
人間の協調的な行動プロセスをシミュレーションするマルチエージェントフレームワーク、AgentVerseが登場!
3つの要点
✔️ マルチエージェントグループによる協働作業を促進するフレームワークであるAgentVerseを提案
✔️ problem-solving processをシミュレートしたモジュール構造により、エージェントのグループ構成を動的に調整
✔️ 比較実験により、シングルエージェントを上回る性能を発揮した
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors in Agents
written by Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chen Qian, Chi-Min Chan, Yujia Qin, Yaxi Lu, Ruobing Xie, Zhiyuan Liu, Maosong Sun, Jie Zhou
(Submitted on 21 Aug 2023)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
GPT-4の登場により、AutoGPT・BabyAGI・AgentGPTなどの大規模言語モデル(Large Language Models: LLM)による自律型エージェントは大きな進歩を遂げており、効果的な意思決定を行い、広範なタスクを実行できるようになりました。
一方で実世界において、ソフトウェア開発・コンサルティング・ゲームプレイングなどの複雑なタスクを効率よく実行するためには、個体間の協力が必要となってきます。
こうした事実があるにも関わらず、既存研究では(専門用語でproblem-solving processと言われる)複雑なタスクを行う際に人間の集団の中で構成される協調的な行動をシミュレートする試みは行われてきませんでした。
本論文ではこうした背景より、人間の協調的な行動をシミュレートし、タスク解決における複数のエージェント間の協働作業を促進するためのフレームワークであるAgentVerseを提案し、実験によりマルチエージェントグループによる協働作業がシングルエージェントの性能を上回ることを実証した論文について解説します。
AgentVerse Framework
前述したproblem-solving processとは、「集団が現在の状態と望ましい目標との不一致度を判断し、意思決定における協力を促進するために集団構成を動的に調整し、その後に十分な情報に基づいた行動を実行する」という人間集団で発生する一連のプロセスになります。
本論文で提案されたAgentVerseは、自律的なマルチエージェントグループのタスク実行率を高めるために、problem-solving processをシミュレートし、下図に示すようにExpert Recruitment・Collaborative Decision-Making・Action Execution・Evaluationの4つのモジュールから構成されています。
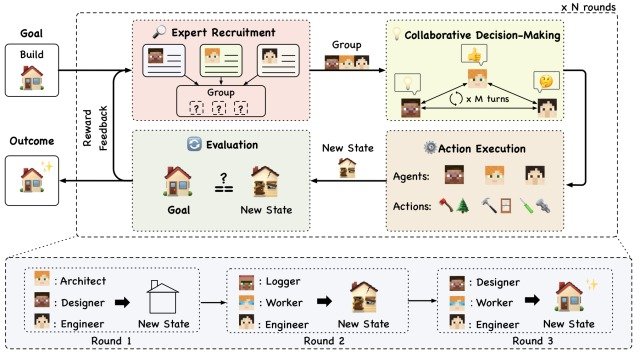
この4つのモジュールの一連の実行をRoundという単位で表し、Round 1→Round 2→Round 3と実行を繰り返すことによってエージェントのグループ構成が動的に調整されていきます。
それぞれのモジュールについて見ていきましょう。
Expert Recruitment
このモジュールは、マルチエージェントグループの構成を決定し、グループのタスク実行力の上限を決定する上で重要な役割を果たします。
最近の研究から、人間がチームを形成するために専門家(Expert)を採用するのと同様に、自律型エージェントに特定の役割を指定することでその性能を上げることができることが示唆されています。
その一方で、自律型エージェントにどの役割を割り当てるかは人間の知識と直感に依存しており、タスクの理解に基づいて手作業で割り当てる必要がありました。
この観点からAgentVerseは、エージェントに役割を割り当てるための以下のような自動化されたアプローチを採用しています。
- はじめにあらかじめ定義されたexpert descriptions(役割が詳細に記述されたプロンプト)に基づいて、タスク完了のためのexpert descriptionsのセットを生成する
- これによって生成されたエージェントが、与えられたタスクを完了するためのマルチエージェントグループを形成する
- (後述する)Evaluationからのフィードバックに基づいて、マルチエージェントグループの構成を動的に調整する
これらの仕組みにより、AgentVerseは現在の状態に基づいて最も効果的なマルチエージェントグループを構成することが可能となっています。
Collaborative Decision-making
このモジュールでは、生成されたエージェントによる協調的な意思決定を行います。
効果的な意思決定を促進するために、多くの研究にてエージェント間の様々なコミュニケーション構造の有効性が検討されてきましたが、本論文ではHorizontal CommunicationとVertical Communicationの2つの典型的なコミュニケーション構造に焦点を当てています。
Horizontal Communicationは横方向のコミュニケーションであり、各エージェントが同じように責任を持ち、積極的に意思決定を共有することで、エージェント間の相互理解と協力を促します。
こうした構造から、ブレインストーミング・コンサルティング・協力的なゲームプレイングなど、独創的なアイデアが要求されたり、積極的な協調を必要とするタスクでは、Horizontal Communicationが有効になります。
一方、Vertical Communicationは縦方向のコミュニケーションであり、責任を分担させることで1体のエージェントが意思決定をし、残りのエージェントがレビュワーとしてフィードバックをする構造になります。
こうした構造から、ソフトウェア開発のような特定の目標に向かって決定を繰り返し洗練させる必要があるタスクでは、Vertical Communicationが有効になります。
Action Execution
このモジュールでは、前述したCollaborative Decision-makingにおいて決められたコミュニケーション構造に基づいて指定されたタスクを実行します。
Evaluation
このモジュールはAgentverseの最後の部分であり、グループ構成の調整と次のRoundでの改善に向けて重要な役割を果たします。
このモジュールでは、現在の状態と目標のタスクとの差を評価することで、次のRoundでどのように改善するかについての建設的な提案によるフィードバックを行います。(このフィードバックは実装によって、人間によって定義されるかモデルによって自動的に定義されるかを決めることができます)
その後タスクが未達成と判断された場合、提案されたフィードバックはExpert Recruitmentモジュールの初期段階に送られ、フィードバックを基にエージェントのグループ構成が調整され、タスクが完了するまで一連の流れでRoundが繰り返されます。
Experiments
AgentVerseがシングルエージェントよりも効率的にタスクを行えることを実証するために、ベンチマークタスクによる定量的な実験を実施しました。(本実験はGPT-3.5-TurboとGPT-4に基づいて実施されました)
本実験では、Conversation(会話能力)・Mathematical Calculation(数学的演算能力)・Logical Reasoning(論理的思考力)・Coding(コーディング能力)を測定するために、以下のベンチマークを使用しました。
- Conversation: 対話応答データセットであるFEDとCommongen-Challengeデータセットを使用
- Mathematical Calculation: MGSMという小学校の算数の問題を含むデータセットを使用
- Logical Reasoning: BigBenchという既存研究で用いられたLogic Grid Puzzlesというデータセットを使用
- Coding: コード補完データセットであるHumanevalデータセットを使用
実験では、シングルエージェントは与えられたプロンプトを使って直接回答を生成し、AgentVerseは構築されたマルチエージェントグループによる協働作業によって回答を生成しました。
また、これらのベンチマークタスクは1体のエージェントが自身の回答を反復的に改良するコミュニケーション構造が有効であるため、Vertical Communicationが採用されました。
実験結果は下図に示します。
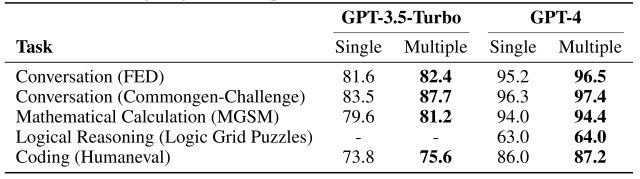
図が示すように、GPT-3.5-TurboとGPT-4のどちらにおいても、AgentVerseによるマルチエージェントグループは一貫してシングルエージェントを凌駕していることが確認できます。
このように、本実験よりマルチエージェントグループによる協働作業が個々のエージェントの性能を上回ることが実証される結果となりました。
まとめ
いかがだったでしょうか。今回は、人間の協調的な行動をシミュレートし、タスク解決における複数のエージェント間の協働作業を促進するためのフレームワークであるAgentVerseを提案し、実験によりマルチエージェントグループによる協働作業がシングルエージェントの性能を上回ることを実証した論文について解説しました。
本実験によりマルチエージェントグループによる協働作業の有効性を実証する結果が示されましたが、一方で今回の研究ではAutoGPTやBabyAGIのような高度なエージェントは利用せず、基本的な会話記憶を持つLLMを利用しました。
筆者たちは、今後の研究でより強力な性能を持つエージェントをAgentVerseのフレームワークに統合し、より広範なタスクに対応できるように拡張・改良すると述べており、今後の進展が非常に楽しみです。
今回紹介したAgentVerseのアーキテクチャや実験結果の詳細は本論文に載っていますので、興味がある方は参照してみてください。






この記事に関するカテゴリー






