Transformerが医用画像にもたらした成果を総括します。
3つの要点
✔️ 医用画像とTransformerについて包括的レビュー
✔️ レビューは、検出、分類、再構成、合成、レジストレーション、臨床レポート作成、その他タスクについて行われており、最新の情報は著者らのGitHubから参照することができる。
✔️ Transformerは医用画像分野のあらゆる領域に浸透し、あまりに急速に進展していることがわかった。これに対応するためには学会でのワークショップを開催し、学会誌での特集を組み、関連研究をコミュニティに速やかに普及させることが望まれる。
Transformers in Medical Imaging: A Survey
written by Fahad Shamshad, Salman Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, Huazhu Fu
(Submitted on 24 Jan 2022)
Comments: Published on arxiv.
Subjects: Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
Abstract
Transformerは自然言語分野で成功し、コンピュータビジョン(computer vision, CV)分野にも応用されています。CV分野では畳み込みニューラルネットワーク(convolutional neural network, CNN)が優位ですが、Transformerへの関心が高まっています。それは医療分野でも同様であり、局所受容野をもつCNNと比較して、画像全体における局所的な文脈を捉えるTransformerはどのように優れているのか、本論文では包括的なレビューを提供します。
Introduction
CNNは医用画像分野に大きな影響を与えてきました。エックス線撮影、内視鏡、CT、MRI、マンモグラフィー、PET、超音波など多くの分野で著しい改善が報告されています。しかしながらCNNはその特性として、画像全体に対して局所の画像がどのような意味を持つのか、あるいは画像内で離れた場所にあるもの同士がどう関係しているのかを捉えることは苦手でした。
その一方で、CV領域では注意機構(註:本文ではアテンションと書きます)にヒントを得て新たなアーキテクチャが模索されてきました。そしてアテンションに基づくTransformerによって長距離依存性を効果的な特徴表現として学習することが可能になり、上記の問題点を解決する魅力的な手法となりました。最近の研究では、標準的なCNNはTransformerで完全に代替できることが示されており、Vision Transformers(ViTs)が生まれています。ViTはその誕生以来、分類、検出、セグメンテーション、カラー化など多くの画像タスクで目覚ましい成果をあげています。またViTの予測誤差が人間の予測誤差と似ていることが示されており、この点でも医学領域に関心を呼び起こしました。
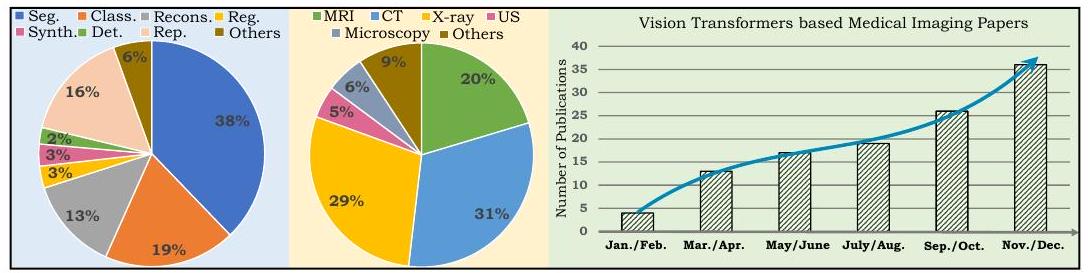
左の円グラフは本レビューが対象とした論文の内訳です。Segはセグメンテーション、Classは分類、Reconsは再構成、Regはレジストレーション、Synthは合成、Detは検出、Repはレポート作成、USは超音波を示しています。右のチャートは、2021年に発表された医用画像にViTを応用した論文数の推移であり、急速に増加していることが分かります。
Background
手作り数理モデル
従来の医用画像タスクにおけるアルゴリズムは、専門家が設計した数理モデル(hand-crafted approches)に基づいていました。このアプローチは、より計算量を少なくし、より多くの組織に適用可能となるような方向性で洗練されていきました。その結果、数学的な裏付けを持つ解釈が可能で堅牢性があるモデルが作られ、医学領域で広く普及しました。現在の深層学習とは異なるアプローチであり、大規模なデータセットやアノテーションは不要でした。
CNNベースの手法
CNNは大規模なデータセットから識別特徴を自動的に学習する方法です。医用画像でも優れた性能を発揮し、最新のAIベース医療システムに不可欠な要素になっています。ところが(基本的には)CNNの性能はデータセットの大きさに依存する性質から、医療分野での適応には限界がありました。加えてCNNの推論結果は一般的に解釈が難しく、ブラックボックス的に機能することが多くあります。
Transformerベースの手法
Transformerはアテンション駆動型ブロックとして自然言語分野で報告されました。アテンションとは、入力シーケンス全体から情報を集約するNNであり、アテンションの登場以来、いくつものモデルが最高性能を塗り替えてきました。今ではモデル選択のファーストチョイスです。
ViTは、入力画像のグローバルコンテキストを捉えるために複数のTransformer層を接続することで構築されたモデルです。
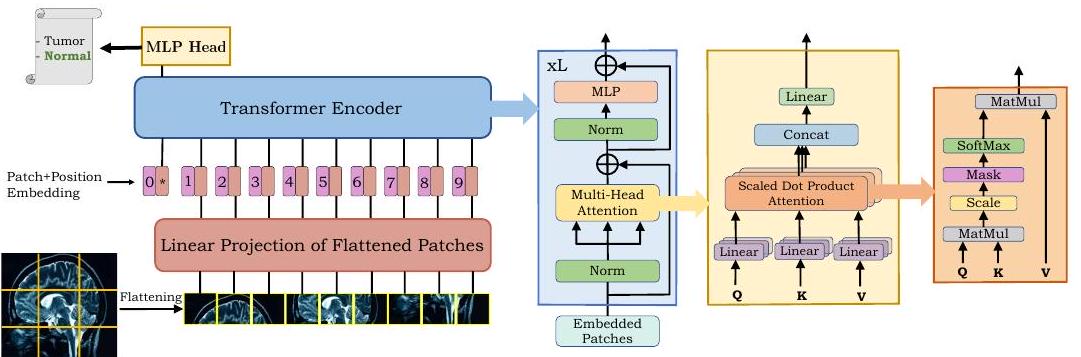
上図に示すようにViTでは、画像をタイル状に分割(パッチ)して一列に並べます。このシーケンスをTransformerでエンコードして最終的な出力を生成します。
Self-Attention
Transformerの成功は、長距離依存性をモデル化する自己注意機構(self-attention, SA)に起因しています。セルフアテンションの重要なアイデアは、シーケンス全体における単一トークンの相対的な重要性を決定することにあります。
Multi-Head Self-Attention
マルチヘッドセルフアテンション(MHSA)は、入力シーケンスの複雑な依存性をモデル化するために複数のブロック(ヘッド)で構成されています。MHSAにより複雑なコンテキストを学習することが可能になりましたがアテンションは計算量が多く、画素数が多くなりがちな医用画像では制限が加わることになりました。そのため医用画像処理ではより効率的な改良型アテンションが提案されています。
セグメンテーション分野
まず医用画像のセグメンテーションについて概説します。セグメンテーションは、コンピュータ支援診断(computer-aided diagnosis, CAD)や画像ガイド手術、治療計画において重要です。例えば臓器は空間的に大きく広がるため、離れたピクセル間の関係をモデル化する必要があります。そこでTransformerのグローバルなコンテキストモデリング機能が有用です。逆に、超音波画像の背景はノイズが多く散乱しています。背景をモデル化することで診断に必要な部位を認識することが可能になります。
臓器のセグメンテーション
2次元セグメンテーション
Wangらは皮膚病変にViTを応用しました。
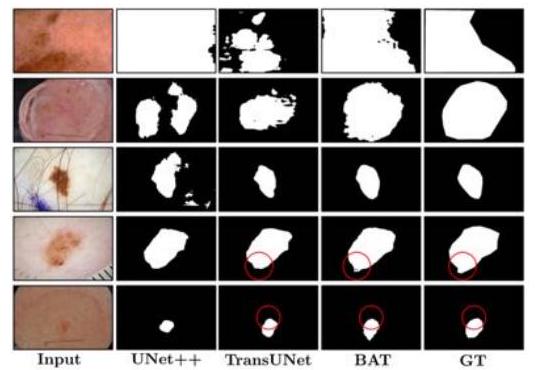
彼らはBoundary-Aware Transformer(BAT)を提案し、メラノーマと正常な皮膚の境界を明瞭に抽出することに成功しました。
他にも、歯根、脈管、腎臓腫瘍、細胞、病理組織に対してViTを利用した手法が提案されています。
3次元セグメンテーション
Wangらは、脳腫瘍の空間的な特徴をモデル化するためにTransformerを活用しました。彼らが提案したTransBTSは、3D CNNを用いて局所的な3次元空間を抽出するとともに、Transformerでより大域的な特徴をエンコードしました。単純なCNNと比較して、TransBTSはその有効性を示すとともに、従来のViTに必要だった大規模なデータセットでの事前学習を不要とした点でも注目されています。
Zhuらは乳がんでの3次元セグメンテーションを行いました。提案手法のRAT-Netは、それまでに提案されたCNNやViTベースの手法を凌駕しました。
多臓器セグメンテーション
multi-organ segmentationは、一度に複数の臓器のセグメンテーションを行います。クラス間の不均衡、臓器の大きさの差異、形状やコントラストの違いなどから単一臓器のセグメンテーションより困難なタスクです。
純粋なTransformer
純粋なTransformerベースのアーキテクチャはViT層のみからなります。セグメンテーションは、全体と局所の2つの視点が必要であるため、基本的にはCNNとTransformerのハイブリッドアーキテクチャが提案されることが多いです。Karimiらは純粋なViT層からなるモデルを提案し、脳皮質、脾臓、海馬の3つのベンチマークセットにおいてその有効性を示しました。
ハイブリッドアーキテクチャ
グローバルなコンテキストをモデル化するためにTransformerを用い、正確なセグメンテーションのためにCNNを利用するというハイブリッドなアーキテクチャが提案されています。最初期の提案手法がTransUNetで、12個のTransformer層を利用しています。
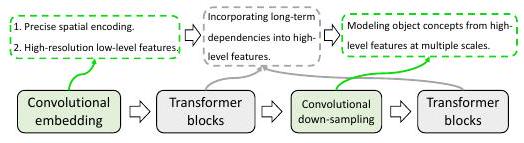
上記のように、ハイブリッドアーキテクチャではTransformerとCNNがそれぞれの長所を発揮できるように接続されています。
セグメンテーションのDiscusion
ViTを用いたセグメンテーションの報告は年50報以上であり、大きく注目されています。この領域では、CNNベースの手法をTransformerベースに変換するだけでほとんどの場合、性能が向上するという結果をもたらしています。ただし計算コストが高く、医用画像分野での制限となっています。
またViTモデルの多くは、ImageNetでの事前学習モデルを利用しています。しかし自然画像と医用画像にはモダリティのギャップがあり、事前学習としてふさわしくないと指摘されています。近年の事前学習で用いられる画像のモダリティに関する研究では、CTで事前学習したモデルをMRIに適用すると満足な性能を発揮できないことが示されました。このモダリティの差異は今後の研究課題になっています。
医用画像分類
腫瘍とは、身体の組織が異常に増殖したものであり、良性と悪性があります。その診断は治療計画上非常に重要なものであり、患者の生存率に大きく寄与します。
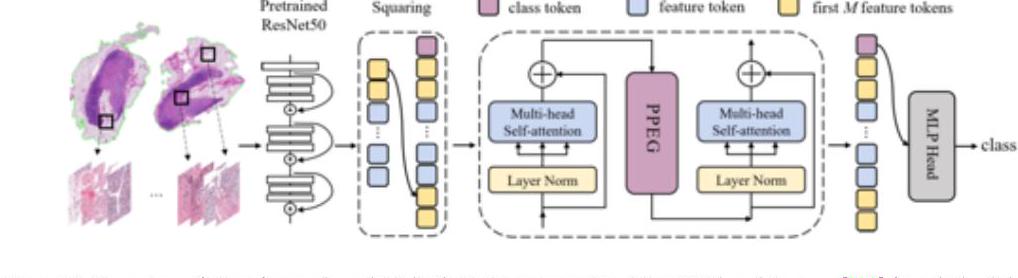
上記のTransMILでは、全スライドイメージ(whole slide image, WSI)のパッチをResNet-50の特徴空間に埋め込んでいます。TransMILは乳腺、肺、腎の3つの組織でSOTAを達成しています。
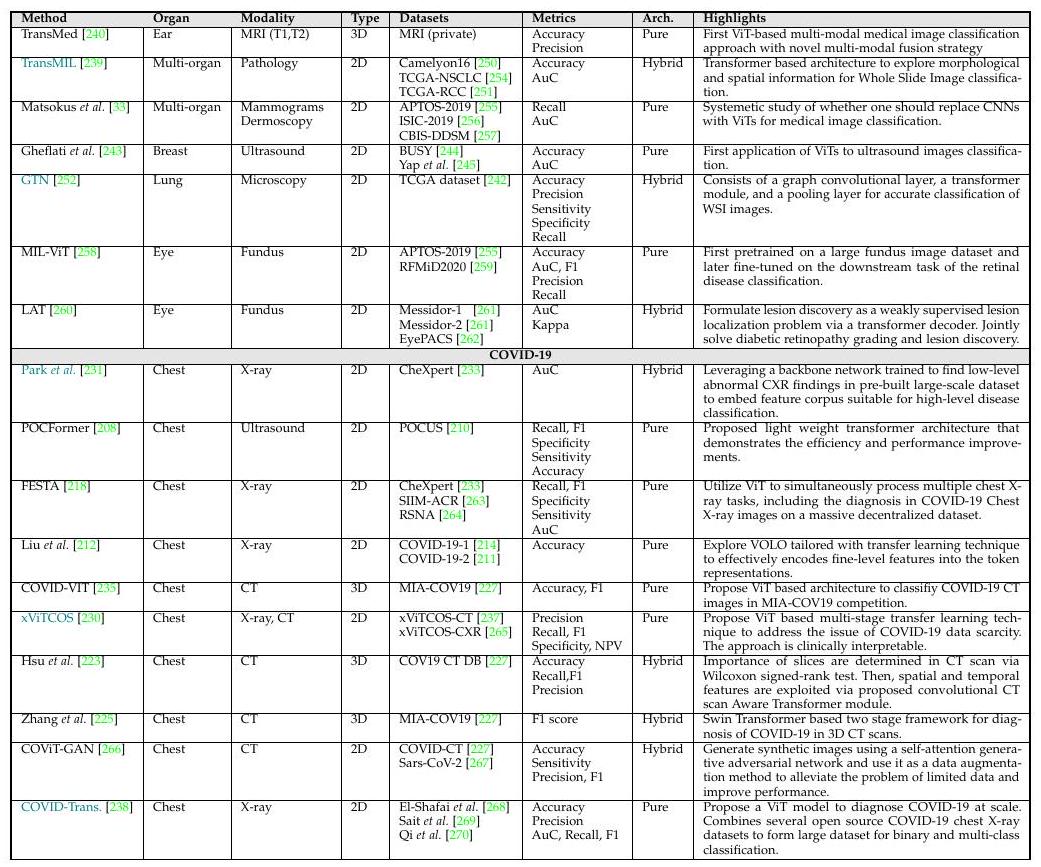
上記はViTベースの医用画像分類の概要です。青色で示されたMethodは、Grad-CAMによる解釈可能性も示したモデルです。
分類のDiscussion
分類タスクにおいて、ほどんどの研究がオリジナルのViTを用いて何の変更も加えていない(plug-and-play)ことが明らかになりました。そのためドメイン固有のアーキテクチャ、損失関数の設計などを加えることで将来的に有効なViTベースのモデルが提案されることが期待されます。
医療画像での物体検知
医用画像における物体検知とは、例えば胸部エックス線写真から肺結節を探すなどの関心領域(region of interest, ROI)を定位することを指します。CNNでも物体検知は成功を収めており、最近Transformerを用いてより高い性能を発揮させる試みがなされています。これらのアプローチの多くは、検出型Transformer(DETR)フレームワークに基づくものです。
Shenらの提案するCOTRは、ポリープの検出、T2強調MR画像でのリンパ節検出に応用され、DETRよりも優れた性能を発揮しています。
物体検知のDiscussion
Transformerベースの物体検知モデルは、セグメンテーションやクラス分類の研究と比較して数が少ないです。CNNベースモデルでは最初期に物体検知が発展したことと対照的です。そのためTransformerベースの研究は近い将来より多くの報告がなされると予測されます。
医用画像での再構成
Reconstruction分野の目標は、劣化した入力からきれいな画像を得ることです(註:reconstructionの直訳は再構成で広い意味を持ちます。復元や補正の総称と考えるとよいでしょう)。
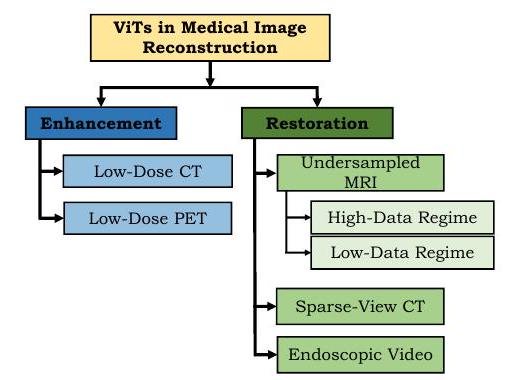
ViTは、画像の強化(enhancement)で目覚ましい成果を上げています。低線量(low-dose)で撮影されたエックス線写真はぼやけますが、これの画質を向上させることで被曝量を減らしつつも診断精度を維持あるいは向上させることが可能になります。
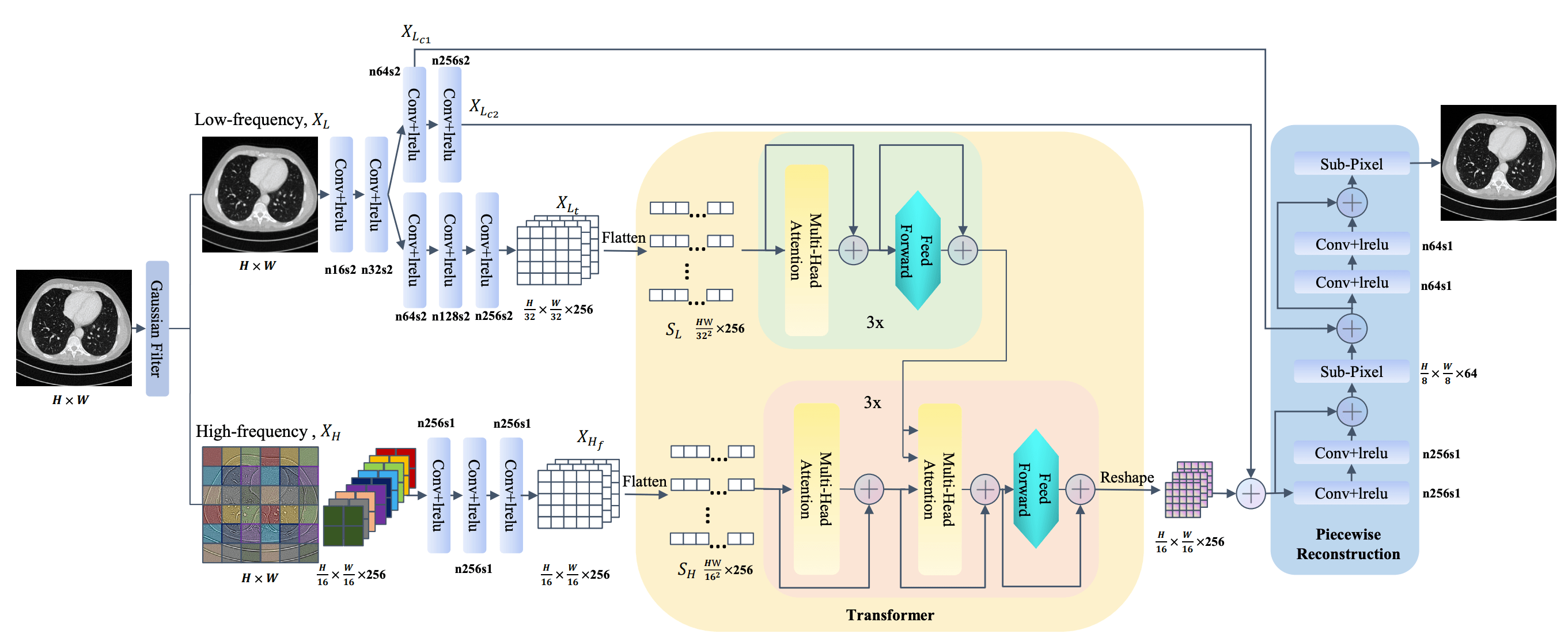
上図のようにZhanらは、低線量CT画像を効果的に強化するTransCTを提案しました。
同様にMRでの一断面あたりの測定回数を減らせば、体動によるアーチファクトを減らすこともできます。FengらはMTransを提案し、従来の手法と比較して良好な結果を達成しました。
再構成でのDiscussion
本レビューでは12篇の論文をサーベイしているが、多くがCT画像を対象としたものでした。加えてアプローチも汎用的であるので、今後の研究ではよりタスクに応じた損失関数やアーキテクチャの設定がなされると予測しており、それに伴ってさらなる性能の向上が見込まれます。
医用画像合成
ViTを医用画像合成へ応用するにあたり、多くのアプローチでは敵対的損失(adversarial loss)を取り入れています。この分野では大きく分けて、同一モダリティ内合成(intra-modality)とモダリティ間合成(inter-modality)があります(註:モダリティとはCT、MRなどの撮影の種類を指します)。
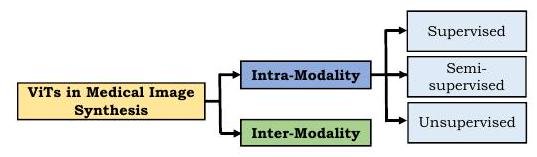
同一モダリティでの合成は、教師あり・半教師あり・教師なし学習の手法が提案されています。教師あり学習の場合、教師画像とそれに対応するターゲット画像のペアが必要であり、医用画像に限らずコストがかかります。医用画像の場合、収集の困難さやアノテーションのコストから余計に制限を受けます。しかしZhangらは幼児の脳MRIを合成するPTNetを提案し、それまでに提案されていたpix2pixやpix2pixHDよりも質的・量的に優れたモデルであることを実証しました。さらにPTNetは性能が高いだけではなく、一枚あたり約30秒の合成時間という適度な実行時間である点も注目されています。
inter-modalityアプローチでは異なるモダリティの画像を取り込み、ターゲット画像を出力します。inter-modality法はモダリティ変換タスクであるために教師あり学習のみが用いられています。
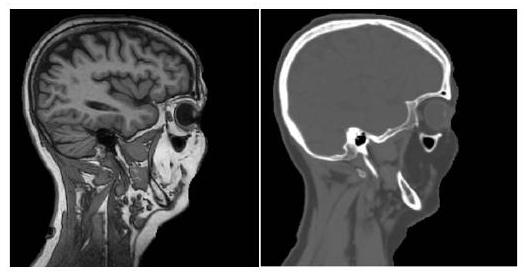
inter-modality法では、上記のようにMRI(左)をCT画像(右)に変換します。全く異なる見た目となっており、素晴らしい結果です。
医用画像合成でのDiscussion
一般的に、臨床における意思決定は複数のモダリティの画像が相互補完的に関与します(註:CTでは骨や歯の硬組織を観察し、MRIでは筋、脳、腫瘍等の軟組織を観察します)。しかしコストの観点から、複数のモダリティ画像が手に入るわけではありません。Transformerベースの画像合成は、GANベースの手法よりも現実的な画像を生成することが分かっており、これらの問題を効果的に回避することができます。
医用画像のRegistration
registrationとは、2つの画像間における位置合わせを指しています。例えば、同一の患者に対してCTとMRで撮影した場合、撮影位置や身体の微妙なねじれで2つの画像がぴったり重なるわけではありません。registrationの分野では、このように2つの画像の変位を求め、位置合わせを確立することが目的です。
Chenらの提案したTransMorphは、静止画と動画の対応関係を明らかにします。入力された画像と動画のセマンティックな対応関係を捉えるためにSwin Transformerでエンコードし、その後のデコーダで変位を推測します。
RegistrationでのDiscussion
現段階では、Transformerがregistration領域にはあまり使われてはおらず、総括することは困難です。しかしながら一般画像におけるTransformerベースの手法が発展しつつあることから、医療分野でも将来的に発展すると期待しています。
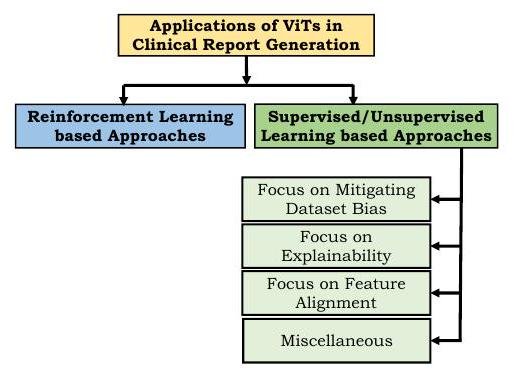
レポート作成
近年、医用画像からレポートを自動作成する研究領域が発展しています。しかし人間(放射線医)が書くレポート自体が多様で、長さも変化に富むことから、読影レポートを作成するあるいはキャプションを加えるタスクは非常に困難です。
このタスクに求められているのは2つです。1つは人間が読みやすい言語表現をすることで、もう1つは医学的に正確な内容であることです。
強化学習に基づくアプローチでは、使用した医学用語、人間の評価などを報酬として利用します。Transformerを用いた最初の試みの1つが、Xiongらの提案したReinforced-Transformer for Medical Image Captioning(RTMIC)です。医用画像からROIを特定するDenseNetと、視覚的特徴を抽出するTransformerベースのエンコーダから構成されており、デコーダ部分でキャプションが生成されます。
教師あり・教師なし学習アプローチでは、微分可能な損失関数を用いて診断書作成のためのモデルを学習します。しかしながら医学レポートの多くは異常よりも正常を記述する文章の方がはるかに多いため、データセットバイアスが発生します。この偏りを軽減するために、SrinivasanはデコーダとしてTransformerを用いた階層的な分類アプローチを提案しました。このアーキテクチャは、正常か異常かを分類する異常検出部、画像に対するタグ生成部、画像特徴とタグから文章を生成する部分で構成されており、胸部エックス線写真でその有効性が示されました。
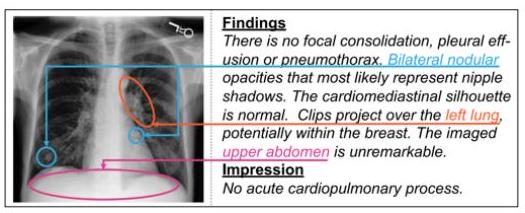
またモデルへの信頼性を向上させるため、結果のテキストに対して画像のどの部分に注目しているかを示す試みも行われています。
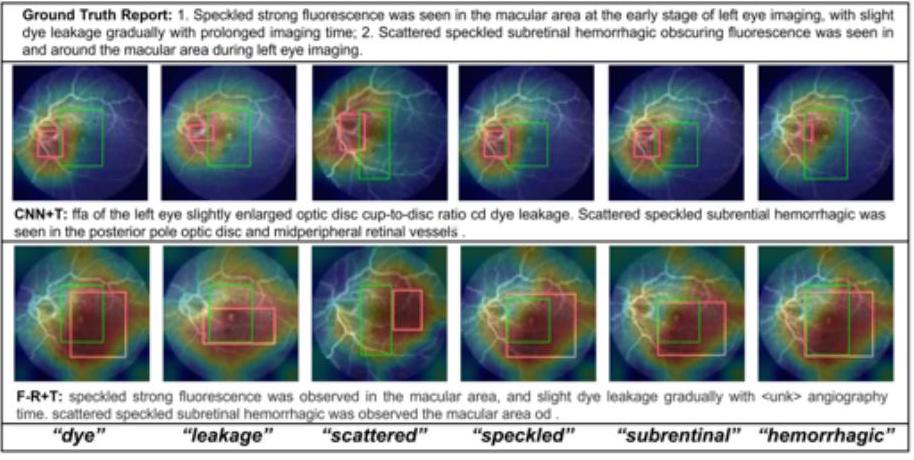
上図のように、CNN+TransformerとFaster-RCNN+Transformerのモデルにおいて、テキストと着目部位の対応関係を示すことができます。dye(染色)やleakage(漏出)という言葉が画像のどの部分から想起されたのかがはっきりと分かります。
レポート作成のDiscussion
これまでViTについてレビューしてきましたが、レポート作成に関しては強力な言語モデルとしてのTransformerに焦点があたっています。2017年から驚異的に浸透したTransformerのインパクトが有るにも関わらず、臨床レポート作成に関しては報告数が少ないです。
Transformerベースのモデルでは、CIDErやBLEUなどの自然言語生成(naturaru language generation, NLG)の評価指標を用います。しかしながらNLG評価指標は臨床的な表現をあまり評価できていません。それに対して強化学習に基づく手法では人間の主観的な評価を報酬として用いるため、生成されたレポートは疾患と解剖学的構造をよりよく捉えています。
またCT、MRI、PETなどの各モダリティには臨床的に明確な撮影目的があるため、特定のモダリティには特定の臨床的文脈が存在しています。そのためそれぞれのモダリティからのレポート生成には各モダリティごとの評価を行う必要があり、独自の課題を有しています。
その他
Transformerのその他の応用事例を紹介します。近年、癌による死亡の相対的なリスクを予測する回帰タスクにおいてTransformerが目覚ましい成功を収めています。遺伝情報と生検標本というマルチモーダルな情報から生存率を予測するMCATという手法がChenらによって提案されています。
ほかにもPubMedの記事から画像とキャプションを学習するPubMedCLIP(contrastive language-image pre-training)や、3次元医療データを解析するための3DMPTなどが提案されています。
今後の方向性
本節では、今後の医用画像におけるViTについて述べます。
事前学習
ViTは、局所的な視覚的特徴をモデル化するための帰納的バイアスを持たないため、大規模なデータセットで事前学習を行う必要があります。しかし医療分野で大規模な(註:Transformerの文脈では数千万〜数億枚が大規模とされます)データセットを集めることが困難であり、制限となる可能性があります。多くの報告ではImageNetでの事前学習が使われていますが、自然画像と医用画像では特性が異なります。以下にCNNとViTの特徴をまとめました。
- ランダムな重みで初期化した場合、CNNはViTよりも医用画像分類タスクで優れている。
- CNNとViTは、医用画像分類においてもImageNetによる初期化から大きな利益を得ることができる。特にViTは、転移学習によって医用画像と自然画像のギャップを埋めているようである。
- CNNとViTは、DINOやBYOLのような自己教師あり事前学習で良い性能を発揮し、この場合においてViTはCNNをわずかに上回るようだ。

上記は、医用画像で事前学習したViTの性能評価です。青はCT画像で事前学習したSwin UNETで、オレンジは事前学習なしのSwin UNETでのダイス係数を比較したグラフです。Swin UNETでは医用画像で事前学習する方が良いことが分かりました。
解釈可能性
Transformerは医用画像分野でも成功を収めていますが、解釈可能性については満足できる結果を出してはいません。医用画像分野においてViTは性能は良いものの、ブラックボックス的な使われ方をしており、いくつかの研究で解釈可能性について言及されていますが、全体としては初期段階といえます。画像中の各部位がどのように相互作用しているのかを明示的にモデル化することは未だにできていません。アテンションが解釈可能性に本質的に適しているにも関わらず、医用画像の解釈可能性は未解決の問題です。
ロバスト性
敵対的攻撃の進歩により、既存の画像処理ネットワークは摂動に対して脆弱であることが明らかになっています。特に診断に関する医用画像分野では研究費も莫大であるため、必然的に攻撃の対象となります。例えば保険金や診療報酬を不正に得るために、攻撃者が医用画像システムに不正な操作をし、報告書を改竄する可能性があります。
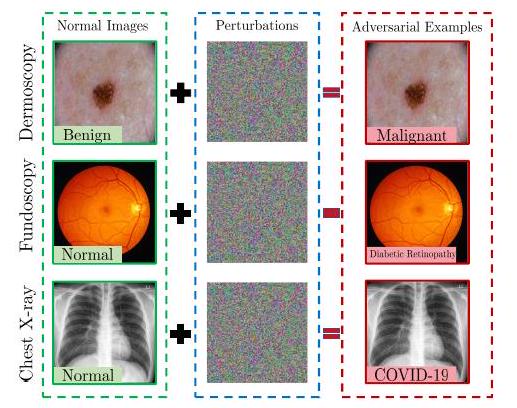
CNNの頑健性に対する報告は豊富に存在しますが、我々の知る限りViTに対するそのような報告は存在しません。近年、ViTに対する攻撃と頑健性に関するいくつかの試みがなされており、多少の違いに目をつぶってまとめると、ViTはCNNよりも敵対的攻撃に対して頑健であることがわかりました。先にも述べたように自然画像と医用画像の特性は異なるため、敵対的攻撃もまた医用画像に特化する必要があり、ViTによる医用画像処理システムの頑健性を評価するのはまだ先のことになると考えられます。
ViTを使ったエッジAI
医用画像分野でViTは成功していますが、やはり計算コストがかかります。そのためリソースに制約のあるエッジコンピューティングへの展開が妨げられているのが現状です。しかしながらヘルスケア領域ではエッジコンピューティングへの需要が高く、患者のプライバシーを守りながら医用画像を処理・変換・解析することが望まれています。近年Transformerベースのモデルを圧縮する取り組みがいくつかなされていますが、ドメインに最適化されたアーキテクチャの設計が切実に求められています。
ViTを活用した分散型医用画像処理ソリューション
頑健な機械学習モデルの構築は、学習データの量と多様性に依存します。信頼性の高い堅牢なモデルを学習するためには、逆説的に厳しいプライバシー規制に阻まれます。
そこで多施設共同でモデル構築を行うために連合学習(federated learning, FL)が提案されています。FLは複数の機器から分散データを用いて共有モデルを構築し、各機器がローカルデータで学習を進めます。これにより患者データを共有することなく、パラメータを中央のモデルと共有することで学習を行うことができます。
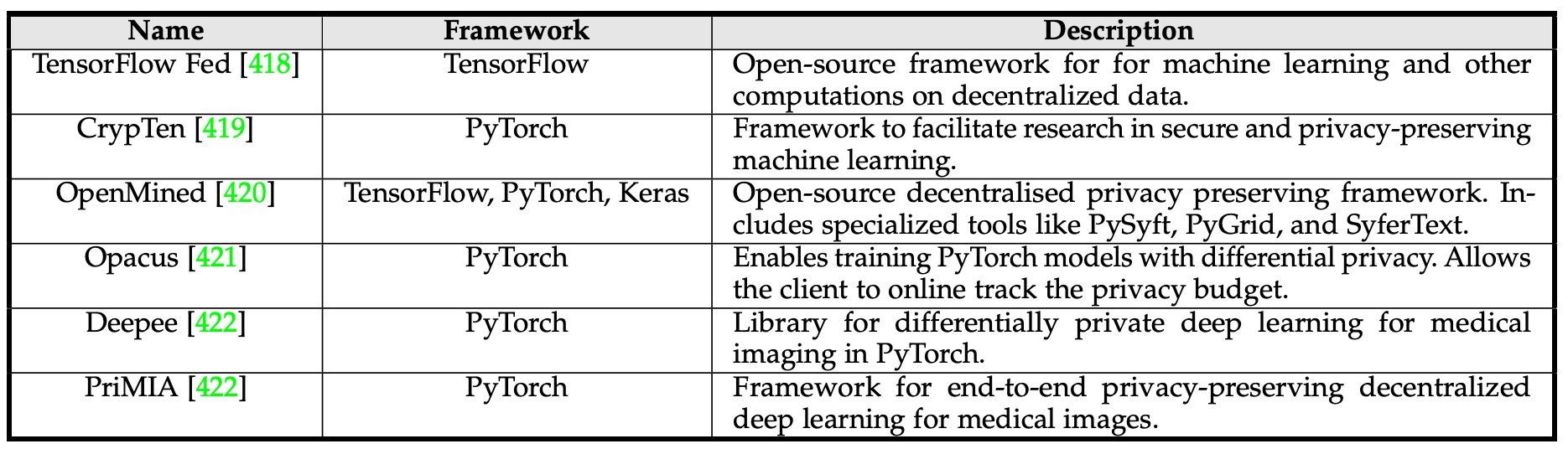
上記が連合学習用のフレームワークです。Parkらは連合学習によるシステムでCOVID-19の診断を行うViTベースのシステムを提案しました。しかしながらこのモデルはあくまでの実証実験であり、臨床的にはさらなる検証が必要になるでしょう。
ドメイン適応性と汎化性
近年のViTベース医用画像システムは精度の向上が主眼で、汎化能力を評価する仕組みが欠けています。砂金の研究では、一般的にテスト誤差は訓練データとテストデータの分布の違いに比例して増加することが示されています。医用画像の文脈においてこのような分布のズレは以下のような要因によって生じます。
- 異なる施設、異なる機器で得られた画像
- 訓練データにない疾患がテストデータに含まれる
- コントラストの低い不鮮明な画像
しかしその一方で、大規模なデータで事前学習したViTが異なるモダリティでも良い性能を発揮することが示されている。ただしそれらのモデルはCIFAR-10やCIFAR100といったトイデータで学習されたものが多く、医用画像のような複雑なパターン、局所的特徴には対応できていないのが現状である。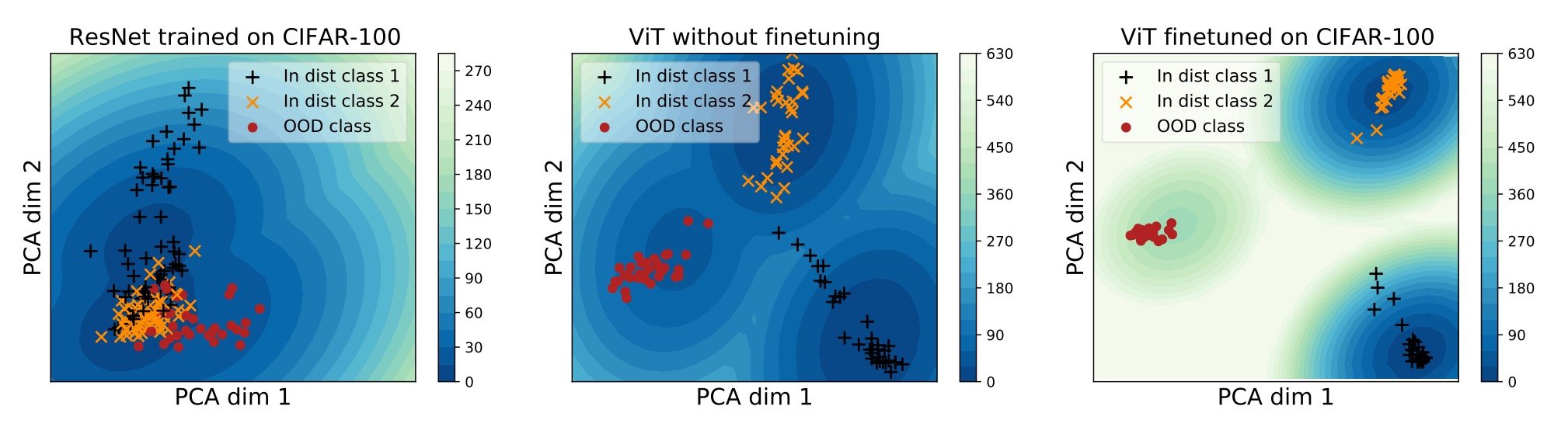
上記は、3つのモデルの埋め込みベクトル空間を2次元にPCA投影した図です。左のResNetは、3つ(黃、黒、赤)が分離できていませんが、中央のViTはクラス分類はできています(ただし黒の一部が黄色に近い)。そこでViTをCIFAR-100でファインチューニングするとさらによく分類できるようになっています。
Discussion and Conclusion
本論文でViTが医用画像分野のあらゆる領域に浸透していることが示された。この急速な発展にたいおうするために、CVや医用画像に関する学会でのワークショップが開催されたり、雑誌で特集が組まれることが期待されます。
本論文ではTransformerの成功を背景として、医用画像における分類・検出・セグメンテーション・再構成・合成・レジストレーション・レポート生成・その他のタスクについてTransformerの包括的なレビューを提供しました。医用画像におけるTransformerについては、まだまだ多くの探求が残されており、今後も続く研究に本論文がより良いロードマップを提供できることを望みます。






この記事に関するカテゴリー






