1行のコードで自動的に学習!機械学習を自動化するAutoMLの最新論文!
3つの要点
✔️ テーブルデータを自動で学習し、高パフォーマンスを発揮するAutoMLフレームワーク
✔️ 既存のAutoMLフレームワークがモデルとハイパーパラメータの選択を重視している一方で、本手法は複数のレイヤーを用いてモデルのアンサンブルとスタッキングを行っている。
✔️ この論文では、主要なAutoMLフレームワークの比較も行っている。
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
written by Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, Alexander Smola
(Submitted on 13 Mar 2020)
Comments: accepted by ICLR 2020 Conference
Subjects: Machine Learning (stat.ML); Machine Learning (cs.LG)
はじめに
AutoML(Automated Machine Learning: 自動化された機械学習)とは、その名の通り機械学習モデルの設計・構築を自動化するための手法全般を指す用語です。ニューラルネットワークの構造を自動で探索するNAS(Network Architecture Search)やモデルのハイパーパラメータを探索するHPO(Hyper Parameter Optimization)もAutoMLの一部と言えるでしょう。
AutoMLの魅力は、なんと言っても特別な機械学習や深層学習の知識がなくても強力な機械学習モデルの構築が可能になることです。また、すでに機械学習に精通しているエキスパートにとっても、モデル・アンサンブル手法・ハイパーパラメータの選択や特徴量選択・データの前処理といった作業はコストが高く、AutoMLを使うことでより効率的な作業が可能なります。
今回紹介するAutoGluon-Tabularは、なんと1行のコードだけで未加工のテーブルデータ(エクセル表のように各行が個別のデータになっているようなデータ)を自動で前処理から学習まで行えてしまう非常に便利なフレームワークになっています。
AutoMLにおけるCASHとは?
AutoMLにおいてCASH(Combined Algorithm Selection and Hyperparameter optimization problem)とは、最適な機械学習モデル(algorithm)とそれに対応したハイパーパラメータ(hyperparameter)を探索するタスクを指します。この探索空間はほとんどの場合非凸かつ非連続なため、計算コストが非常に高くなってしまうと言う特徴があります。例えば、よく知られているハイパーパラメータ探索手法としてグリッドサーチがありますが、これは全てのハイパーパラメータの組み合わせを総当たりで調べていく方法のため効率が悪いです。
既存のAutoMLフレームワークと異なり、AutoGluon-TablerはCASHを解くことを重視していません。と言うのも、先に見たようにCASHはモデルとハイパーパラメータの探索タスクであり、モデルに入力するデータの前処理は分析者が行う必要があります。しかし実際機械学習で一番面倒なのはこの部分です。AutoGluon-Tabularは先進的なデータ処理によってこの問題を解決しつつ、ニューラルネットワークや階層構造を持ったアンサンブル手法によってテーブルデータの学習において高いパフォーマンスを実現しています。
AutoGluon-Tablar
本論文の筆者は、AutoMLを設計する上で次のような原則を守ることが重要だと主張しています。
- シンプルさ・・・機械学習に詳しくなくても、生のデータから直接モデルを学習できること。
- 頑健性・・・多種多様な構造化データを扱うことができ、学習が失敗しないこと。
- 耐障害性・・・学習を一旦止めてもまた再開できること。
- 予測可能な学習時間・・・ユーザーが学習にかける時間を指定できること。
それではAutoGluon-Tablerがどのようにこれらの原則を達成しているのか詳しく見ていきましょう。
fit API
今、手元にtrain.csvと言うテーブルデータがあり、予測したいラベルがclassと言う名前の列に入っているとします。この時、AutoGluon-Tablerでは、次のような3行のPythonコードだけで学習と予測が可能です。
from autogluon import TabularPrediction as task #AutoGluonの読み込み
predictor = task.fit("train.csv", label="class") #学習
predictions = predictor.predict("test.csv") #テストデータに対する予測
これだけで、タスクが分類なのか回帰なのか、分類であれば何クラスの分類なのかを自動で判定し、様々なモデルをアンサンブルさせて強力なモデルを学習させます。このように、AutoGluon-Tabularはシンプルさを達成した誰でも使いやすいフレームワークと言えます。
データの前処理
まず、学習するデータがどのようなタスクのためのものなのかを自動で判別します。目的変数の含まれている列を参照し、その値が文字列や離散値であれば分類タスク、連続値であれば回帰タスクと判断します。
タスクを判別した後、前処理は大きく2段階に分かれます、まず全てのモデルに共通する処理を行ったのち、各モデルに適した処理を適用します。前者においては、カテゴリ・数値・テキスト・時刻などのデータが全てカテゴリ変数に変換されます。また、欠損値に関してはunkownと言うラベルが付与されるため、学習時に観測されなかった変数の値がテスト時に現れてもエラーが出ないようになっています。これによって頑健性を保証しています。
モデル
AutoGluon-Tabularでは、多くの選択肢からモデルを選択するのではなく、初めから利用するモデルを絞っています。これによって、余計なモデルを探索する手間をなくし、限られた時間の中で効率的な学習が可能になります。使われるのは次の6つのアルゴリズムです。
- ニューラルネットワーク(中身は後述)
- LightGBM(ブースティング木の一種)
- CatBoost(ブースティング木の一種)
- ランダムフォレスト
- ERT(Extremely Randomized Trees;ランダムフォレストの変種)
- k近傍法
利用するアルゴリズムが6つしかないと言うのは既存のAutoMLフレームワークに比べてかなり少ないです。ちなみに実装はsklearnを使っています。
Multi-Layer Stack Ensembling
※本論文では次の「ニューラルネットワーク」の章が先に来ますが、分かりやすさを考慮して逆にしています。
アンサンブル学習(ensembling)とは、簡単に言えば複数のモデルの出力を組み合わせる手法で、一般にそれぞれのモデル単体よりも性能が改善することが知られています。AutoGluon-Tabularが用いているのはその中でもスタッキングと呼ばれる手法であり、複数のモデルの出力の重み付き和を最終的な出力とすると言うものです。スタッキングの重みは線形モデルなどを使って学習されます。
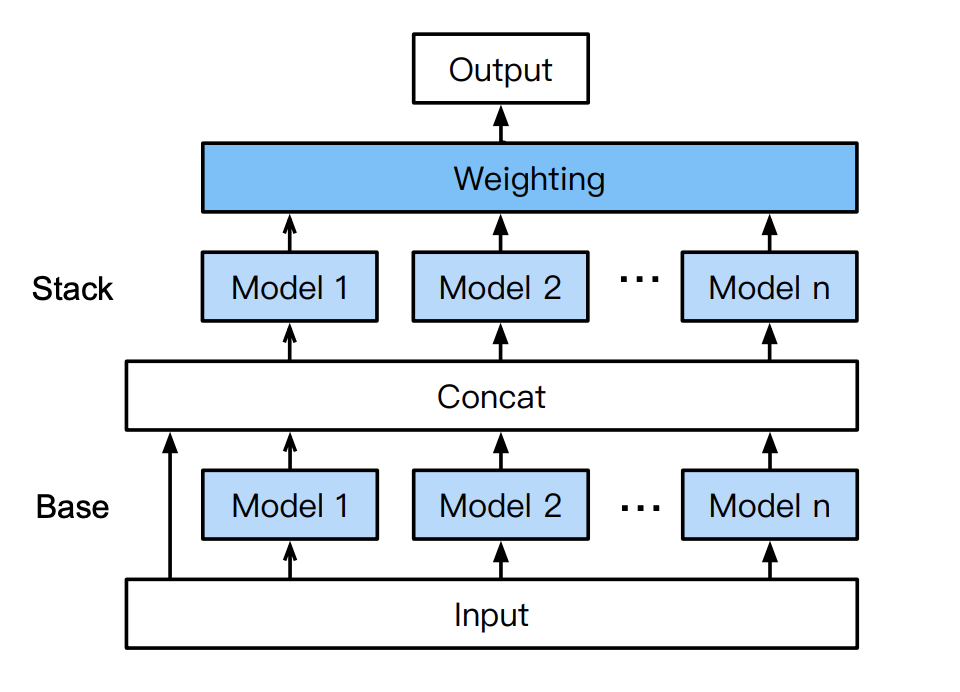
上図はAutoGluon-Tabularの多層スタッキング構造を表しています。学習の流れは以下の通りです。
- n個の独立したモデル(6つのアルゴリズムから選択)に前処理をしたデータ(input)を入力
- 1.の各モデルの出力と、inputを結合させ、1.と同じアルゴリズム・同じハイパーパラメータのモデルに入力
- 2.の各モデルの出力の重み付き和を最終的な出力とし、誤差を計算して学習
従来AutoMLで使われてきたスタッキングは、単純に別々のモデルの出力の重み付き和を計算するものでしたが(単層スタッキング)、AutoGluon-Tabularでは、各モデルの出力と元の入力をスキップコネクションで結合し、それをまたそれぞれのモデルに入力してからスタッキングしています(多層スタッキング)。この構造は、画像認識タスクで高性能を発揮しているResNetやMobileNetなどの構造(シンプルな構造の層方向積み重ね+スキップコネクション)の応用と言えます。
こうすることで、スタッキングを行う際に、各モデルの出力だけでなく、元の入力データも考慮することができるようになり、従来の単層スタッキングより性能を向上することができるのです。
ニューラルネットワーク
画像やテキストにニューラルネットワークが利用され上手く働くのは、ニューラルネットワークがこれらのデータから意味のある重要な情報を選び出すことが得意(例えば、画像処理における畳み込み)だからです。しかし、テーブルデータはそれぞれの列に性別・年齢・体重・身長・・・と言った意味のある(=それぞれの性質が異なる)変数が格納されているため、いろいろな変数を線形和としてブレンドしてしまうニューラルネットワークより、決定木系のアルゴリズムの方がテーブルデータのパターン認識に適していると言えます。
しかしまた一方で、決定木系のアルゴリズムのアンサンブルの中に、適切にチューニングされたニューラルネットワークを加えることで性能が向上すると言う研究もあり(性格の違うアルゴリズムを混ぜることで、アンサンブルモデルのバリアンスを小さくすることができる)、テーブルデータ学習で精度向上を目指すためにも、上手くニューラルネットワークを活用することが課題でした。他の主なAutoMLフレームワークも、ニューラルネットワークを利用するものはありますが、多くは単純なMLP(多層パーセプトロン)を利用することに留まっています。
そこでAutoGluon-Tabularでは下図のような構造のニューラルネットワークを提案しています。
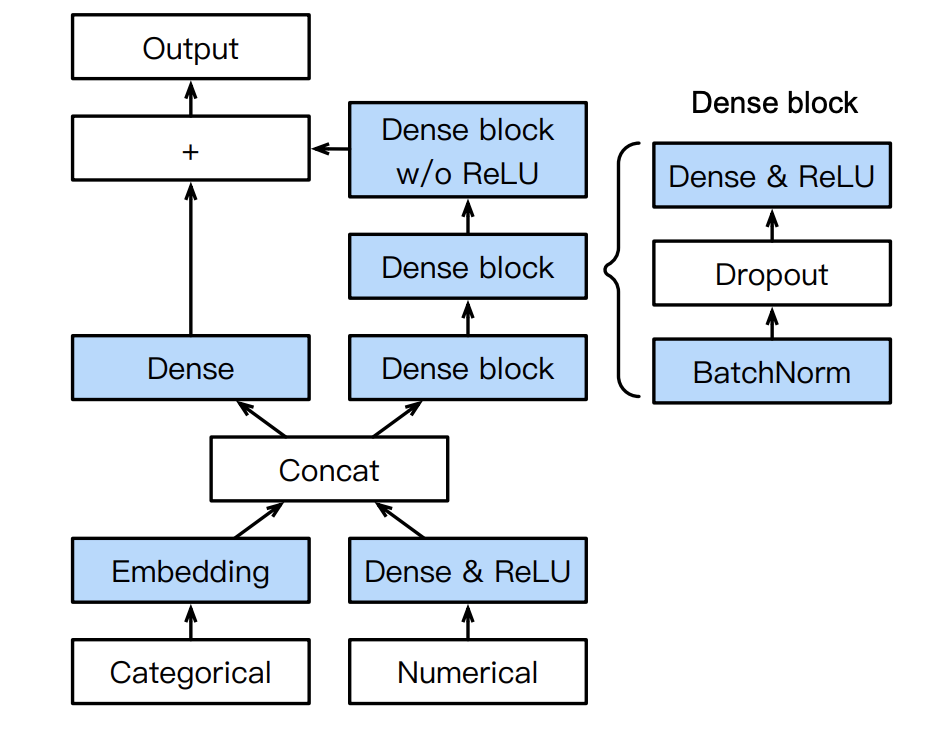
カテゴリデータと数値データをまとめてDense層に入れるのではなく、カテゴリデータはEmbedding層によって埋め込み、数値データはDense層に通しReLUで活性化したものを結合します。こうすることで、元々カテゴリデータだったものと数値データだったものが線形和としてブレンドされる前に、両方の特徴量をニューラルネットワークが別々に学習できるようになります。さらに、ここでもスキップコネクションを用いることで、元のテーブルデータの性質を忘れにくくする(各変数をブレンドしてしまうことを防ぐ)効果を生んでいます。
Repeated k-fold Bagging
まず、k-foldについて説明します。データセットをk個のグループ(fold)に等しく分割し、そのうちの1グループ(fold)をテストデータ、他のグループ(fold)を訓練データとし1つのモデルを学習します。これをk回グループ間でテストデータをローテーションすることでk個のモデルを作り、最終的な予測値は、(多くの場合)k個のモデルの出力の平均値をとする、と言うものです。いわゆる交差検証の手法です。
Repeated k-fold Baggingと言うのは、k-foldを指定した回数(n回)繰り返す手法です。AutoGluon-Tabularの学習方法を疑似コードで見てみましょう。
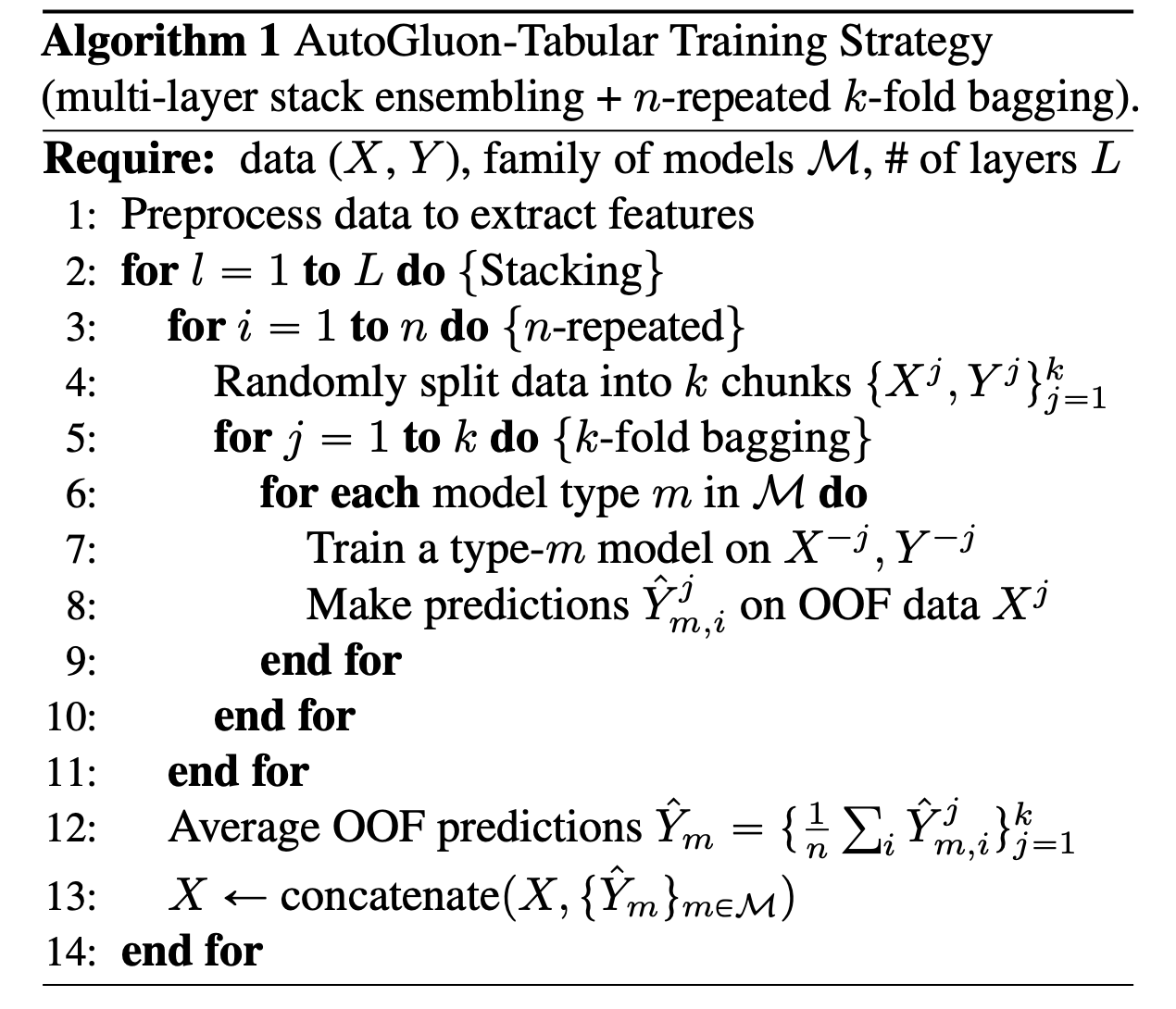
3行目から始まるfor文を見ると、多層スタッキングモデルの各層の学習を始める際に、毎回ランダムにデータをk分割するように書かれています。これをn回繰り返せ、と言うのがこのfor文の指示です。最終的に一つの層の出力はそれぞれのfoldの出力の平均となっています。
Repeated k-fold Baggingを利用することで、foldに含まれるデータ数が少ない場合でも、モデルの過学習を防ぐことができます。
AutoMLフレームワークの比較
- Auto-WEKA:AutoMLの元祖。Javaの機械学習ライブラリであるWEKAにおけるCASHをベイズ最適化によって解いています。
- Auto-Sklearn:おなじみPythonの機械学習ライブラリscikit-learnにおけるCASHを解きます。ハイパーパラメータの探索にメタ学習を利用しているのが特徴です。
- TPOT:進化的アルゴリズムを使って機械学習プロセスを最適化するツールです。
- H2O AutoML:特にKaggleのコンペにおいてよく用いられているライブラリです。ハイパーパラメータ探索にランダムサーチを用いているにもかかわらず、しばしば他のライブラリよりも好成績を出す点が面白いです。
- GCP-Tables:GCP(Google Cloud Platform)にリリースされたAutoMLツールで、生のデータをアップロードすれば簡単に機械学習ができます。ただしGoogle Cloudにおいてしか利用できず、オープンソースでないため内部はわかっていないことが多いようです。
- その他(名前のみ、オープンソース):auto-egboost, GAMA, hyperopt-sklearn, OBOE, Auto-Keras
- その他(名前のみ、商用ソフト):Sagemaker, AutoPilot, Azure ML, H2O Driverless AI, DataRobot, Darwin AutoML
| 名前 | オープンソース | 生データ対応 | ニューラルネットワーク | CASH戦略 | アンサンブル手法 |
| Auto-WEKA | ◯ | × | シグモイドMLP | ベイズ最適化 | Bagging, Boosting, Stacking, Voting |
| Auto-Sklearn | ◯ | × | なし | ベイズ最適化+メタ学習 | Ensemble Selection |
| TPOT | ◯ | × | なし | 進化的アルゴリズム | Stacking |
| H2O | ◯ | ◯ | MLP+AdaDelta | ランダムサーチ | Stacking + Bagging |
| GCP-Tables | × | ◯ | AdaNet(??)* | AdaNet(??)* | Boosting(??)* |
| AutoGluon | ◯ | ◯ | カテゴリ変数の埋込+スキップ接続 | デフォルトでは無し | Multi-Layer Stack Ensembling + Repeated k-fold Bagging |
*GCP-Tableはオープンソースではないため、フレームワークの細かい仕様は不明です。
実験と結果
OpenML AutoML BenchmarkとKaggleのコンペティションから集めた50のテーブルデータを用いて、制限時間4時間での学習結果を比較しました。Wins/LossesにはそのフレームワークがAutoGluon-Tabularに勝った回数、Failureには学習が失敗した回数、Championにはそのフレームワークが1位だった回数が記録されています(上がOpenML、下がKaggleにおける結果)。GCP-Table以外は、全て同じ型のEC2インスタンスによって学習を行いました。いくつかのフレームワークは制限時間をオーバーしてしまったようです。
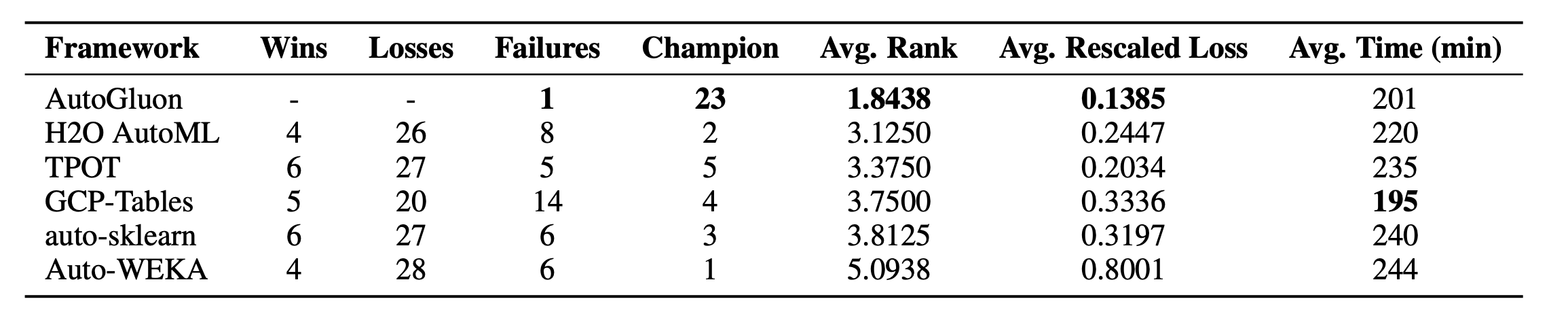
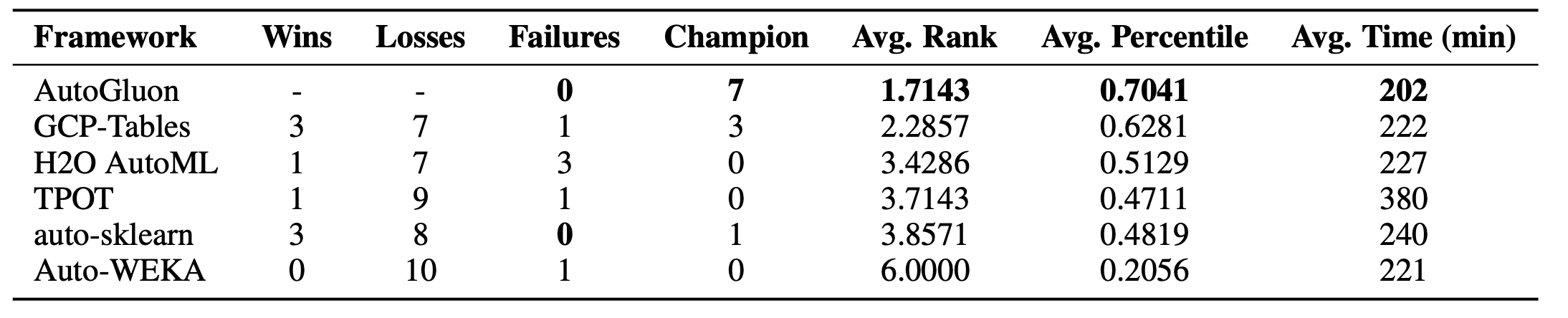
結果を見ると、AutoGluon-Tabularは、50のデータの内30のデータで1位を記録しており、これは他のフレームワークに比べて圧倒的です。また、OpenMLのデータでは学習が失敗してしまうフレームワークが少なくないのですが、AutoGluon-Tabularは1回失敗したのみでした。学習にかかった時間も、OpenMLでは一番短く、Kaggleでも2番目に短くなっています。
以上から、AutoGluon-Tabularは、頑健性、耐障害性、学習時間の短さにおいてこれまでのフレームワークよりも優れていると言えそうです。また、今回の実験ではAutoGluonはハイパーパラメータの最適化をオフにしています。にもかかわらず他のフレームワークを圧倒しているのは、AutoMLにおいてCASHは最重要な問題ではないと言うことを示しています。
結論
本論文では、非常に短いコードでテーブルデータを自動で学習できるAutoMLフレームワーク、AutoGluon-Tabularが提案されました。
AutoGluon-Tabularのキーポイントは
- 様々な変数を含んだテーブルデータを処理できる頑健なデータ処理技術
- 先進的なニューラルネットワークを利用していること
- 多層スタッキングとrepeated k-fold baggingによる強力なアンサンブル学習
の3つと言えます。また、それまでAutoMLイコールCASHといえるほど、AutoMLタスクにおいて重視されていたCASHが、実はAutoMLタスクの1側面にすぎない、と言うことを示したことも大きな成果だと言えます。
誰でも簡単に機械学習できる時代はもうすぐかもしれません。今後もAutoML技術の発展には注目ですね。



この記事に関するカテゴリー




