グラフに関する自由形式の質問にテキストで回答するタスク、OpenCQAが登場!
3つの要点
✔️ グラフに関する自由形式の質問に説明的なテキストで回答する新たなタスクであるOpenCQAを提案
✔️ 自由形式の質問と、それに関する記述式の回答から構成されたOpenCQAのベンチマークデータセットを作成
✔️ ベースラインとして最新のモデルを用いて検証を行い、使用したモデルは流暢で一貫性のある説明文を生成できている一方で、複雑な論理的推論を行うことは困難であることを発見した
OpenCQA: Open-ended Question Answering with Charts
written by Shankar Kantharaj, Xuan Long Do, Rixie Tiffany Ko Leong, Jia Qing Tan, Enamul Hoque, Shafiq Joty
(Submitted on 12 Oct 2022)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
棒グラフや折れ線グラフなどのデータ可視化手法を使用してデータ中の重要な洞察を発見しそれを他者に説明することは、多くのタスクにおいて必要なプロセスですが、多大な労力を必要とし時間がかかるという問題点があります。
Chart Question Answering(CQA)はこうした問題を解決するために考案され、入力としてグラフと自然言語による質問文を受け取り、出力として質問文に対する回答文を生成することを目的としたタスクです。
CQAは近年注目を集めているタスクですが、既存のデータセットは答えが単語やフレーズであるclose ended questions(答えが「はい・いいえ」または「A・B」のように択一で答えられるような問題)のみに焦点を当てたものばかりであるという問題点がありました。
本稿では、この問題点を解決するためにグラフに関する自由形式の質問に説明的なテキストで回答することを目標とする新たなタスクであるOpenCQAを提案し、本タスクに対するベンチマークデータセット・ベースラインの作成および検証を行うことでその有効性を実証した論文について解説します。
Data Collection & Annotation
自由形式の質問とアノテーターが書いた回答文からなるデータセットの作成は、グラフと関連するテキスト記述を持つデータソースがあまり公開されていないなどの理由からこれまで行われてきませんでした。
そこで本論文では、プロのライターが市場調査・世論・社会問題などに対して様々なグラフとその要約を用いて記事を書いているPew Research(pewresearch.org)のグラフを使用することにしました。
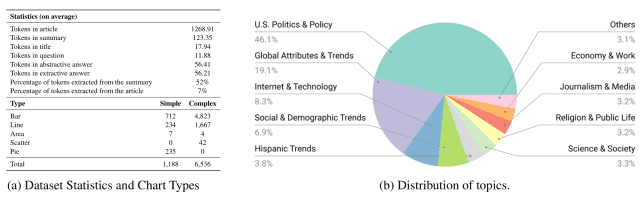
本ウェブサイトの約4000記事からスクレイピングした9285個のグラフ・要約のペアに対して、下図のプロセスのように要約文を新たに追加(図の緑色、紫色、青色、茶色のテキスト)または排除(図の赤色のテキスト)することによって合計7724個のサンプルデータを作成しました。

作成されたデータセットには下図(a)からわかるように、棒グラフ・折れ線グラフ・円グラフなどの様々な種類のグラフが含まれており、下図(b)からわかるように、政治・経済・テクノロジーなど多様なトピックをカバーしています。
OpenCQA task
本論文で提案しているOpenCQAは、グラフに関する質問文が入力された際にその回答となるテキストを出力するタスクであり、具体的には下図に示すように4つの質問タイプがあります。
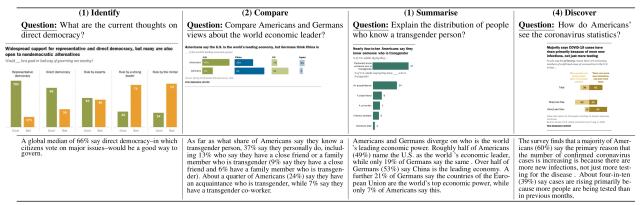
- Identify(特定): 棒グラフのグループの特定のターゲットについての質問
- Compare(比較): グラフ上の2つの特定のターゲットを比較する質問
- Summarize(要約): グラフ上の統計分布を要約するよう求められる質問
- Discover(発見): 特定のタスクは指定されないが、グラフ全体にわたる推察が求められる質問
Baseline Models
本論文では、作成したデータセットのベースラインとして以下の7つの既存モデルを使用しました。
- BERTQA: オリジナルのBERTモデルに対してdirected coattention layersを使用することでパフォーマンスを向上させたモデル
- ELECTRA: 計算効率を重視したself-supervised representation learningを採用したモデル
- GPT-2: Transformerをベースにしたテキスト生成モデルであり、与えられたテキストの単語を元に逐次的に次の単語を予測する
- BART: 標準的なエンコーダ・デコーダtransformerアーキテクチャを用いた、要約などのテキスト生成タスクにおいてstate-of-the-artの性能を達成することが示されているモデル
- T5: 言語処理タスクをtext-to-text形式に変換する統一的なエンコーダ・デコーダtransformerモデル
- VLT5: Vision-Languageタスクをマルチモーダル入力を条件とするテキスト生成として統一した、T5ベースのフレームワーク
- CODR: モデルがドキュメントから提供される情報を使ってテキスト生成を強化する、document grounded generation taskを提案しているモデル
これらのモデルに対して、以下の3つの条件で検証を行いました。
- Setup1: With Article Provided(=グラフと付属する記事の全文が入力として与えられる)
- Setup2: With Summary Provided(=グラフとそれに関連する記事の要約のみが入力として与えられる)
- Setup3: Without Summary Provided(=グラフのみが入力として与えられる)
各条件での入力とグラフに関する質問が与えられた後、ベースラインモデルが質問の回答を生成します。
Evaluation
本論文では、評価指標による自動評価と人間による回答の品質評価の2つの検証が行われました。
Automatic Evaluation
自動評価には、BLEU・ROUGE・CIDEr・BLEURT・Content Selection(CS)・BERT Scoreの6つの評価指標を用いて作成したデータセットに対して検証が行われました。
Setup1〜3の条件での検証結果を下図に示します。
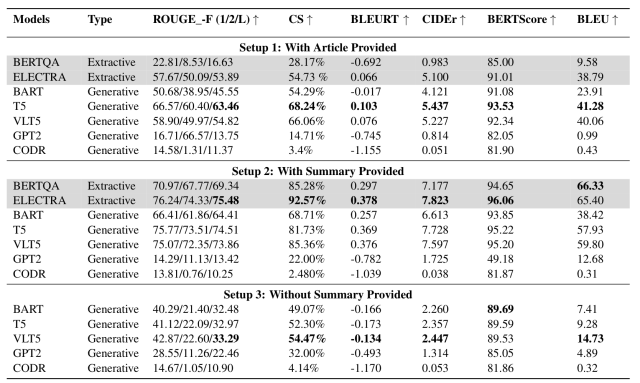
この表より、以下のことが分かりました。
- 記事の全文が与えられた場合(Setup 1)に比較して関連する要約のみが与えられた場合(Setup 2)の方が、有意に性能が向上している
- 加えて、グラフのみが与えられた場合(Setup 3)と比較して要約が与えられた場合(Setup 2)の方が、優位に性能が向上している
- これは要約が与えられない場合、モデルは質問に対する回答を生成するためのテキスト参照を持たないためだと考えられる
- 要約が与えられない場合、VLT5はほとんどの指標で最も良い結果を達成している
- これは、VLT5がグラフ画像とテキストの両方の特徴を用いて回答を生成するためだと考えられる
これらの結果からほとんどのモデルにおいて、「グラフ+関連する要約」を与えられた場合が最も良い性能を達成することが分かりました。
Human Evaluation
モデルによって生成された回答の品質をさらに評価するために、OpenCQAデータセットからランダムに抽出した150のグラフに対して、英語を母国語とする3人のアノテーターによる比較検証を行いました。
自動評価で最も性能の良いモデルであったVLT5を比較モデルとし、要約文あり、要約文なしをそれぞれVLT5-S、VLT5と表記しています。
アノテーターは既存研究で採用している3つの基準に基づいてモデルが生成した回答を評価しました。
- Factual correctness: 生成されたテキストがグラフによって読み取れる情報をどの程度含んでいるか
- Relevance: どれだけ質問と関連したテキストが生成できているか
- Fluency: 生成されたテキストに、書式や大文字小文字の誤りがどれだけ含まれているか
これらの3つの基準に基づいて、アノテーターは1(最も悪い)〜5(最も良い)までの5段階の評価を行いました。
結果は下図のようになりました。(正解文をGoldと表記しています)
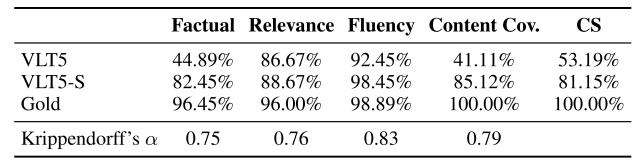
表より、各指標においてVLT5-S(要約文あり)はVLT5(要約文なし)よりも高い評価を得ていることがわかります。
一方VLT5モデルは、RelevanceとFluencyでは高い評価を得ていますが、FactualとCSについては改善の余地があるという結果となりました。(下図赤文字が誤答した部分)
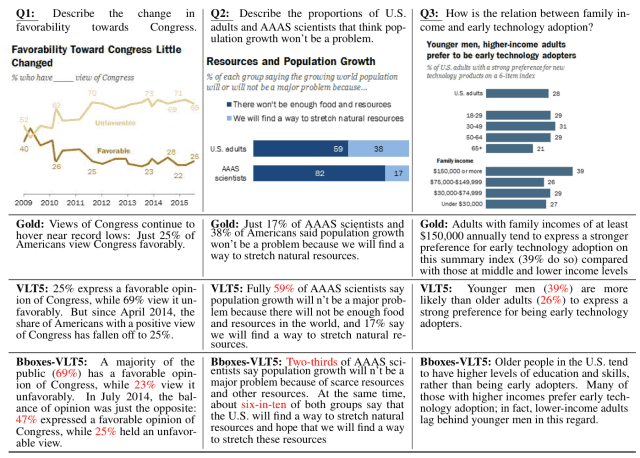
このように、グラフのみを入力とした時に生成文の正確性が著しく低下するという問題点の改善が今後の課題となると考えられます。
まとめ
いかがだったでしょうか。今回は、グラフに関する自由形式の質問に説明的なテキストで回答する新たなタスクであるOpenCQAを提案し、このタスクのための大規模データセットとベースラインの作成を行った論文について解説しました。
筆者は、既存の評価指標では本ベースラインは優れた結果を達成しましたが、より人間らしい回答を生成するというタスクの性質から、人間の判断と相関するより優れた評価指標を構築する研究を進める必要があると述べているため、今後の進展が非常に楽しみです。
今回紹介したデータセットやベースラインモデルのアーキテクチャの詳細は本論文に載っていますので、興味がある方は参照してみてください。



この記事に関するカテゴリー