
経験から自律的に学習を行うLLMエージェント、ExpeLが登場!
3つの要点
✔️ トレーニングタスクから自律的に学習する新しいLLMエージェントであるExpeLを提案
✔️ Experience GatheringとInsights Extractionの2つのモジュールによりエージェントが経験から自律的に学習を実行
✔️ タスクの経験を蓄積し自律的な学習を行うことにより、比較実験において既存手法を上回る性能を発揮
ExpeL: LLM Agents Are Experiential Learners
written by Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, Gao Huang
(Submitted on 20 Aug 2023)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
機械学習の歴史において、研究者は長い間自律型エージェントの可能性を探究してきており、最近ではこれらのエージェントに大規模言語モデル(LLM)を組み込むことで、学問の枠を超えて様々な応用が広がっています。
LLMの大きな利点の一つがその豊富な知識であり、様々なタスクにおいて汎用性を発揮することができる一方で、大量の人間によるラベル付きデータセットが必要であり、その計算コストの高さが問題点として挙げられてきました。
加えて最近ではLLMをファインチューニングする手法が広まっていますが、特定のタスク用にLLMをファインチューニングする事はリソースを大量に消費するだけでなく、モデルの汎化能力を低下させる可能性があることが判明しています。
本論文ではこうした問題点に対処するために、トレーニングタスクから自律的に経験(experience)を収集・抽出し、自然言語を用いて知識を抽出し、情報に基づいた意思決定を行う新しいLLMエージェントであるExpeLを提案した論文について解説します。
ExpeL: Experiential Learning Agent
私たち人間の学習は、主に以下の2種類の工程によって行われています。
- 成功したタスクのプロセスを記憶に保存し、新しいタスクを行う際に具体例として呼び出し(retrieve)、参考にする
- 行ったタスクの経験から高レベルの洞察(insight)を抽出し、新しいタスクへの一般化を可能にする
ExpeLは1の工程をExperience Gathering、2の工程をInsights Extractionというモジュールによって実装しており、全体のプロセスは下図のようになっています。
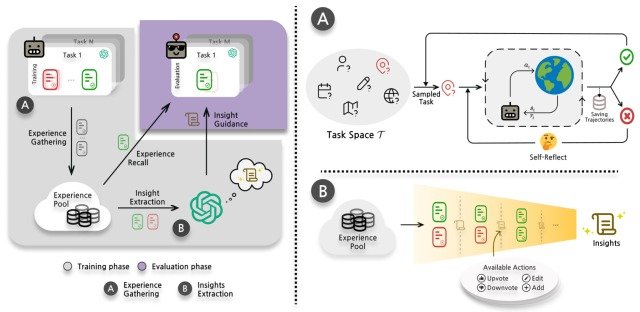
それぞれ見ていきましょう。
Experience Gathering
私たち人間は未経験のタスクを行う際に「これまでに解決してきた類似タスクの記憶を思い出し、それを参考にする」というプロセスを踏みます。
本論文はこれに動機づけられ、「タスクの類似性に基づき、トレーニング中に収集された経験プールから成功したプロセスを検索する」手法であるexperience recallを提案しています。
この手法では、学習段階においてエージェントが環境と相互作用し、既存研究であるReflextionによる経験収集プロセスによって経験(experience)を収集し、経験プールであるFaiss vectorstoreに保存します。
実際に評価タスクを行う際は、kNN retrieverとall-mpnet-base-vs embedderを用いて、評価タスクと内積タスク(これまでに収集したタスク)の類似度が最大となる上記k個の成功プロセスを検索し、実行に用います。
ここではエージェントがタスクを終了するか、最大ステップ数に達するたびに、ExpeLエージェントは収集した経験をプールに保存し、次のタスクに進むというプロセスを繰り返します。
Insights Extraction
Experience Gatheringで収集された多様な結果を活用するために、エージェントは以下の2つの異なる方法で経験から洞察(insights)を抽出し、新しいタスクへの一般化に利用します。
- エージェントに、同じタスクにおいて失敗したプロセスと成功したプロセスを比較させる
- エージェントに、異なるタスクの成功したプロセスからパターンを識別させる
上記の分析を行うために、実装では洞察の空集合を作成し、LLMに経験プールから失敗/成功したペアまたは成功したプロセスのリストを与え、LLMはリストをもとに洞察の集合に対して以下の4つの動作のいずれかを実行します。
- ADD: 新しい洞察を追加する
- UPVOTE:既存の洞察に賛成票を入れる
- DOWNVOTE:既存の洞察に反対票を入れる
- EDIT: 既存の洞察の内容を編集する
上記のプロセスを行うのに使用したテンプレートが下図になります。

このような構造により、ユーザーはエージェントに洞察をスムーズに追加することができ、要求されるデータ量が少ないため計算資源を削減でき、簡単に実装できるようになっています。
加えて、Reflextionのような自己改善手法はタスク内の改善を促進しますが、ExpeLはタスク間の学習を可能にするため、特定のドメインに依存しないせず、既存研究にはない汎用性を獲得しています。
Experiments
本論文では、ExpeLの有効性を実証するために以下のベンチマークタスクに基づいた既存モデルとの比較実験を行いました。
- HotpotQA: 検索ツールであるWikipedia Docstore APIを用いて、エージェントに推論と質問応答を実行させるタスク
- ALFWorld: 家庭内を模した仮想環境で、エージェントに対話的な意思決定タスクを実行させるタスク
- WebShop: オンラインショッピングサイトを模した仮想環境で、エージェントに対話的な意思決定タスクを実行させるタスク
実験には、Imitation Learning・ExpeL(insights-only)・ExpeL(retrieve-only)・ExpeL(ours)・Act・ReAct・Reflextionを用いた7種類のモデルが用いられました。
ここで、Imitation Learningは強化学習の一種、ExpeL(insights-only)はExpeLにおいて類似タスク検索を行わないモデル、ExpeL(retrieve-only)は同様に洞察の抽出を行わないモデルになっています。
また、各ベンチマークタスクは別々に行われるのではなく、HotpotQA→AFLWorld→WebShopの順に連続で実行されました。
実験結果は下図のようになりました。
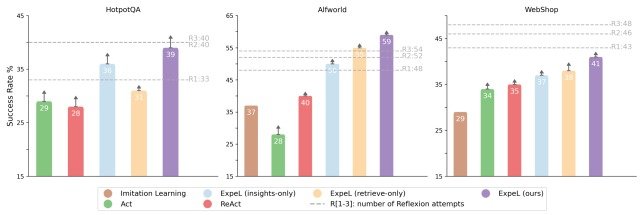
図よりExpeLは全てのタスクで一貫して既存モデルを上回る性能を示しており、本手法の有効性を実証する結果となりました。
加えて、ExpeL(insights-only)とExpeL(retrieve-only)の性能を比較することで、ExpeLにおいてタスク類似検索と洞察の抽出はともに必要不可欠であり、相乗効果を持つことが確認できました。
もう一つの重要な発見はReflextionモデルとの比較であり、ExPeLはHotpotQAではReflextionと同等の性能を示し、ALFWorldではReflextionを上回る性能を示しています。
これは、Reflextionがタスク実行(R1, R2, R3)を繰り返すことでタスクごとに性能を改善するのに対し、ExpeLは各タスクの経験を蓄積することで、タスクを横断した学習が可能になっていることを示しています。
一方で、WebShopではExpeLはReflextionを下回る性能となり、まだまだ改善の余地が残されていることを示唆する結果となりました。
まとめ
いかがだったでしょうか。今回は、トレーニングタスクから自律的に経験(experience)を収集・抽出し、自然言語を用いて知識を抽出し、情報に基づいた意思決定を行う新しいLLMエージェントであるExpeLを提案した論文について解説しました。
人間のような知的エージェントの開発には経験から自律的に学習する能力が不可欠であり、本論文で提案されたExpeLはその第一歩となる非常に有望な研究だと言えます。
一方で、今回の研究で行われた実験はテキストによるタスクのみの限定的なものであり、筆者はVison Languageモデルやキャプションモデルを用いて画像情報を取り入れることで、より一般的なタスクに適用できる可能性があると述べており、今後の進展に注目が集まります。
今回紹介したExpeLのアーキテクチャや実験結果の詳細は本論文に載っていますので、興味がある方は参照してみてください。



この記事に関するカテゴリー






