
I-BERT:整数型のみで推論可能なBERT
3つの要点
✔️ BERTの計算をすべて整数型で実現したI-BERTを提案
✔️ Softmax、GELUを2次多項式で近似する新たな方法を導入
✔️ 量子化なしの場合と比べて2.4~4.0倍の高速化を達成
I-BERT: Integer-only BERT Quantization
written by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer
Submitted on 5 Jan 2021 (v1), last revised 8 Jun 2021 (this version, v3)
Comments: ICML 2021 (Oral)
Subjects: Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
BERTやRoBERTaといったTransformerベースのモデルは多くの自然言語処理タスクにおいて高い精度を示しています。一方で、メモリフットプリント(参照するメモリの容量)や推論にかかる時間や消費電力がエッジだけでなくデータセンタにおいても課題となっています。
この課題を解決する手法の1つに、モデルの重みや活性度を32ビット浮動小数点数(FP32)の代わりに、8ビット整数(INT8)などの低ビット精度で表現することでモデルを軽量化する、モデル量子化という方法があります。
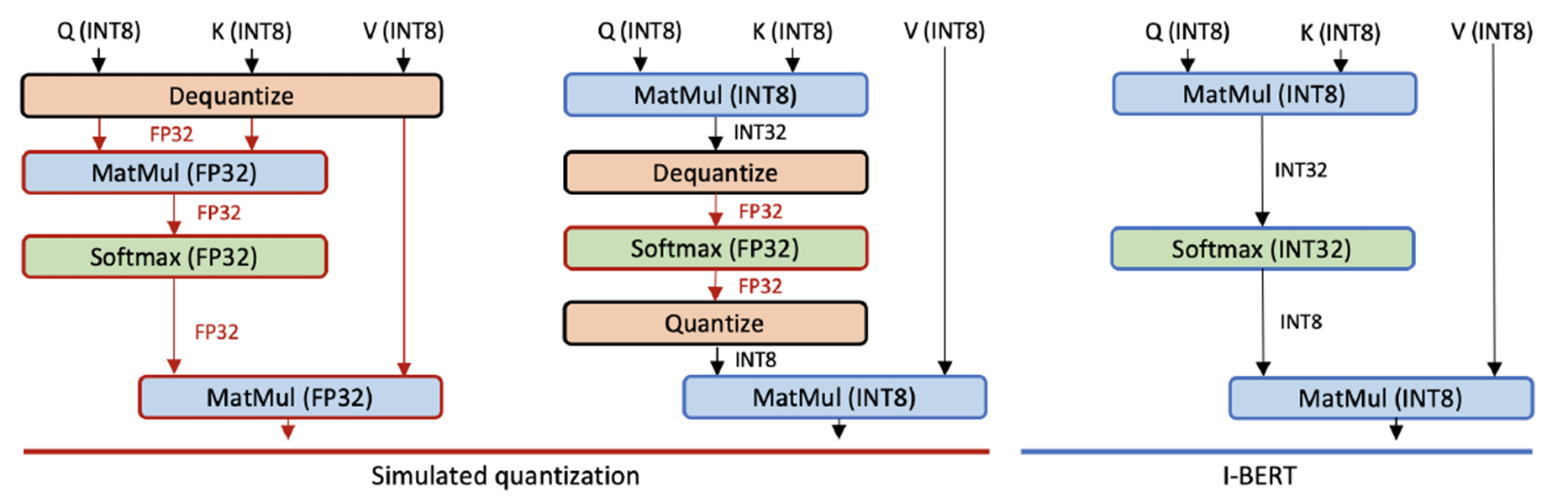
これまでTransformerベースのモデルに対して行われてきたモデルの量子化は入力や線形演算部分に限られたものとなっており、完全なモデルの量子化は行えているとは言えません(上図のSimulated quantization)。
そこで、本論文では、BERTにおけるすべての演算を整数型で実現したI-BERTを提案しています。
提案手法:I-BERT
Basic Quantization Method
浮動小数点型から整数型への量子化はsymmetric uniform quantizationを用いて以下のように行っています。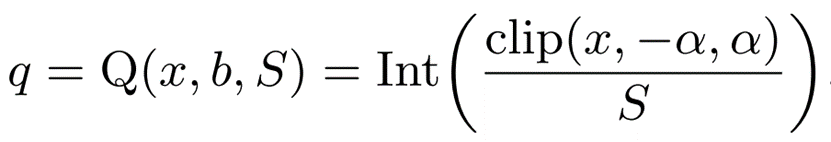
xは量子化前の浮動小数点数、qが量子化後の整数値を表しています。
qに対応する浮動小数点数(x)の範囲が一定となるためuniform quantizationと呼ばれます。qに対応する浮動小数点数の範囲を動的に変更するnon-uniform quantizationのほうが、重みや活性化パラメータの分布を捉えられる可能性がありますが、オーバーヘッドを引き起こす原因となるため、uniform quantizationを用いています。
bはビット精度で、これによりqが表現できる値の範囲が次のように決まります。
![]()
clipはtruncation function(切り捨て関数)、αはその範囲をコントロールするパラメータです。この方法がsymmetricと呼ばれるのは、clipにより[-α,α]とsymmetric(対称)に値を切り捨てている点にあります。asymmetric quantizationでは、範囲の左側と右側で値が異なります。
Sはスケーリング係数です。Sは推論時、以下のように固定し、実行時のオーバーヘッドを避けます (static quantization)。
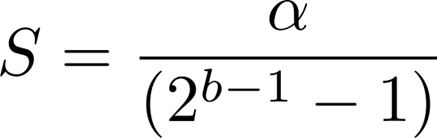
Non-linear Funcitons with Integer-only Arithmetic
先行研究において、整数型のみの演算は線形性を利用しているため、線形演算や区分線形演算は容易に行うことができます。たとえば、MatMul(行列積)では以下の式のように、量子化された値qにスケーリングファクターSをかけることで計算できます。
![]()
一方、GELUなどの非線形関数は以下の式のように、線形性を満たさないため、簡単に計算することができません。
![]()
この課題に対して、この論文では非線形関数を整数演算のみで計算可能な多項式関数に近似することを提案しています。
Polynominal Approximation of Non-linear Functions
非線形関数を多項式関数に近似する方法にinterpolating polynominalsを用いています。
以下の式のように、n+1点の関数のデータ集合に合う、次数nまでの多項式を求めます。
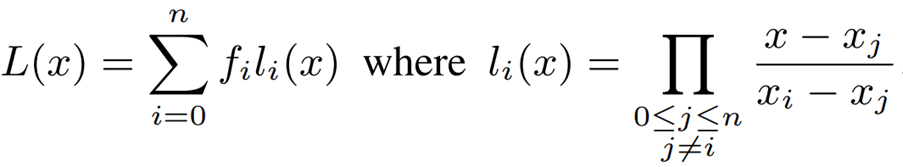
ここで、次数nの選択がポイントとなります。次数が大きいほど近似誤差は小さくなりますが、「オーバーヘッドや計算量の増大を招く」、「低演算ビットで計算する際にオーバーフローが発生する可能性がある」といった課題が生じます。
以上のことから、Transformerで使用される非線形関数(GELU、Softmax)を近似できる低次多項式を見つけることが課題と言えます。以下で、この論文で提案するGELUとSoftmaxの近似方法について詳しく見ていきます。
Integer-only GELU
GELUはtransformerモデルで用いられる活性化関数であり、次のように表すことができます。
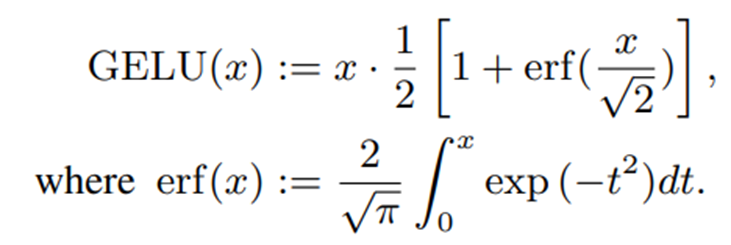
erf(誤差関数)の積分項は計算効率が悪いため、様々な近似方法が提案されています。
たとえば、シグモイド関数を用いた以下のような近似があります。
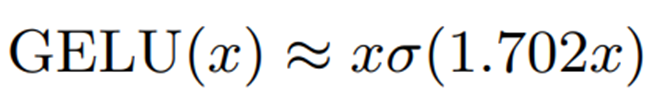
シグモイド関数(σ)自体が非線形関数であるため、整数演算のための近似方法としては適していません。
シグモイド関数をhard Sigmoid(h-Sigmoid)で近似する方法もあります。この論文ではこの近似法をh-GELUと呼びます。
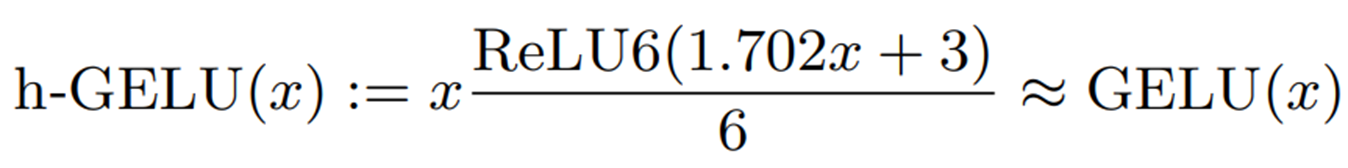
h-GELUは整数型のみの演算を行うことができますが、近似の精度が下がってしまう問題があります。
そこで、この論文では誤差関数を2次元多項式で近似することを提案しています。
近似のために、以下のような最適化問題を考えます。
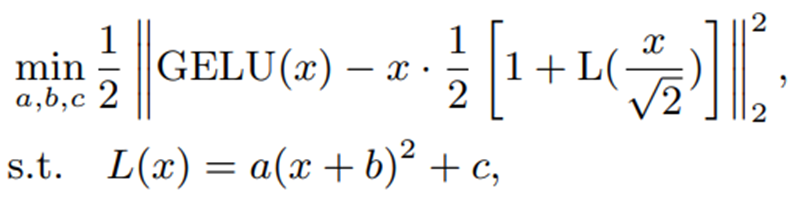
L(x)が誤差関数を近似する2次多項式を表しています。定義域を実数全体として最適化を行うと、近似精度が下がってしまいます。
これを解決するため、xが大きいとき誤差関数は1に近づくことを利用し、限られた範囲での近似を考えます。また、誤差関数が奇関数であるため、正の領域のみを考慮します。
このような条件の下、上で説明したinterpolating polynominalsを利用して近似すると次のようになります。
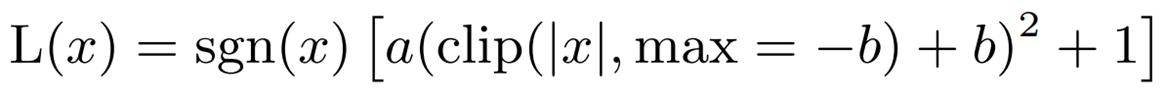
a = -0.2888、b = -1.769であり、sgnはsign function(符号関数)です。この多項式を用いたGELUの近似(i-GELU)は次のように表すことができます。
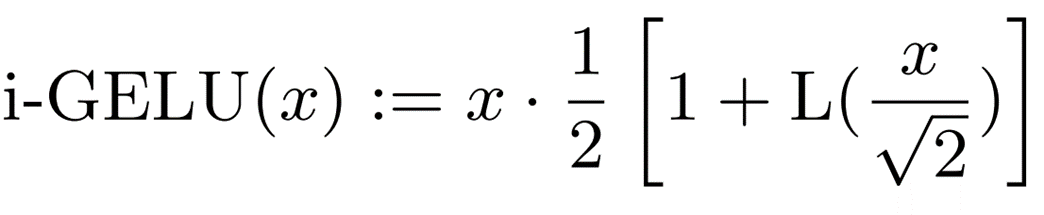
i-GELUで演算する際のアルゴリズムは以下の通りです。

i-GELUと既存のシグモイド関数を用いた方法、h-GELUを比較したのが、以下のグラフです。
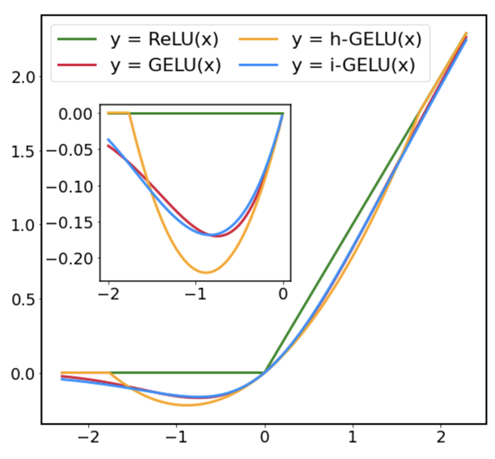
近似精度(L2、L∞距離)において定量的に比較した結果が以下の表です。グラフからも表からもi-GELUの近似精度が最も良いことが分かります。

Integer-only Softmax
Softmaxは以下の式で表され、入力されたベクトルを確率分布に変換することができます。
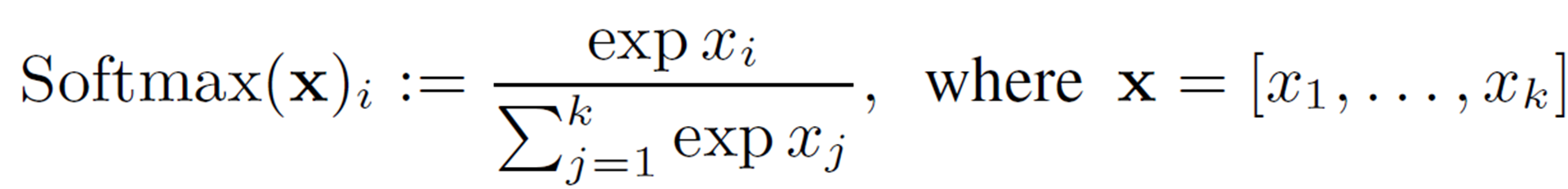
GELUと同様に、範囲を限定して2次多項式で近似することを考えます。まず、数値的安定性(オーバーフローを防ぐ)のために入力の値を最大値(![]() )で引きます。
)で引きます。
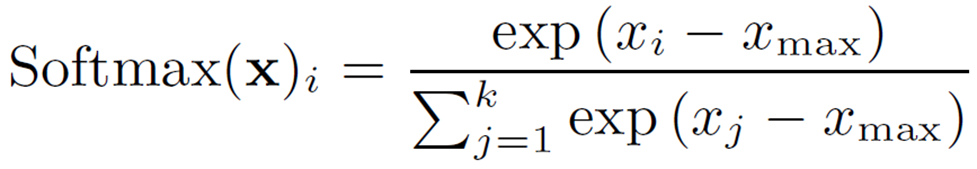
ここで、![]() を次のように分解します。
を次のように分解します。
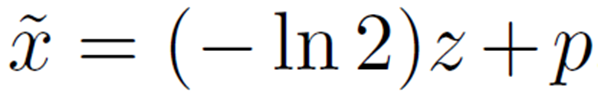
z、pはそれぞれ-ln2で割ったときの商、あまりを表しています。このときSoftmaxの指数関数部分は次のように表現することができます。
![]()
したがって、![]() においてexp(p)を近似することを考えます。GELUのときと同様、上で説明したinterpolating polynominalsを適用すると次のように近似ができます。
においてexp(p)を近似することを考えます。GELUのときと同様、上で説明したinterpolating polynominalsを適用すると次のように近似ができます。
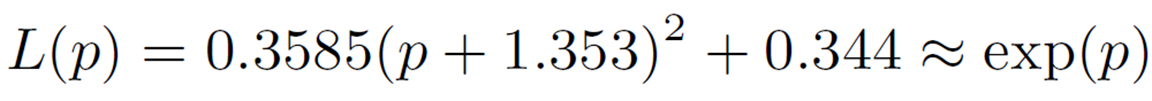
したがって、![]() は次のように計算できます。
は次のように計算できます。
![]()
ここで![]() 、
、![]() です。この指数関数の近似についてグラフで確認すると次のようになります。
です。この指数関数の近似についてグラフで確認すると次のようになります。
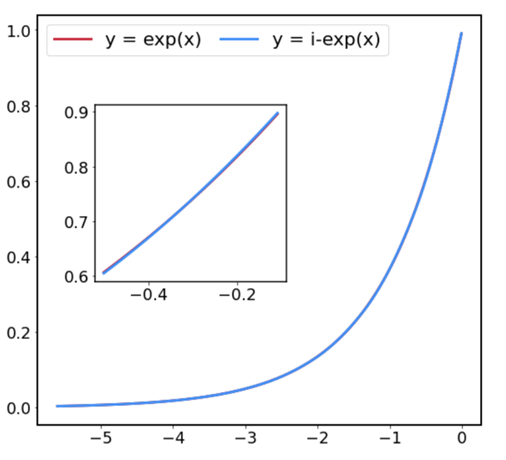
最大の誤差は![]() であり、8bitの量子化誤差が
であり、8bitの量子化誤差が![]() であることを考えると誤差は十分小さいことが分かります。最後にここまでをまとめ、整数型でSoftmaxを計算するアルゴリズムを以下に示します。
であることを考えると誤差は十分小さいことが分かります。最後にここまでをまとめ、整数型でSoftmaxを計算するアルゴリズムを以下に示します。

Integer-only LayerNorm
LayerNormはチャネル次元間で入力された特徴を標準化するもので、以下の式で表されます。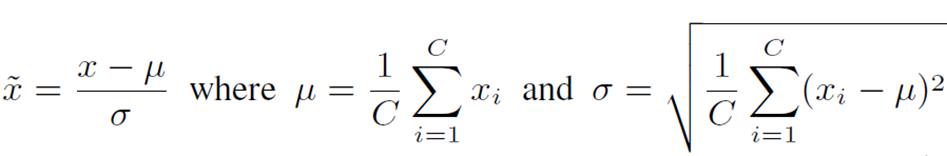
μとσはそれぞれ平均と標準偏差を表しています。
標準偏差を計算するうえで必要な平方根演算は整数型で直接計算するのが困難です。そこで、[1]で提案されているニュートン法を用いたiterationアルゴリズムを用いて計算します。
アルゴリズムは以下の通りです。

実験
精度評価
I-BERTの推論精度から見ていきます。GLUEと呼ばれるベンチマークタスクにおいて、RoBERTa-BaseとRoBERTa-Largeのモデルで検証を行っています。
結果を以下の表に示します。

RoBERTa-BaseではMNLI-m、QQP、STS-Bのタスク以外においてFP32(浮動小数点数)で演算したときよりも高い精度を示しました。
精度が低下したものでもその差は最大で0.3%であり、非常に小さいです。平均的にみれば0.3%精度が向上しています。RoBERT-LargeについてはすべてのタスクにおいてI-BERTの精度が上回っており、平均で0.5%の精度向上が確認されています。
以上のことから、I-BERTはFP32と比較して同程度あるいはわずかに高い精度を達成していることが分かります。
推論速度評価
I-BERTの推論速度についても検証を行っています。
下の表は各文章長(SL)、バッチサイズ(BS)において、FP32と比べてどのくらい高速化したかを示しています。モデルはBERT-BaseとBERT-Largeを用いています。
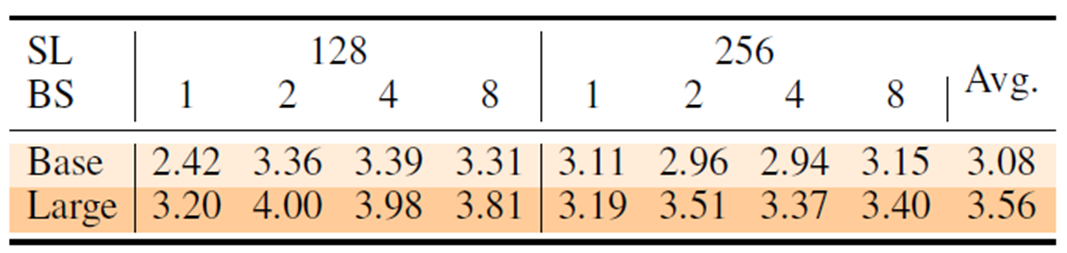
INT8型の推論を行うI-BERTは、FP32で推論を行ったときよりも、平均でBERT-Baseでは3.08倍、BERT-Largeでは3.56倍の高速化を達成していることが分かります。
Ablation Study
I-BERTで採用しているGELUの近似手法であるi-GELUの有効性の検証も行っています。
RoBERa-Large Modelにおいて、精度評価のときと同じGLUEのタスクで近似なしのGELU、h-GELU、i-GELUを比較した結果が以下の表になります[2]。
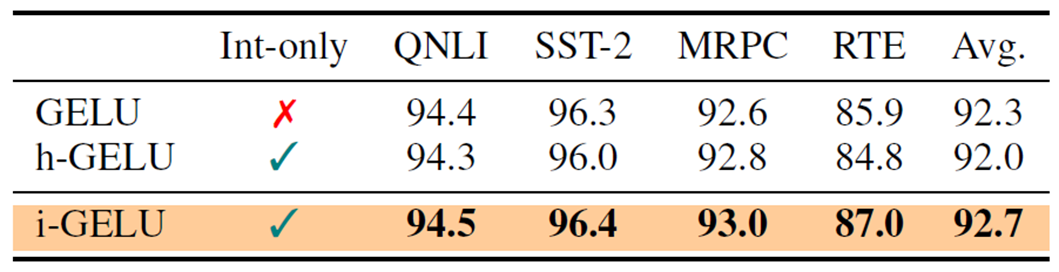
h-GELUではMRPC以外のタスクにおいて、GELUよりも精度が低下していることが確認できます。これは、h-GELUの近似精度が十分ではないことを示しています。
i-GELUはすべてのタスクにおいてh-GELUの精度を上回っており、GELUと比べても同等あるいはわずかに良い精度を示しています。この結果からi-GELUの近似は適切であると言えます。
まとめ
今回はすべての計算を整数型で実現したBERTであるI-BERTについて紹介しました。大きな精度の低下がなく、3倍程度の高速化を達成している点は大きな魅力だと思います。
秘匿性を保つ必要がある情報を手元の自然言語モデルで処理したいケースでは、I-BERTのような計算処理が軽いモデルに需要があるのではないかと感じました。
補足
[1]Prime Numbers: A Computational Perspective | SpringerLink
[2] Tesla T4 GPUにおいて検証が行われています。






この記事に関するカテゴリー






