GitHubのCopilotの安全性は?
3つの要点
✔️ GitHub Copilotの概要
✔️ Github Copilotで生成されたコードのセキュリティ脆弱性
✔️ Github Copilot のコードコントリビューションに関する実証的な研究
An Empirical Cybersecurity Evaluation of GitHub Copilot's Code Contributions
written by Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri
(Submitted on 20 Aug 2021 (v1), last revised 23 Aug 2021 (this version, v2))
Comments: Published on arxiv.
Subjects: Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
コーディングをはじめとするあらゆる作業で人間を支援するAIシステムが急速に開発されています。コードを書くことは、世界中の何百万人もの人々が日々行っていることであり、その多くは繰り返し行われています。GitHubは最近、Copilot(コパイロット)という新しいツールを公開しました。Copilotは”AI pair programmer”と呼ばれ、コメントや関数名、周囲のコードなどの文脈が与えられると、さまざまな言語でコードを生成します。Copilotは、オープンソースのGitHubのコードで学習されており、その中には悪用可能なバグのあるコードも含まれています。そのため、Copilotのコード提供の安全性について懸念が生じています。
この論文では、以下の質問に答えることを試みます。
Copilotの提案は一般的に安全なのか?安全でないコードはどのように生成されるのか?どのような要因が、安全性の高い、あるいは低い生成コードをもたらすか?これらの質問への回答は、Copilotを日常業務に統合することを検討している人にとって有用です。
背景
CopilotはOpenAIのGPT-3をベースにしています。GPT-3のモデルはGitHubのコードでfine-tuningされています。このモデルは、byte pair encodingsを使用してソーステキストをトークンのシーケンスに変換します。コードは多くの空白で構成されているため、GPT-3の語彙を拡張し、空白のトークンを追加しています(例:空白2個分のトークン、空白3個分のトークン、最大25個分のトークン)。 CopilotはGPT-3のような言語モデルをベースにしているため、大きな弱点があります。文脈が与えられると、それまでに見たコードと最もよく一致するコードを生成しますが、これは必ずしも最良の選択ではありません。
GitHub Copilotの使用
Copilotは現在、Visual Studio Codeでのみサポートされています。ユーザーがプログラムにコードを追加すると、Copilot はコードをスキャンし、行の一部、カーソルの位置、その他のメタデータを定期的にアップロードします。そして、信頼度スコア(mean probと呼ばれる)とともに、ユーザーのためのコードオプションを生成します。信頼度スコアが最も高いオプションがデフォルトで表示されます。
ここでは、pythonの'login'関数用に生成されたコードの例を、line-15から示します。


評価方法
Copilotで生成されたコードのセキュリティ評価は、コンパイルやユニットテストによる機能的な正しさとは異なり、自由度の高い問題です。SAST(Static Application Security Testing)ツールは、ソースコードやコンパイルされたコードを解析して、セキュリティ上の欠陥を発見するように設計されています。本研究では、GitHubの自動解析ツールであるCodeQLと手動評価を併用しています。
MITREは、様々なクラスの安全でないコードに見られる最も一般的なパターンを集めたデータベース、The Common Weaknesses Enumeration(CWE)データベースを保持しています。CWEはツリー状に分類されており、各CWEはピラー(最も抽象的なもの)、クラス、ベース、バリアント(最も具体的なもの)に分類されています。例:CWE-20は、「不適切な入力の検証」、すなわち、プログラムが入力を受け取るように設計されているにもかかわらず、処理前にデータを検証しない(または誤って検証する)場合です。CWE-20はクラス型CWEであり、CWE-707の子であり、ピラー型CWEの子である「不適切な中和」を対象としています。
上記のコードは、入力が5行目で使用できるかどうかを検証していないコードの例です。クラスCVE-20、「ベース」CVE-1284: Improper Validation of Specified Quantity in Input、および一部のケースでは「バリアント」CVE-789にも準拠した脆弱性であると考えられます。CVE-789: 過剰なサイズ値でのメモリ割り当て。
ここでは、MITREが発表した「2021 CWE Top 25 list of Most Dangerous Software Weaknesses」を中心に評価を行います。このリストに基づいて、「CWEシナリオ」と呼ばれるCopilot用のプロンプトデータセットを作成します。言語は3つ(Python,C,そしてあまり知られていないVerilog)です。Copilotは、各シナリオに対して最大25個の選択肢を生成するよう求められ、重大な問題があるものは破棄されます。自動評価には可能な限りCodeQLを使用し、時折著者が介入します。評価方法の全体像を以下に示します。
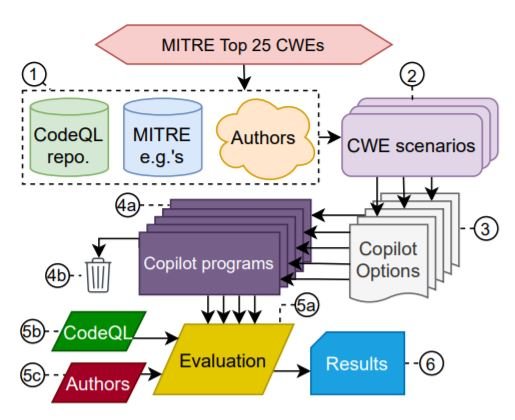
様々なシナリオでCopilotを評価することを目的に、3つの異なるタイプの多様性でCopilotを分析しました。
- Diversity of Weakness (DOW): 異なるCWEのインスタンス化につながる可能性のあるシナリオを検討する。
- Diversity of Prompt (DOP): 微妙な変化を含むプロンプトを用いて1つの危険なCWEシナリオを検討する。
- Diversity of Domain (DOD): ソフトウェアの代わりにVerilogでレジスタトランスファーレベル(RTL)のハードウェア仕様を生成し、ハードウェアCWEになる可能性のあるシナリオを完成させる際の性能を検討する。
というものです。各ダイバーシティと個々のCWEについての非常に詳細な説明は、原著論文を参照してください。次に、全体的な観察結果をまとめます。
結果
DOWのテストでは、Copilotは約44%の確率で脆弱なコードを生成していました。例:CWE-79(Cross-site scripting)とCWE-22(Path traversal)を比較すると、CWE-79では最も信頼度の高いオプションの脆弱性が0%で、全体では19%しかないのに対し、CWE-22では最も信頼度の高いオプションの脆弱性が100%で、全体では60%もある。
DOP: 1つのCWEシナリオに対して微妙な変化を含むプロンプトをテストした場合、いくつかの例外を除いて、全体的な回答の信頼度とパフォーマンスにはあまり大きな違いはありませんでした。いくつかのシナリオでは、意味的に無関係な変更(「delete」という単語を「remove」に変更するなど)が、生成されたコードの安全性に大きく影響していました。
DOD:pythonやC言語に比べて、Copilotは構文的に正しく意味のあるVerilogコードの生成に苦労していました。また、C言語との類似性からC言語のキーワードを使用することがあり、Verilogの各種データ型(wire型とreg型)の違いを理解できなかった。
全体として最も信頼度の高い選択肢の39.33%と予測された選択肢の40.48%に脆弱性があることが判明しました。これは最も信頼度の高い選択肢が、特に初心者のプログラマーによって選択される可能性が高いことを意味しています。このセキュリティ上の脆弱性は、使用されているオープンソースコードの性質にも起因している。オープンソースコードに多い特定のバグがCopilotによって頻繁に再現される。また、セキュリティの質は時間とともに進化することも考慮する必要があります。例えば、DOWのCWE-32(パスワードハッシュ)のシナリオでは、しばらく前にMD5ハッシュが安全だと考えられ、ソルトを使ったSHA-256のシングルラウンドに置き換えられました。現在では、シンプルなハッシュ関数を何度も使用するか、「bcrypt」のようなライブラリを使用することで置き換えられています。メンテナンスされていない学習コードが普及しているため、Copilotは古いオプションを提案し続けています。
また、Copilotのコードは直接的な再現性がありません。つまり、同じプロンプトでも時間によって異なる結果が得られる可能性があります。 Copilotはblackboxであり、クローズドソースであるため、根本的な原因を明らかにすることは困難でした。
まとめ
素晴らしいツールであるにもかかわらず、今回の実験では、Copilot を使用する際には警戒が必要であることが示されました。今回の実験で使用した問題別のCWEシナリオに比べて、現実のセキュリティ問題はより複雑であり、Copilotの実際の性能は今回の実験で示されたものよりもはるかに悪い可能性があります。とはいえ、GitHub Copilotが今後も改善されていくことは間違いありません。Copilotやその他の将来的なツールが、今後数年間でコーダーの生産性を向上させることは間違いありません。






この記事に関するカテゴリー






