
BERTでツイートのバズり度を予測できる!?
3つの要点
✔️ ツイートテキストの特徴量とユーザーベースの特徴量を用いてツイートのvirality(=バズり度)を予測するViralBERTを提案
✔️ 本手法により、F1 ScoreとAccuracyの両方でベースラインより13%も高いパフォーマンスを達成
✔️ Ablation studyにより、テキストの感情情報やフォロワー数などが予測において最も効果的な特徴であり、ハッシュタグ数を含めることで予測精度が低下することを発見
ViralBERT: A User Focused BERT-Based Approach to Virality Prediction
written by Rikaz Rameez, Hossein A. Rahmani, Emine Yilmaz
(Submitted on 17 May 2022)
Comments: UMAP 2022
Subjects: Computation and Language (cs.CL); Social and Information Networks (cs.SI)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
近年、ユーザーに情報を共有・拡散するためのソーシャルネットワークサービスとしてTwitterが世界中で使用されており、個人だけでなくあらゆる企業のマーケティングにおいても重要視されています。
Twitterにおいて、ユーザーは気になった投稿を「リツイート(retweet)」することで簡単に他のユーザーに共有することができ、より多くのユーザーに投稿が伝播することでその影響力を強めることができます。
このようにある投稿がどの程度リツイートされるか、すなわちどの程度の影響力を高めることができるかを知ることは、広告やインフルエンサーにとって大きな価値を持ちます。
本稿では、ハッシュタグやフォロワー数などの数値特徴量をツイートテキストに連結する手法を採用し、テキストと数値特徴量を組み合わせて学習を行うBERTモジュールと、テキスト内の情報と感情的反応を引き出す能力がリツイート傾向に関係することから、テキストの感情分析のみを行うRoBERTaモジュールにより、ツイートのvirality(=バズり度)を予測するViralBERTについて紹介します。
時代背景と問題定義
Twitterは、月間アクティブユーザー数が3億人を超える世界最大級のソーシャルメディアであり、Twitterのユーザーは「ツイート(tweet)」と呼ばれる最大280文字のテキストを共有し、写真やGIF、ビデオを送付することができます。
あるツイートが他のツイートよりも多くのインタラクションを獲得し、Twitter上で多くのユーザーから注目を集めると、そのツイートはviralしたことになります。
このようにviralityはTwitter上だけでなく、社会全体のトレンドやトピックの人気度やエンゲージメントを判断するために利用することができ、ツイートのviralityを予測することは非常に重要です。
しかし、viralityの予測に関する最近の研究は限られており、これらの研究はユーザーベース全体からのツイートではなく、ツイートの特定のサブセットや特定のユーザーに焦点を当てており、ユーザーやツイート全体への一般化はできていませんでした。
さらにviralityの予測は、ユーザーとの親和性、コンテンツ(ツイートの内容)の創造性、現在の社会情勢との関連性など、容易に定量化できない多くの要因に影響され、加えてほとんどのツイートはリツイートされることがないため大規模なデータセットを作成することも難しいことから、非常に困難な問題となっていました。
本論文の概要
本論文ではこうした問題を解決するために、330kのツイートからなるサンプルデータセットを構築し、この問題に対してBERTアーキテクチャを用いてツイートのviralityを予測できるか検証しました。
dataset
本研究のデータセットはPythonを用いたTwitter API v2によって収集されており、Cryptocurrencies・TV&Movies・Pets・Video Games・Cell Phones・COVID-19・Football・K-popの8つのトピックに限定しています。
また、本研究ではオリジナルの(リツイートされた投稿ではない)英語のツイートから、テキスト・作成時間・ハッシュタグ数・メンション数・ツイート元クライアントについて、ユーザーから、フォロワー・フォロー数・ステータスについて収集しています。
加えて、リツイート数・いいね数・返信数・引用数はツイート作成から24時間後に取得されます。(この時間までにツイートのviralityが限界に達することが既存研究にて分かっているため)
ViralBERT
本論文で提案されたViralBERTのアーキテクチャを下図に示します。
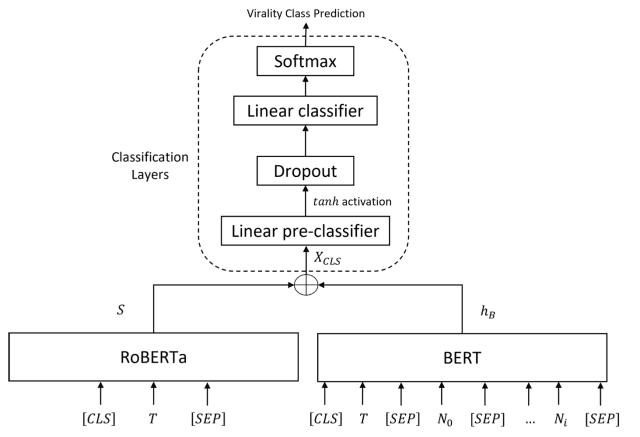
本モデルは、BERTを用いてツイートテキストとそれに付随する数値特徴量(ハッシュタグ・メンション・フォロワー・フォロー数・ステータス・テキストの長さ)を組み合わせた特徴量からの出力を、RoBERTaを用いてツイートテキストの感情特徴量の確率分布を出力し、これを分類層に与えることでviralityを予測します。
BERTモジュール
BERTで使用する事前学習済みモデルであるBERTweetは850Mのツイートコーパスでファインチューニングされており、幅広いトピックとユーザーからのツイートで使用される言語に対して最適化されています。
このモデルに対してツイートテキストTとそれに付随する数値特徴量(N0,N1,...,Ni)を連結したものを入力し、その出力hBが分類層に入力されます。
これを式に表すと下のようになります。
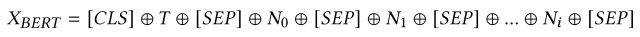
RoBERTaモジュール
既存研究によりツイートの感情特徴量はツイートの伝播に直接影響することが分かっており、本モデルではツイートテキストの感情分析にRoBERTaベースの事前学習済みモデルを採用しています。
このモデルの出力はツイートテキストから得たネガティブ・ニュートラル・ポジティブな感情のソフトマックス確率分布Sであり、前述したBERTの出力と同様に分類層に入力されます。
分類層
BERTの出力hBとRoBERTaの出力Sが分類層への入力として連結され、出力は以下の式になります。
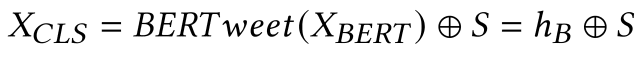
この出力にソフトマックス関数を適用することでviralityの確率を得ることができます。
Experiments
本論文ではViralBERTの性能を、既存研究にある同様のタスクのために開発された以下のベースライン手法と比較しました。
- ロジスティック回帰(Logistic Regrassion):勾配最適化のためにNewton法を採用しており、この手法は人気メッセージの予測に利用されている。
- サポートベクターマシン(Support Vector Machine, SVM):ヒンジ損失とSGD最適化を採用しており、この方法はTwitterで新しく登場したハッシュタグの人気度を予測したり、リツイートのしやすさを評価するのに利用されている。
- 決定木(Decision Tree Classifier):Gini impurity scoreを用いて最大深度なしで分類を行う。この方法は、リツイートのしやすさを評価するのに利用されている。
- ランダムフォレスト(Random Forest Classifier):最大深度なしで100本の木を利用する。このベースラインはリツイート数とリツイートの可能性の時間的予測に焦点を当てた既存研究に基づいている。
加えて、本モデルの数値特徴量のみを用いたMLPNum、テキスト特徴量のみを用いたViralBERTTextの2つのベースラインを追加し、これらの特徴量がどのように機能するかを検証しました。
実験結果は下の表のようになりました。(最も良い結果を太字で示しています) 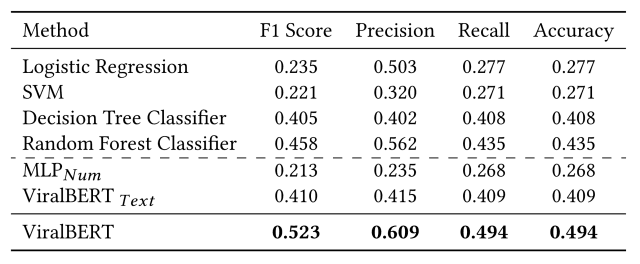
この実験から以下の事が分かります。
- ViralBERTをテキスト特徴量のみで学習した場合、通常のViralBERTと比較して最適な性能を得る事が出来ていない
- 数値特徴量のみで学習した場合、テキストのみを用いた場合と比較して性能が大幅に向上しており、数値的な特徴もviralityの予測に重要な要素であることが分かった
- テキスト特徴量と数値特徴量を連結した入力に対してViralBERTをファインチューニングし、分類層を学習させることで、ベースラインよりも大幅に高い評価指標を達成する事が出来ている
加えて、入力から特徴量を取り除きモデルの性能を比較することで、ViralBERTに対する各特徴量の重要性を測定する実験を行いました。
下の表は、入力から各特徴量を排除した際のViralBERTとの比較結果になります。
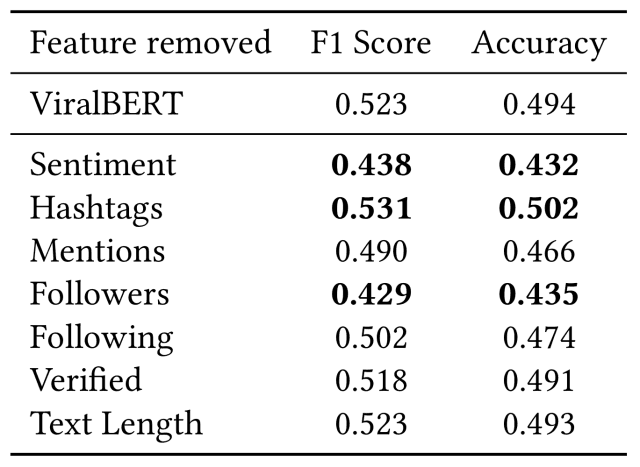
この実験から以下の考察が得られました。
- ネットワークからSentiment(ツイートの感情特徴量)またはFollowers(フォロワー数)を排除すると、他の特徴量と比較してモデルの性能が大幅に低下する
- これは直感的なもので、フォロワー数が多いユーザーは1つのツイートでより多くの注目を得る可能性が高いためだと思われる
- また、ユーザーにより大きな感情的な反応を引き起こすツイートは、より多くのリツイートを得るかもしれない
- また、Mentions(メンション数)とFollowing(フォロー数)は前述の2つの特徴量よりは小さいものの、性能に影響を与える
- これは、人気のあるユーザーほど他人をフォローしない(フォロワー・フォロー比率が高い)傾向があるためだと考えられる
- また、メンション数が多いツイートは可読性に欠け、ユーザーにとって有益な情報に使えるはずのスペースを利用しているため、リツイートされる可能性が低くなっていると考えられる
- 最も驚くべき結果は、Hashtags(ハッシュタグ数)を排除すると、モデルのパフォーマンスがわずかに向上することである
- これは、この特徴量がviralityに関係していないため、この特徴量を追加することでBERTが入力からより悪い表現を学習している可能性を意味している
これらの結果は、より大きなデータセットと各特徴量間の相互作用のテストを含むより包括的な研究でさらに調査されるべきであり、これらが性能に悪影響を及ぼす理由を解明することが今後の課題になると考えられます。
まとめ
いかがだったでしょうか。今回は、ツイートのテキスト特徴量と数値特徴量の両方を用いてツイートのviralityを予測するBERTベースの手法であるViralBERTについて紹介しました。
本モデルにより既存手法を上回るviralityの予測精度を達成しましたが、本論文で使用したデータセットがアンバランスであるといった課題も残っており、データセットに存在するクラスの不均一性を解消することでさらに予測精度を向上させることができるかもしれません。また、フォロワー数がviralityに影響することが判明したため、人気のないユーザーからviralityの高いツイートを収集することで、より良いデータセットを作成することができると思われます。加えて、本モデルを別のソーシャルメディアに利用することで様々な媒体のviralityを予測することができる可能性もあるため、今後の動向が非常に楽しみです。
今回紹介したモデルのアーキテクチャやデータセットの詳細は本論文に載っていますので、興味がある方は参照してみてください。




この記事に関するカテゴリー






