チャートに対する質問に回答するCQAタスクの新たなSoTAモデルが登場!
3つの要点
✔️ Transformerを用いた新しいCQAモデルであるClassification-Regression Chart Transformer(CRCT)を提案
✔️ 提案モデルの有効性を実証するために、大規模かつ多様なチャートからなるデータセットであるPlotQA-Dを採用
✔️ PlotQA-Dを用いた実験において、CRCTは既存手法を大きく上回る精度を達成
Classification-Regression for Chart Comprehension
written by Matan Levy, Rami Ben-Ari, Dani Lischinski
(Submitted on 11 Jul 2022)
Comments: ECCV 2022
Subjects: Computation Vision and Pattern Recognition(cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
折れ線グラフやヒストグラムなどから構成されるチャートは現代のコミュニケーションにおいて主要な役割を果たしており、データを理解しやすい視覚的な形にまとめ、その傾向や異常値を明らかにすることで様々な洞察を得ることが可能になります。
しかし、このように実務上の重要性が非常に高いにも関わらず、データセットやモデル作成の困難さからコンピュータビジョンの分野ではあまり注目されていませんでした。
本稿では、こうした課題を解決するために既存手法を大幅に上回るパフォーマンスを可能にしたモデルであるClasssification-Regression Chart Transformer(CRCT)を提案し、大規模かつ多様なチャートとテキストを含んだデータセットであるPlotQA-Dを用いてその有効性を実証した論文について解説します。
Char question answering(CQA)の背景とPlotQAD
Chart question answering(CQA)とは、入力としてチャートと自然言語による質問文を受け取り、出力として質問文に対する回答文を生成することを目的としたタスクであり、質問に答えたり数値を推測したりするためにチャートとテキストの関係を分析する必要があるため、自然画像に対する分類とは根本的に異なる性質があります。
CQAに関するいくつかの先行研究では新しいデータセットを提案していましたが、Methaniらは2020年に発表した論文でこれらのデータセットはチャートの種類と多様性においてすでに飽和していると指摘し、こうした問題点を解消すべく大規模かつ多様なチャートとテキストを含んだデータセットであるPlotQA-Dを作成しました。
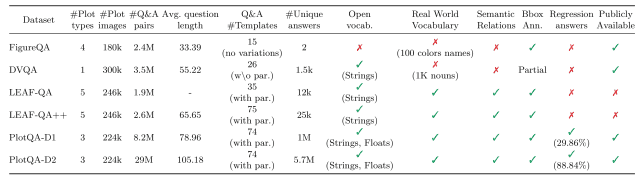
下図に示すように、PlotQA-Dは既存のデータセットと比較してチャート数、テキスト数ともに最大規模であることが分かります。(PlotQA-D1が初期バージョン、PlotQA-D2がサブセットを含む拡張バージョン)
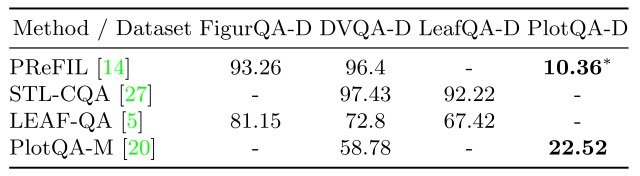
加えて、下図のPlotQA-Dを含めた複数のデータセットを用いた既存モデルでのCQAタスクの精度比較を見ると、太字で示されているようにPlotQA-Dにおける精度だけが大きく低下しており、こうした大規模データセットには既存モデルでは対処できない事が指摘されてきました。
Classification-Regression Chart Transformer(CRCT)
本論文では、上記の課題を解決しPlotQA-Dにおけるstate-of-the-artを達成するために、Classification-Regression Chart Transformer(CRCT)と呼ばれるTransformerベースの新しいモデルを作成しました。
CRCTのアーキテクチャの概要を下図に示します。
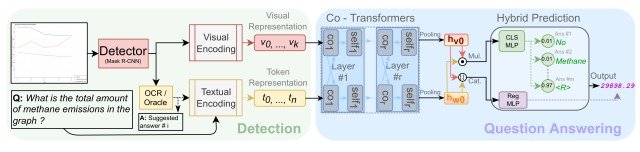
CRCTはDetectionとQuestion Answeringの2つのステージで構成されており、Detection(図の左側)では入力画像のチャート&テキスト部分に対してVisual EncodingとTextual Encodingを行うことで視覚的特徴であるVisual RepresentationとToken Representationを生成し、Question Answering(図の右側)に渡します。
その後、Question AnsweringではCo-Transformersによって、視覚情報とテキスト情報の両方が2つの単一特徴ベクトルであるhv0, hw0に変換され、2つの異なるMLPを含む予測ヘッドによって分類スコアと回帰結果が出力されます。
本モデルが既存モデルと異なる点は大きく分けて以下の4つです。
- 質問文のみをエンコードする既存モデルとは対照的に、本モデルはチャート内の全てのテキスト要素を共同で処理している
- 一般的な「文字列マッチング」をやめ、事前に学習したBERTからなるCo-Transformersを採用することにより、高い一般性を可能にしている
- 異なるドメインからの複数の入力を融合した、新しいチャートの表現学習を採用している
- 既存モデルにはないHybrid Predictionを採用し、分類と回帰を1つのモデルに統合することを可能にしている(分類にはbinary cross entropy lossを、回帰にはL1 lossを使用)
これらの工夫によりCRCTは、全てのタイプの質問に対してエンドツーエンドで学習を行うことを可能にしています。
Evaluation
本論文では、提案モデルであるCRCTに対して評価用ベンチマークとしてPlotQA-Dを使用していくつかの実験を行いました。
既存モデルとの比較
初めに、PlotQA-M(PlatQA-Dを提案した論文で一緒に提案されたモデル)、PReFIL(従来の手法における代表的なモデル)、CRCT-10%(CRCTにおいて10%の学習データを用いて事前学習されたモデル)を用いた比較実験を行いました。
結果を下図に示します。(左が通常のPlotQA-Dを、右が通常のPlotQA-Dの3分の1のサイズを用いた検証結果)
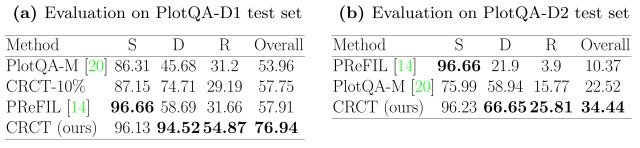
表において、SはStructural(チャートの構造について問う質問)、DはData Retrieval(チャートから答えとなるデータを検索する質問)、RはReasoning(チャート全体から問題文の答えを推論する質問)、Overallはランダムに出題された全てのタイプの質問の精度の平均を指しており、本実験から提案モデルは既存モデルと比較して非常に高い精度を達成している事が分かります。
attentionの可視化
次に、下図に示すようにcaptumを用いてCRCTのattentionの可視化を行いました。
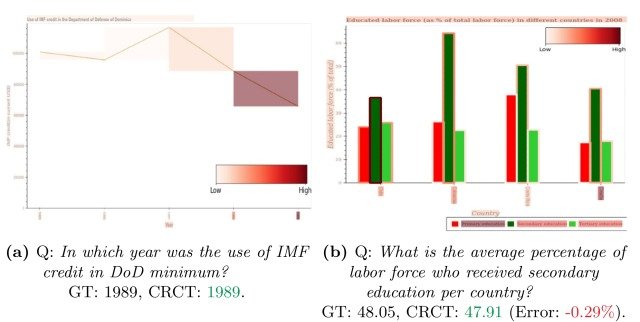
ネットワークが与えられた質問に答えるための根拠があると判断した部分をカラーコード化しており、上図よりCRCTは、(a)の折れ線グラフにおいて最小値について質問された際にプロットの最小値に対応する部分に、(b)の棒グラフにおいてあるカテゴリ(secondary education)の平均値を問う質問をされた際に、対応するカテゴリの棒グラフにそれぞれattentionを向けている事が確認できます。
まとめ
いかがだったでしょうか。今回は、既存手法を大幅に上回るパフォーマンスを可能にしたモデルであるClasssification-Regression Chart Transformer(CRCT)を提案し、大規模かつ多様なチャートとテキストを含んだデータセットであるPlotQA-Dを用いてその有効性を実証した論文について解説しました。
本論文の提案モデルは、既存モデルでは対処できなかったPlotQA-Dデータセットにおいて非常に優れた精度を示しており、attentionの可視化により適切にチャートの該当箇所を判別できている事から、CQAタスクにおいて非常に実用的なモデルであることが実証されました。
一方で、訓練データとテストデータでグラフの色が異なっていたり、非線形のグラフを入力に用いると精度低下が見られるなどの課題も残っており、より多くの色や種類のグラフを含むようにするようにデータセットを拡張する事で更なる性能向上の可能性も考えられるため、今後の進展が非常に楽しみです。今回紹介したモデルのアーキテクチャや生成テキストの詳細は本論文に載っていますので、興味がある方は参照してみてください。




この記事に関するカテゴリー

