
文章から3Dオブジェクトを生成するーDreamFusionー
3つの要点
✔️ 事前学習させたText-to-Imageモデル(Imagen)を用いて、テキストのみから3Dオブジェクトを生成するDreamFusionの提案
✔️ 損失関数を最適化することにより拡散モデルからのサンプリングが可能なSDS( Score Distillation Sampling)の提案
✔️ 提案されたSDSと、3D生成タスクに特化したNeRFを組み合わせることで、多様なテキストに対応した忠実度の高い3Dオブジェクトとシーンを生成する
DreamFusion: Text-to-3D using 2D Diffusion
written by Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
(Submitted on 29 Sep 2022)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML).
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
近年、ゲームや映画、シミュレータなど多くのデジタルメディアには、何千もの3Dデータが必要とされています。しかし、3Dアセットはモデリングソフトウェアを使って手作業でデザインするため、多大な時間や専門知識が必要となります。
このような問題を解決するためのアプローチとして、主に、GANやNeRFなどがあります。GANは、顔などの特定のオブジェクトを生成することに特化していますが、テキストはサポートされていません。また、NeRFは、テキストもサポートされていますが、リアリティや正確さに欠けるところがあります。
本稿で紹介する DreamFusionは、テキストから3Dオブジェクトを生成することで、デジタルメディアに対する初心者の参入障壁を下げると共に、ベテランのワークフロー向上を目標としています。

概要
DreamFusionは、3D生成タスクに特化したNeRFと、新しく提案された方法であるSDS( Score Distillation Sampling)を組み合わせることで3Dオブジェクトの生成を行います。
NeRFは、特定のシーンの形状を復元するために最適化され、観察されていない角度からそのシーンの新しいビューを合成することができます。そのため、多くの3D生成タスクに組み込まれています。しかし、事前学習させた2DText-to-Imageモデルから生成された3Dオブジェクトは、リアルさや正確さを欠いてしまう傾向にあります。
この問題を解決するために著者らは、損失関数を最適化することによりDiffusion Modelからのサンプリングが可能なSDS( Score Distillation Sampling)の提案しました。この新しく提案するSDSと、3D生成タスクに特化したNeRFを組み合わせることでDreamFusionを実現しています。
SDS(Score Distillation Sampling)
本研究のDreamFusionの肝となるSDSは、拡散モデルの構造を利用して、最適化による扱いやすいサンプリングを行い、損失関数を最小化するとサンプルが得られるようにします。
使用するDiffusion Modelは、バックプロパゲートする必要があるため、ヤコビアン項の計算コストが高いです。また、マージナル密度のスケーリングされたヘシアンを近似するように学習されるため、小さなノイズレベルでは不十分です。
そこで、 Diffusion Modelのヤコビアン項を省略することで、 Diffusion Modelを用いたDIPの最適化に有効な勾配が得られることを見出し、以下の数式でそれを実現しました。
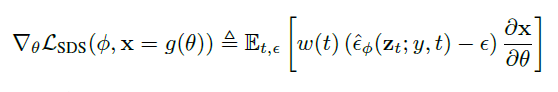
θは3次元体積のパラメータ、gはvolumetric rendererとして、x = g(θ)が凍結された拡散モデルからのサンプルのように見えるように、パラメータθ上で最適化します。ここでの勾配は、拡散モデルで学習したスコア関数を用いて重み付けした確率密度蒸留損失の勾配です。
このサンプリング方法をSDS( Score Distillation Sampling)と名付けました。 これにより、ランダムな角度からレンダリングしたときに良い画像のように見える3Dモデルを作成します。
DreamFusion
DreamFusionに使用する Diffusion Modelは、64×64のベースモデルのみを使用し、 この学習済みモデルを何も手を加えずに使用します。
では、「サーフボードに乗ったクジャクの写真」という自然言語のキャプションから、DreamFusionで「DSLRで撮影したようなサーフボードに乗ったクジャク」の画像生成の流れを例にアルゴリズムを説明していきます。(下図参照)
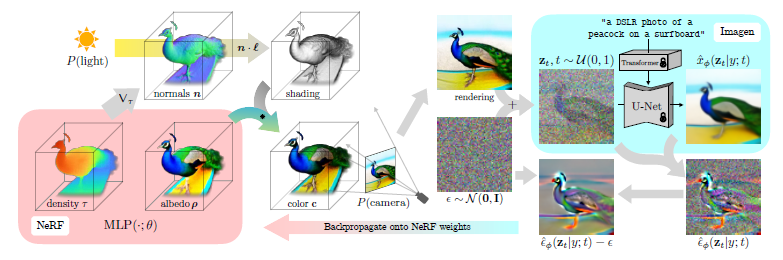
DreamFusionの最適化の各反復は、次のように行われます。
- カメラとライトをランダムにサンプリングする
- そのカメラとライトからNeRFの画像をレンダリングし、その光で陰影をつける
- NeRFのパラメータに対する SDSの損失勾配を計算する
- optimizer を使い、NeRF パラメータを更新する
では、これらの手順を解説していきます。
1,NeRFで表現されたシーンはランダムに初期化され、キャプションごとに0から学習されます。ここで使われるNeRFは、体積密度とMLPを使ったアルベド(色)をパラメータ化します。
2,このNeRFをランダムなカメラからレンダリングし,密度の勾配から計算される法線を用いて,ランダムな照明方向で陰影をつけます。陰影を付けることで、単一視点からは曖昧な細部の詳細が明らかとなります
3,パラメータ更新をするために、DreamFusionはレンダリングを拡散し、加えられたノイズを予測するために条件付きImagenモデルで再構築します。これは、分散が高いですが、忠実度を向上させるためのストラクチャが含まれています。
4,また、加えられたノイズを減算することで、低分散の更新方向stopgradが生成されます。これは,NeRF MLP のパラメータを更新するため,レンダリングプロセスを通じてバックプロパゲートされます
このようにSDSと、3D生成タスクに特化したNeRFを組み合わせることでDreamFusionを実現しています。
実験と結果
本論文では、既存のゼロショット・テキストから3Dへの生成モデルと比較と、正確な3Dジオメトリを可能にするDreamFusionの主要コンポーネントを特定する性能評価を行いました。
複数のベースラインとの比較
入力キャプションに対するレンダリング画像の一貫性のための自動メトリックであるCLIP R-Precisionを評価しました。
下の表は、DreamFusionといくつかのベースラインにおけるCLIP R-Presionの結果を示しています。DreamFieldsを含め、 CLIP-Meshや MS-COCOにより元のキャプション付き画像のペアを評価するオラクルを対象としています。また、右の図はこの実験において生成された各3Dオブジェクトの視覚的比較です。
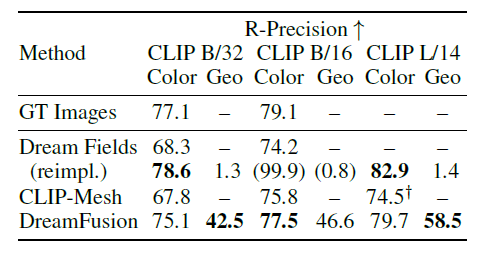

この評価はCLIPに基づいており、DreamFieldsとCLIP-Meshは学習時にCLIPを使用するため有利となります。その中でも、DreamFusionはカラー画像においてベースラインの性能を上回り、真正画像の性能に近づいています。
テクスチャレスレンダリングでジオメトリ(Geo)を評価した場合、DreamFusionは58.5%の確率でキャプションと一致しました。
主要コンポーネントの特定
正確な3Dジオメトリを可能にするDreamFusionの主要コンポーネントを特定するため、ベースラインのアルベドレンダー(左)、フルシェーディングレンダー(中)、テクスチャレスレンダー(右)で CLIP R-Precision を測定し、ジオメトリ品質をチェックしました。(下図参照)
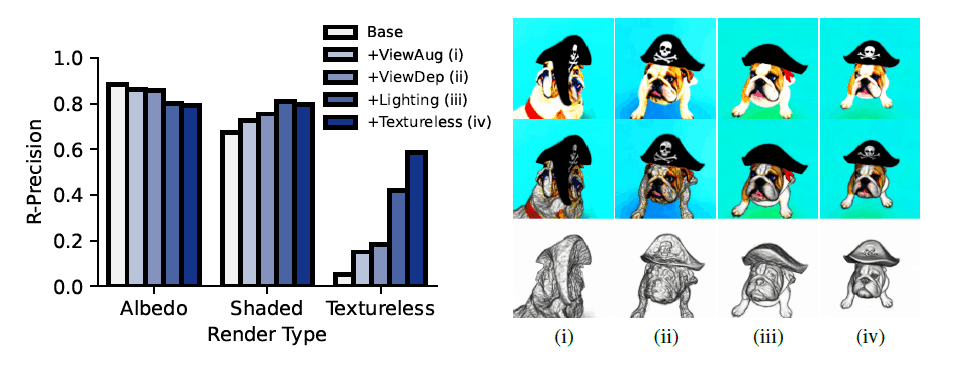
正確なジオメトリを復元するには、ビュー依存のプロンプト、イルミネーション、テクスチャレスレンダリングが必要であることが分かりました。
まとめ
本研究では、新たに考案したSDS( Score Distillation Sampling)と、3D生成タスクに特化したNeRFを組み合わせることで、多様なテキストに対応した忠実度の高い3Dオブジェクトとシーンを生成することが示されました。今回はNeRFからのアプローチでしたが、今後、GANからのアプローチも見込まれるでしょう。また、DreamFusionは64×64のImagenモデルを使用しているため、生成されたオブジェクトの細部が欠ける傾向があります。今後、この問題を解決し、高解像度で扱いやすい3D合成が可能になることが期待されます。
このように、Text-to-Imageなど多角なアプローチを行うことでImage-to-Imageでも新たな方法が出てくるかもしれません。今後、さらにリアリティのある技術となって、デジタルツインやロボティクスでの活躍を期待しています。



この記事に関するカテゴリー





