特徴表現は低次元であるべきか?
3つの要点
✔️ 一般的な表現学習は、高次元の入力から低次元の表現を獲得する
✔️ 固定観念に反した、低次元の入力から高次元の表現を得る手法の提案
✔️ 既存の強化学習と組み合わせることで、連続制御タスクの性能向上
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
written by Kei Ota, Tomoaki Oiki, Devesh K. Jha, Toshisada Mariyama, Daniel Nikovski
(Submitted on 3 Mar 2020 (v1), last revised 27 Jun 2020 (this version, v2))
Comments: Accepted at ICML2020
Subjects: Machine Learning (cs.LG); Robotics (cs.RO); Machine Learning (stat.ML)
Paper Official Code COMM Code
はじめに
深層学習における最も重大な問題は、生の入力データから重要な特徴を抽出し、タスクを解決するために有用な潜在表現を取得する表現学習です。
例えば、ブロック崩しをAIにプレイさせる場合を考えてみましょう。このとき、入力となるデータは、縦横数十から数百pxのRGB画像となり、入力の次元数は数千から数万ほどになるでしょう。深層強化学習において、このような高次元のデータをそのまま利用することはありません。まずCNN等を利用して重要な特徴を抽出し、次元数の少ない潜在表現へと変換します。こうして獲得した低次元の表現を利用し、効果的に学習を行うのです。直感的に考えても、ブロック崩しを解決する上で重要なのはブロック、ボール、操作するバーの位置などでしょう。
つまり高次元の入力は、不要なデータが多く含まれている・重要な情報が整理されていない等、タスクの解決に利用する上で多くの問題があります。だからこそ、タスクの解決に必要な情報を適切に取得できる表現学習が重要視されているのです。一般的な表現学習は、高次元の入力データから低次元の潜在表現を取得します。前述の例と同様、高次元の扱いづらいデータを、低次元の扱いやすいデータへと変換することがほとんどです。
では逆に、低次元の入力データから高次元の潜在表現を取得したらどうなるでしょうか?
つまり、入力に対して高次元の潜在表現は、タスクを解決する上で有用なのでしょうか?
今回紹介する論文は、深層強化学習における表現学習について、この問いに対し肯定的な解答を示した研究となります。
OFENet(提案手法)
強化学習では、エージェントはある時刻$t$において、環境から観測$o_t$、報酬$r_t$を受け取り、行動$a_t$を選択します。
論文で提案された手法であるOnline Feature Extractor Network (OFENet)は、観測$o_t$と行動$a_t$を入力として受け取り、高次元な観測表現$z_{o_t}$と、観測・行動ペア表現$z_{o_t,a_t}$を取得します。
実際に強化学習タスクを実行する場合は、OFENetとは別に強化学習アルゴリズムを利用します。
ただしこの強化学習アルゴリズムは、観測$o_t$と行動$a_t$の代わりに、OFENetによって求めた$z_{o_t}$,$z_{o_t,a_t}$を用います。
アーキテクチャ
OFENetのアーキテクチャは以下のようになります。

図の通り、観測$o_t$はパラメータ$θ_{φ_o}$を持つ写像$φ_o$により、観測表現$z_{o_t}$へと変換されます。また、観測表現$z_{o_t}$と行動$a_t$はパラメータ$θ_{φ_{o,a}}$を持つ写像$φ_{o,a}$により、観測・行動ペア表現$z_{o_t,a_t}$へと変換されます。
これを数式で表すと以下のようになります。
$z_{o_t} = φ_o(o_t)$
$z_{o_t,a_t} = φ_{o,a}(o_t,a_t)$
これらの写像$φ_o$,$φ_{o,a}$は、DenseNetを調整したMLP-DenseNetを利用します。
MLP-DenseNetでは、各レイヤーの出力$y$は、入力$x$に、重み行列$W_1$と入力$x$の積を連結した、$y = [x, σ(W_1x+b)]$となります($[x1,x2]$は連結、$σ$は活性化関数。バイアスは省略)。
つまり、DenseNetの畳み込み演算を、多層パーセプトロン(MultiLayer Perceptron)で置き換えたものを利用します。そのためDenseNetと同様、低レイヤーの入力と出力は最終的な出力に含まれることになります。実験ではMLP-DenseNet、MLP(通常の多層パーセプトロン)に加え、ResNetを調整したMLP-ResNetも検証に利用されています。MLP-ResNetもMLP-DenseNetと同様、ResNetの畳み込み演算が多層パーセプトロンに置き換えられた形式となっています。
Distribution Shift
FENetは、強化学習アルゴリズムと同時に学習します。そのため、OFENetの学習に伴い、強化学習アルゴリズムへの入力の分布が変化する可能性があります。これはdistribution shiftと呼ばれ強化学習における重大な問題として知られています。(AI-SCHOLARではこの記事等で触れられています)。
この問題を緩和するため、Batch Normalizationを利用することで分布の変化を抑制します。
補助タスク(Auxiliary task)
強化学習アルゴリズムの目標は、累積報酬を最大化するような方策を学習することです。OFENetは、こうした方策の学習に役立つような、高次元の状態・行動表現を学習する必要があります。そのために、観測・行動表現$z_{o_t}$,$a_t$を入力として、次の観測$o_{t+1}$を予測する補助タスクを利用します。
この補助タスクは、パラメータ$θ_{pred}$を持つモジュール$f_{pred}$によって実行されます。ここで、$f_{pred}$は観測・行動表現$z_{o_t}$,$a_t$の線形結合として表されます。
このとき、強化学習アルゴリズムの学習とOFENetを同時に学習します。つまり、以下に示す補助タスク損失$L_{aux}$を最小化するよう、OFENetのパラメータ$θ_{aux} = \{θ_{pred}, θ_{φ_o} , θ_{φ_{o,a}} \}$を最適化します。
$L_{aux} = E_{(ot,at)∼p,π}[||f_{pred}(z_{o_t},a_t ) − o_{t+1}||^2 ]$
補助タスクの性能
OFENetの性能を十分に引き出すためには、ハイパーパラメータを適切に選択することが必要です。しかし最適なハイパーパラメータは、環境や強化学習アルゴリズムに強く依存します。
それゆえ、有効なハイパーパラメータを効率的に求める方法が必要となります。このとき、強化学習タスクを実行して性能を比較するのは非効率的なため、補助タスクの性能を利用することでハイパーパラメータを決定しています。
補助タスクの性能を求める手順は以下のとおりです。
- ランダムな方策を実行することで観測と行動の履歴を収集し、それをtrainセットとtestセットにランダムに分割する。
- trainセットで学習したのち、testセットで5つのランダムシードを利用して平均補助損失$L_{aux}$を求める。
- この平均補助損失が最小となったアーキテクチャを、実際のタスクで使用する。
このようにして、実際に強化学習エージェントを環境と相互作用させて学習させることなく、効率的にハイパーパラメータを決定します。
実験結果
実験では、入力が低次元である連続制御タスクをもとに性能を検証します。
実験は全てMuJoCo環境で行われます。
比較研究
はじめに、OFENetによって求めた表現を利用した場合と利用しなかった場合(Original)の比較結果について以下に示します。
前述の通り、OFENetは既存の強化学習アルゴリズムと組み合わせて利用します。ここで比較のために利用したアルゴリズムは以下の通りです。
どの場合でも、$z_{o_t}$,$z_{o_t,a_t}$は入力次元に比べて、240次元大きく設定されます。
また、OFENetの代わりに、ML-DDPGを利用して生成した表現を比較に利用します。
このとき、ML-DDPGとSACを組み合わせます(以下の図ではML-SACにあたる)。表現の次元数は、オリジナルの場合(入力次元の1/3)、OFENetと同次元の場合(OFE like)の両方について検証します。
学習曲線と、5つのランダムシードにおける最高の平均リターンは以下の通りです。
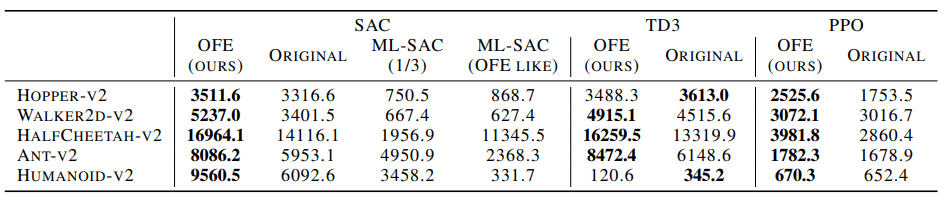
図・表から分かる通り、表現学習の既存手法であるML-DDPG利用時との比較(ML-SAC)、MFE非利用時(original)と比較して高い性能を示したことがわかります。
アブレーション研究
OFENetではDenseNetの畳み込み層を多層パーセプトロンに置き換えたMLP-DenseNetを利用しました。このMLP-DenseNetの代わりに、MLP-ResNet、MLPを利用した場合は以下の図のようになります。
この図の通り、MLP-DenseNetを利用した場合が最も傑出した性能を示していることがわかります。ネットワークの変化が性能に非常に大きく影響していることから、高次元の表現を適切に構築することは容易ではないと言えるでしょう。
他にもOFENetのアーキテクチャのうち、性能の向上に寄与している要素を検証するため、以下の例についてアブレーション研究を行っています。強化学習アルゴリズムにはSACを、シミュレーション環境にはAnt-v2を利用します。
・full:完全なOFENetによる表現を利用した場合
・original:オリジナルのSAC
・no-bn:Batch Normalizationなし
・no-aux:補助タスクなし
・same-params:SACのパラメータをOFENetと同じ数に変えたもの
・freeze-ofe:OFENetを先に学習して固定し、その後強化学習アルゴリズムを学習させる
図の通り、補助タスク、Batch Normalization、OFENet・強化学習アルゴリズムの同時学習がOFENetの性能向上に寄与していることがわかります。
また、OFENetの表現の次元数の増加が、強化学習の性能にどのように影響するかについての検証も行っています。$z_o$,$z_{o,a}$の次元数を変化させた場合が以下の図の通りです。
このように、次元数の増加に伴い、ある閾値まで性能が向上することがわかりました。
まとめ
一般的な表現学習では、高次元の入力から低次元の潜在表現を取得します。しかし今回紹介した通り、低次元の入力を高次元の表現へ変換することにより、強化学習エージェントがより高い性能を発揮できる場合があることが示されました。
表現学習における固定観念に一石を投じるものであり、非常に重要かつ今後の進展に期待の持てる研究です。
類似論文レコメンド
Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
written by Shixiang Gu, Ethan Holly, Timothy Lillicrap, Sergey Levine
(Submitted on 3 Oct 2016 (v1), last revised 23 Nov 2016 (this version, v2))
Comments: Accepted at arXiv
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
Paper Official Code COMM Code
Agent Modeling as Auxiliary Task for Deep Reinforcement Learning
written by Pablo Hernandez-Leal, Bilal Kartal, Matthew E. Taylor
(Submitted on 22 Jul 2019)
Comments: Accepted at AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE'19)
Subjects: Multiagent Systems (cs.MA); Machine Learning (cs.LG)
Paper Official Code COMM Code




この記事に関するカテゴリー

