
脳の老化度合いを可視化!?2枚のMRI画像を用いた自己教師あり学習手法
3つの要点
✔️長期のMRIの分析に活用できる機械学習モデルを提案
✔️2つのMRI画像ペアの入力とすることで、多くの学習サンプルでの学習を可能にした
✔️LNEを導入することで、脳の老化度合いを表す特徴ベクトルの獲得に成功し、 理想的な可視化結果が得られた
Self-Supervised Longitudinal Neighbourhood Embedding
written by Jiahong Ouyang, Qingyu Zhao, Ehsan Adeli, Edith V Sullivan, Adolf Pfefferbaum, Greg Zaharchuk, Kilian M Pohl
Submitted on 5 Mar 2021 (v1), last revised 17 Jun 2021 (this version, v3)
Comments: Provisional Accepted by Medical Image Computing and Computer Assisted Intervention (MICCAI) 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
長期のMRIは神経疾患や加齢によって引き起こされる脳の構造や機能の衰えをとらえるのによく用いられています。
この論文では長期のMRI画像の分析を機械学習で行うことを目指していますが、データ収集において課題があります。大量のデータを集めるのが難しい、各被験者のMRIの撮影間隔がばらばらであるという2つの課題です。
そこでこの論文では、少数かつ整列していないMRI画像データからよりよい特徴表現を獲得できる自己教師あり学習手法を提案しています。
MRI画像から年齢、アルツハイマー症の進行度合いを推定する2つの下流タスクにおいて他の手法と比較を行い有効性を確認しました。このことから提案手法はよりよい特徴抽出を行えることが示唆されます。また、特徴量を可視化し、脳の劣化を表す特徴(ベクトル)が獲得できていることを確認しています。
提案手法
提案手法のモデルの全体像を以下に示します。
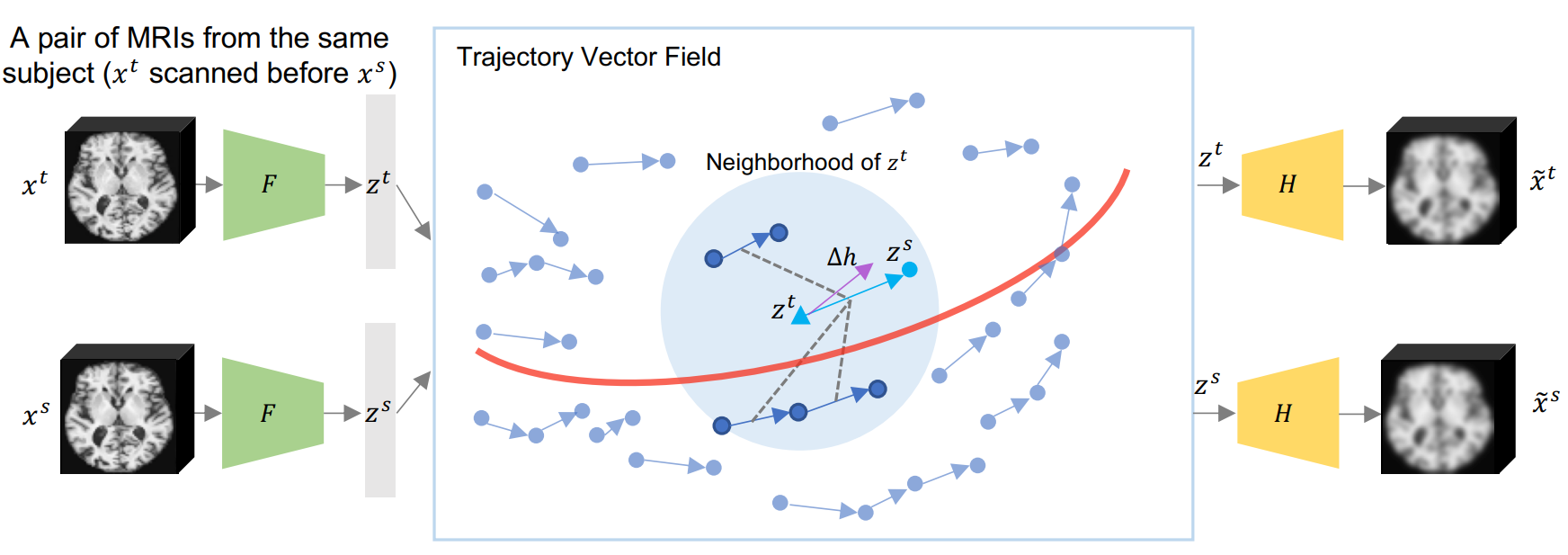
このモデルは大きく2つの特徴があります。
1つ目は2枚のMRI画像を入出力に持つ、Encoder-Decoder構造のモデルであることです。
2つ目は2枚のMRI画像から抽出された特徴ベクトルから得られる軌跡ベクトルの学習を行う点です。
以下これらの特徴を1つずつ説明していきます。
①Pairwise Training Strategy
提案手法のモデルでは2枚のMRI画像で学習を行います。それぞれの被験者の一連のMRI画像を一度にすべていれるのではなく、2枚ペアで入力させることで、学習サンプルを大幅に増やすことができます。
2枚のMRI画像は(xt, xs)[1]はEncoder(F)により、それぞれ潜在表現(zt, zs)[2]に変換されます。ここで得られる潜在表現ベクトルの差(Δz(t,s) = (zs-zt) / Δt(t,s))[3]は単位時間あたりの脳の変化を表します。
潜在表現(zt, zs)はそれぞれDecoder(H)によって入力画像を再構成(x~s, x~t)するのに用いられ、再構成画像が入力画像に近づくように学習を行います。
②Longitudinal Neighbourhood Embedding(LNE)
提案手法のモデル2つ目の特徴である潜在表現ベクトルの差である軌跡ベクトルの学習について説明します。似たMRI画像であれば、その軌跡ベクトルも似た変化になるという仮説に基づき、これに従うように学習を行います。言い換えれば、軌跡ベクトル空間を平滑化するように学習させます。これは歩行者軌道予測タスクに用いられていた平滑化手法であるsocial pooling[4]から着想を得ています。
ただしsocial poolingでは2次元空間を対象とするのに対し、この論文では潜在空間を対象とするためそのまま適用することはできません。そのため、有効グラフを用いて近傍を定義することを提案しています。
有効グラフは各学習ステップ(epoch)ごとにミニバッチ[5]において構築します。有効グラフにおける各ノードの位置をzt、ノードの値はΔzとします。したがって(ノードiとjにおける)ノード間の距離はユークリッド距離を用いて、Pij = |zti-ztj|2とあらわすことができます。ここで、ノードiに対して最も近いノードからNnb番目までを近傍(Ni)とし、隣接行列Aを次のように定義します。
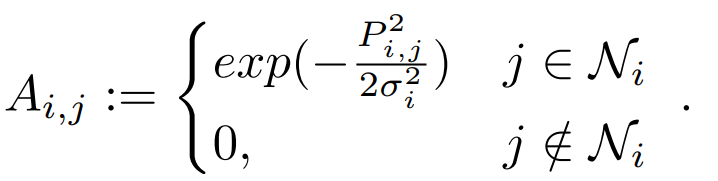
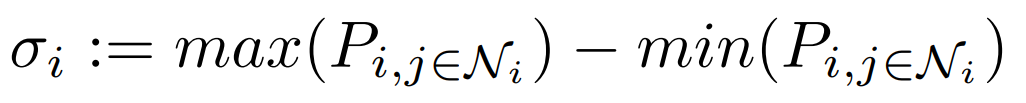
隣接行列Aはノード間の関連性を表します。
ノードiに対して近傍でない(j∉Ni)ノードは考慮しないため、(隣接行列Aにおいて)0をとります。一方、ノードiに対して近傍であるノード(j∈Ni)には正規化した距離を類似度に変換したものが入ります。
この隣接行列Aを用いて近傍ベクトルをプーリングしたベクトルΔh(LNE;Longitudinal Neighbourhood Embedding)を得ます。具体的にはグラフ拡散過程(graph diffusion process)を基に導出される以下の式で計算できます。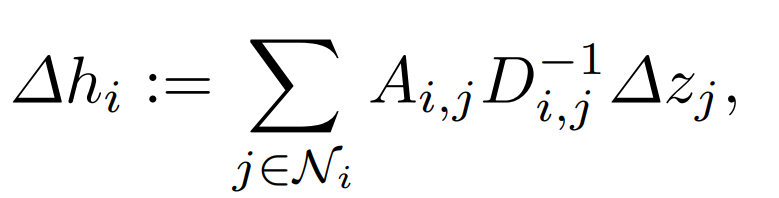
DはグラフGの次数行列(out degree matrix)であり、それぞれのノードの外向きのエッジ重みの和を表す対角行列です。
ここまで複雑な数式を追ってきましたが、簡単に説明すれば、それぞれの軌跡ベクトル(zti)に対して、近傍ベクトル群(Ni)を定義し、 それらのベクトルを考慮したときにΔzが向くであろう方向Δhを(プーリングによって)求めているといったイメージでいいと思います。
このようにして得られたΔhを用いてΔzを修正することで、軌跡ベクトル空間の平滑化を促します。
③Objective Function
最後に提案手法のモデルの損失関数を紹介し、学習方法についてまとめます。
損失関数は以下に示す通りです。
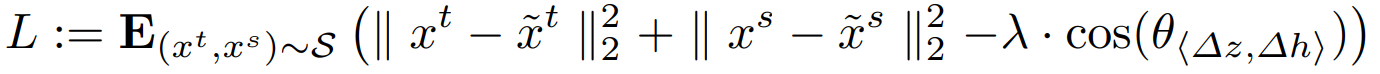
第1項と第2項はencoderとdecoderを通して得られる入力画像の再構成損失(①)を表しています。
第3項は軌跡ベクトルΔzの向きを近傍の軌跡ベクトルをプーリングすることで得られたΔhに近づけるためのもので(②)、ある種の正則化とみなせます。
実験
この論文では提案手法の有効性を検証するために2つの下流タスクにおいて検証が行われています。1つ目は健常者のMRI画像から年齢を推定するタスク(Health Aging)、2つ目はアルツハイマー症の進行度合いを推定するタスク(ADBI)です。ADBIにはNC(Normal Control)、AD(Alzhaimer's Diease)、sMCI(static Mild Cognitive Impairment)、pMCI(progressive Mild Cognitive Impairment)の4クラスあり、この論文ではNCかADか、sMCIかpMCIかの2つの2値分類タスクとして検証を行っています。
下流タスクにおける精度比較
年齢推定タスク(Health Aging)では決定係数(R2)、アルツハイマー症の進行度合いを推定するタスクでは(BACC;Balanced Accuracy)を用いて精度比較を行っています。
提案手法とその他の手法の比較結果は以下に示す通りです。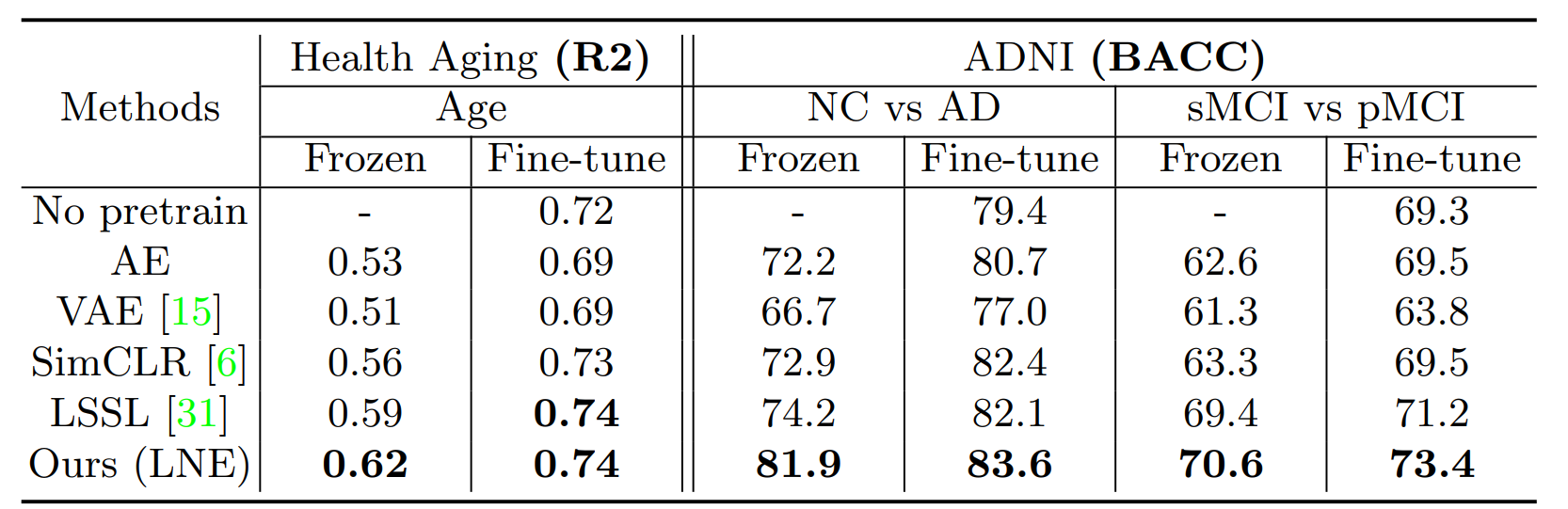
Frozenは下流タスクの学習を行う際に特徴抽出部(提案手法のEncoder部分)を再度学習しない場合、Fine-tuningは再度学習した場合を表しています。
いずれのデータセットにおいても提案手法が最高精度を達成していることが分かります。この結果から、提案手法のモデルはMRI画像からよりよい特徴を抽出できていると言えます。
可視化
Health Agingタスクにおいて、AE(Auto Encoder)と提案手法で得られる軌跡ベクトルを可視化したものが以下の図です。ただし、得られる軌跡ベクトルは高次元のためPCAで圧縮されています。
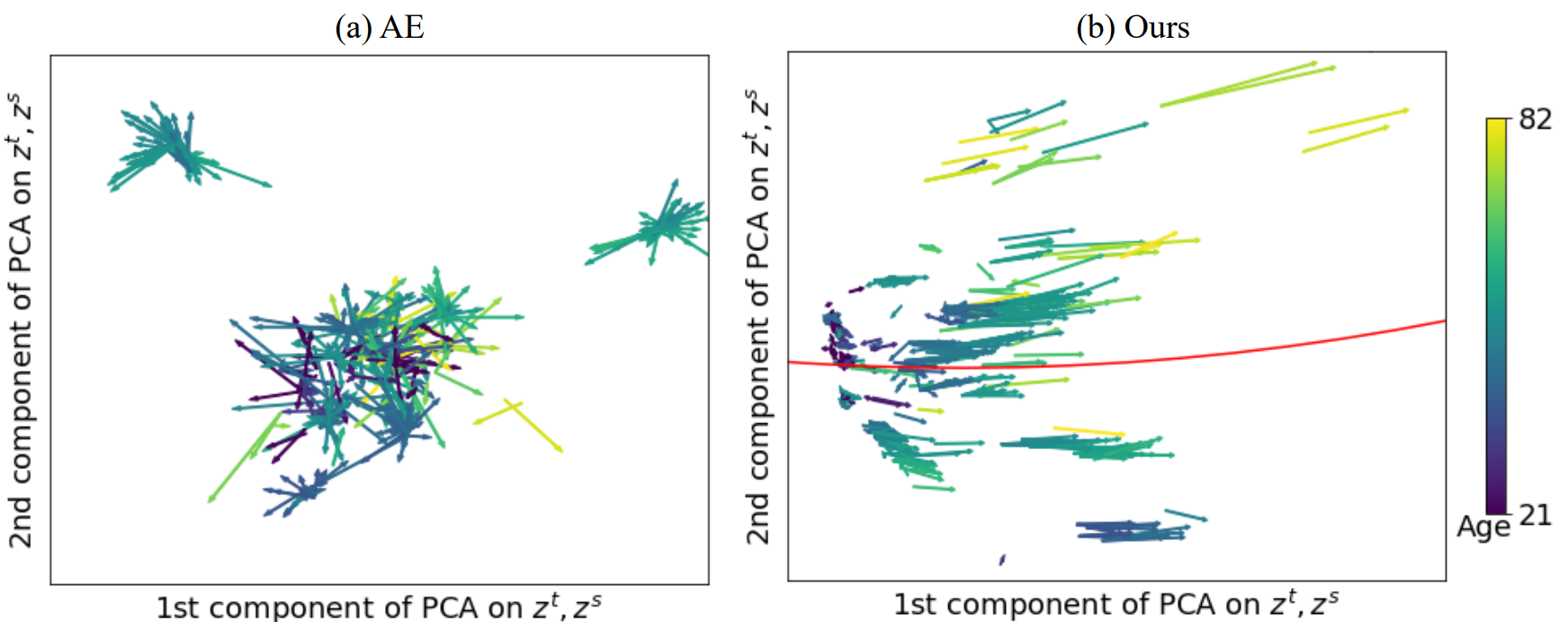
これを見るとAE(左)では軌跡ベクトルが様々な方向を向いてしまっているのに対し、提案手法(右)では軌跡ベクトルの向きが大方そろっていることがわかります。この結果からLNEにより、平滑化された軌跡ベクトル空間が形成できていると考えられます。
また、年齢が上がる(明るい色のベクトル)ほど軌跡ベクトルが長い傾向が確認できます。これは年をとるほど老化のスピードが速くなることを示唆しています。
次にADBIタスクにおける可視化を見ていきます。
(a)と(b)はHealth Agingタスクと同様に提案手法の軌跡ベクトルを可視化したものであり、(a)では年齢ごと、(b)ではアルツハイマー症の進行度合いを表すクラスごとに色分けされています。(c)はアルツハイマー症の進行度合いを表すクラスごとに軌跡ベクトルの長さを算出したものです。
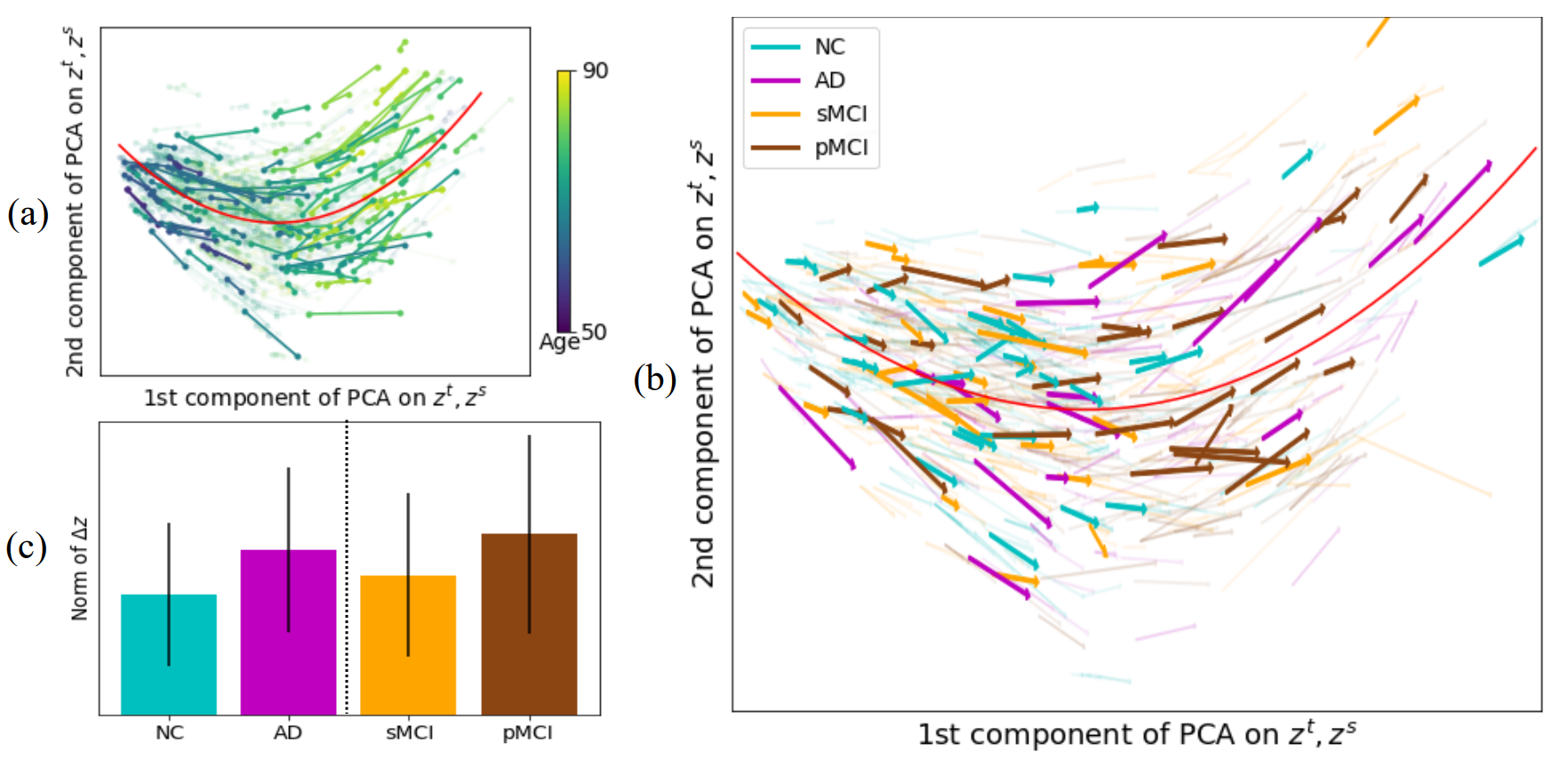
(a)(b)を見ると、Health Agingタスクの時と同様、軌跡ベクトルの向きが大方そろっていることがわかります。
また、(a)から年齢が上がる(明るい色のベクトル)ほど軌跡ベクトルが長くなる傾向も同様に確認できます。
(c)を見ると、NCに比べてADの軌跡ベクトルが長いことが分かります。これはアルツハイマー症が進行している人は脳の老化の進行が速いことを示唆しています。そしてこの結果はアルツハイマー症の先行研究に従うものです。sMCIとpMCIにおいても同様の傾向が確認できます。
まとめ
今回は2つのMRI画像を用いた自己教師あり手法を紹介しました。
データ数の不足は(特に医療ドメインにおいて)よくある課題のため、この手法が様々な場面で参考になるのではないかと思いました。
また、軌跡ベクトルの可視化による分析は納得感があり、医療分野でのAIの信頼性向上に寄与するいい例の一つだと思いました。
補足
[1]xtは必ずxsよりも時間的に前となるように制約がある
[2]zt, zsともに512次元
[3]ここでΔt(t, s)は2つのMRI画像がスキャンされた時間の差である
[4]social poolingの詳細は以下の論文で書かれています
・Social LSTM: Human Trajectory Prediction in Crowded Spaces
・Social GAN: Socially Acceptable Trajectories with
Generative Adversarial Networks
[5]この論文でのバッチサイズは64



この記事に関するカテゴリー






