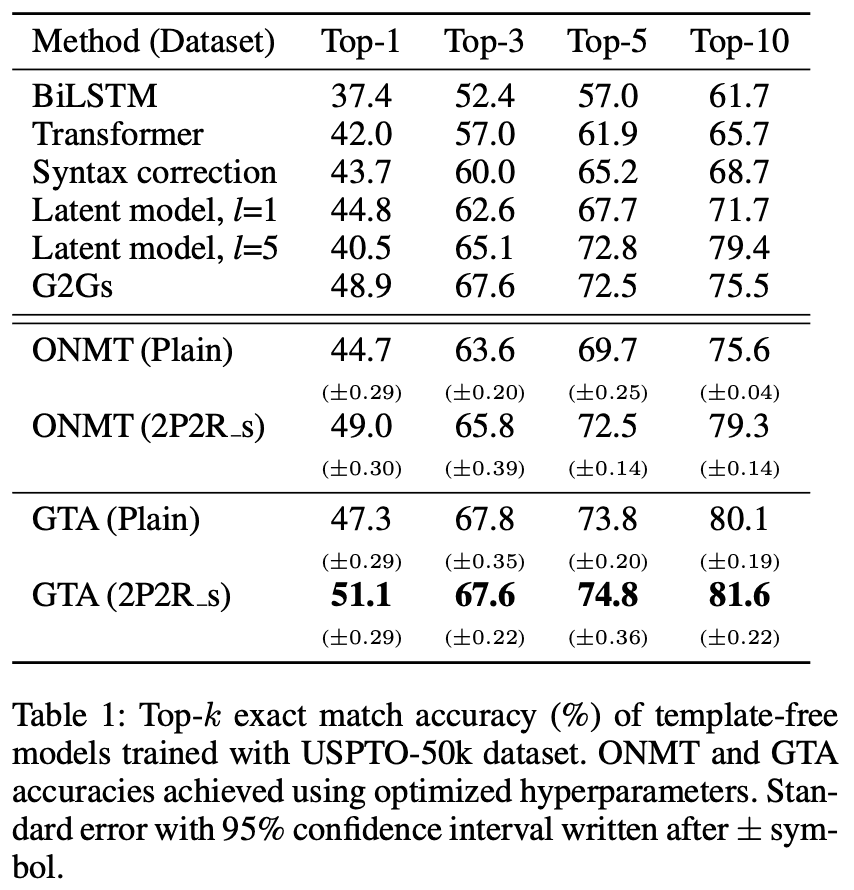
Table 1が既存のテンプレートフリーモデルとの比較、Table 2が既存のテンプレートベースモデルとの比較です。数値はTop-kの完全一致精度(%)、また$\pm$記号の後は95%信頼区間幅が記載されています。また反応物順序、出発原子を変更してデータ拡張して学習した場合を2P2R_sと書いています。
表からGTAはUPSTO-50kデータセットにおいて、テンプレートフリーモデルで初めてTok-1精度が50 %を超え、USPTO-fullデータセットでは、Top-1およびTop-10の精度でテンプレートベースのGLNをそれぞれ5.7 %および6.3 %上回りました。
まとめ
本研究では分子の特徴をSMILES表現とグラフ表現の両方として組み合わせることで、逆合成解析を解決する方法を提案しました。その結果、テンプレートフリーモデル、テンプレートベースモデルのどちらと比較しても良い結果が得られました。
本論文では既存のTransformerモデルにグラフ構造を考慮したマスクを組み入れることで性能向上することが実証されました。マスクを組み込むだけのため、パラメータを追加することなく最先端の結果が得られていてとても興味深いです。



この記事に関するカテゴリー





