
グラフContrastiveクラスタリング
3つの要点
✔️ 同一クラスタ内のサンプルとオーグメンテーション結果が類似した表現量を持つように学習する、新しいグラフContrastiveフレームワークを開発した。
✔️ 上記フレームワークをクラスタリングに適用し、識別性能の高い特徴量を学習するモジュールと、よりコンパクトなクラスタ割り当てを行うモジュールを導入した。
✔️ 画像クラスタリング実験を様々なデータセットで行い、既存のモデルよりも大幅に高い精度を記録した。
Graph Contrastive Clustering
written by Huasong Zhong, Jianlong Wu, Chong Chen, Jianqiang Huang, Minghua Deng, Liqiang Nie, Zhouchen Lin, Xian-Sheng Hua
(Submitted on 3 Apr 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
近年、表現量とクラスタリング割り当てを同時に行うcontrastive learningが提案されています。しかし、従来の手法ではカテゴリ情報を考慮していないため、クラスタリングが制限されている可能性があります。そこで、本論文では新しいグラフcontrastiveフレームワークを開発し、クラスタリングに適用するグラフContrastiveクラスタリング(GCC)を提案しました。
手法
$K$種類のカテゴリーに属する$N$枚のラベルなし画像${\bf I}=\{I_1,I_2,\cdots,I_N\}$が与えられた時、クラスタリングはこれらを$K$種類のクラスタに分類することを目的とします。特徴量を得るためにCNNモデル$\Phi(\theta)$を学習し、$I_i$を写像して得られる$(z_i,p_i)$をそれぞれ$d$次元の特徴量表現($||z_i||_2=1$)、$K$次元のクラスタ割り当て確率分布($\sum_{j=1}^Kp_{ij}=1$)とします。$i$番目のサンプルの予測ラベルは次のように求められます。
$$l_i = {\rm arg max}_j(p_{ij}), \ 1\le j \le K$$
グラフContrastive(GC)
$G=(V,E)$をバーテックス$V=\{v_1,\cdots,v_N\}$とエッジ$E$を持つ無向グラフとし、隣接行列$A$を次のように定義します。
$$A_{ij}=\begin{cases}1, & {\rm if}(v_i, v_j)\in E \\0, & {\rm otherwise} \end{cases}$$
$d_i$を$v_i$の次数とし、行列$D$を
$$d_{ij}=\begin{cases}d_i, & (i=j) \\0, & (i\neq j) \end{cases}$$
を$ij$成分に持つ行列とすると、規格化された対称グラフラプラシアンは次のように定義されます。
$$L=I-D^{-\frac{1}{2}}AD^{-\frac{1}{2}},\ L_{ij}=-\frac{A_{ij}}{\sqrt{d_id_j}}(i\neq j)$$
規格化された$N$個の特徴量表現${\bf x}=\{x_1,\cdots, x_N\}$が与えられた時、GCは$A_{ij}>0$ならば$x_i$と$x_j$が近く、$A_{ij}=0$ならば$x_i$と$x_j$が遠くなるようにします。グラフが複数のコミュニティに分けられるとすると、同じコミュニティの特徴量表現の類似度は、異なるコミュニティよりも大きくなります。内部コミュニティの類似度$S_{intra}$、外部コミュニティの類似度$S_{inter}$をそれぞれ次のように定義します。
$$S_{intra}=\sum_{L_{ij}<0}-L_{ij}S(x_i,x_j)$$
$$S_{inter}=\sum_{L_{ij}=0}S(x_i,x_j)$$
ただし$S(x_i,x_j)$は類似度で、本論文ではガウシアンカーネルを用いました。
$$S(x_i,x_j)=e^{-||x_i-x_j||_2^2/\tau}\sim e^{x_i\cdot x_j/\tau}$$
従ってGCのlossは
$${\cal L}_{GC}=-\frac{1}{N}\sum_{i=1}^N\log(\frac{S_{intra}}{S_{inter}})$$
となります。
GCC
GCCフレームワークの概略は下図のようになります。
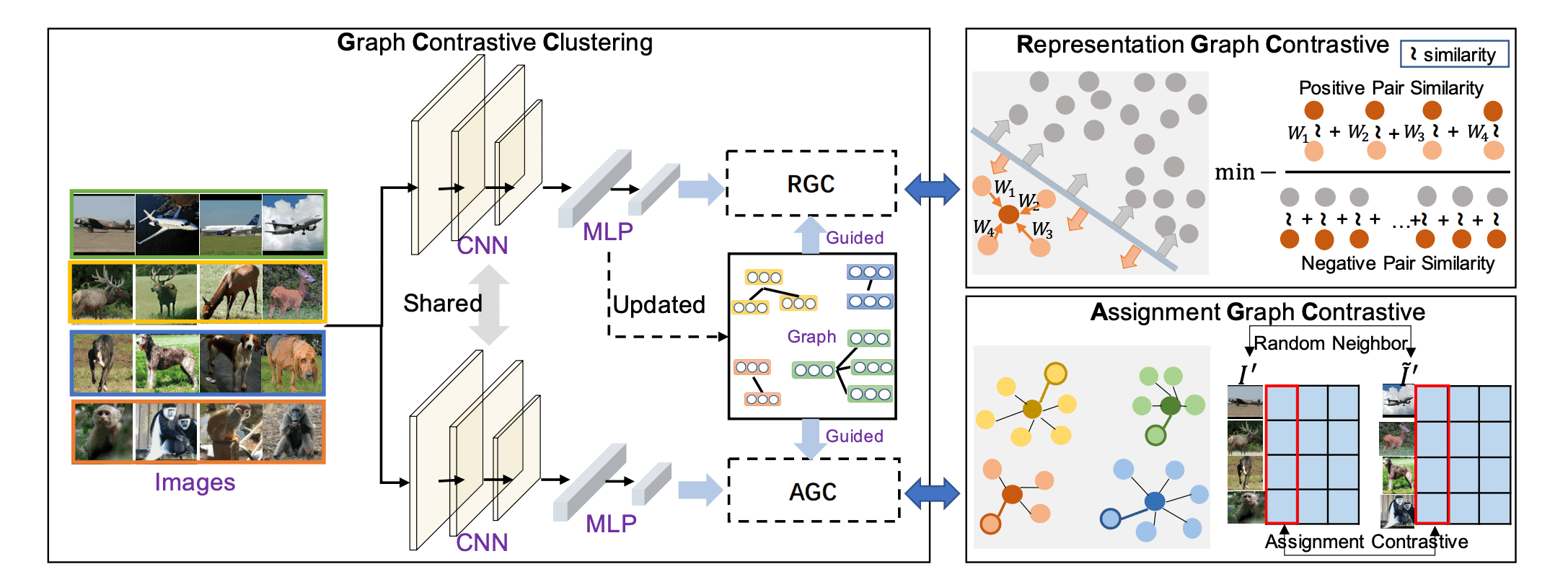
CNNを共有する2つのヘッドからなり、特徴量を学習するRepresentation Graph Contrastive(RGC)モジュールとクラスタ割り当てを学習するAssignment Graph Contrastive(AGC)モジュールからなります。
RGC
${\bf I}'=\{I_1',\cdots,I_N'\}$を元画像をランダムに変換した画像、それらの特徴量を$z'=(z_1',\cdots,z_N')$とすると、RGCのlossは上述の議論より次のように書けます。
$$L_{RGC}^{(t)}=-\frac{1}{N}\sum_{i=1}^N\log\left(\frac{\sum_{L_{ij}^{(t)}<0}-L_{ij}^{(t)}e^{z_i'\cdot z_j'/\tau}}{\sum_{L_{ij}=0}e^{z_i'\cdot z_j'/\tau}}\right)$$
AGC
${\bf {\tilde I}}'=\{{\tilde I}_1',\cdots, {\tilde I}_N'\}$を、${\tilde I}_j'$が$A^{(t)}$に基づいて$I_i$のランダムな近傍サンプルのランダムに変換した画像であるようなベクトルとすると、それぞれの確率ベクトルは
$${\bf q}'=[q_1',\cdots, q_K']_{N\times K}$$
$${\tilde {\bf q}}'=[{\tilde q}_1',\cdots,{\tilde q}_K']_{N\times K}$$
と表せます。ここで$q_i'$と${\tilde q}_i'$はそれぞれ${\bf I}'$と${\tilde {\bf I}}'$のどのサンプルがクラスタ$i$に属するかを表す確率ベクトルです。AGCのlossは次のように書けます。
$${\cal L}_{AGC}=-\frac{1}{K}\sum_{i=1}^K\log\left(\frac{e^{q_i'\cdot q_i'/\tau}}{\sum_{j=1}^Ke^{q_i'\cdot q_j'/\tau}}\right)$$
Loss関数
また、局所的最適解にならないように、以下の正則化lossを加えます。
$${\cal L}_{CR}=\log(K)-H(\cal Z)$$
ただし$H$はエントロピー、${\cal Z}_i=\frac{\sum_{j=1}^Nq_{ij}}{\sum_{i=1}^K\sum_{j=1}^Nq_{ij}}$です。最終的なloss関数は
$${\cal L}={\cal L}_{RGC}+\lambda{\cal L}_{AGC}+\eta{\cal L}_{CR}$$
となります。ここで$\lambda, \eta$はハイパパラメタです。
結果
6種類のベンチマークデータセットに対して、従来の手法と性能を比較しました。結果は下表のようになりました。
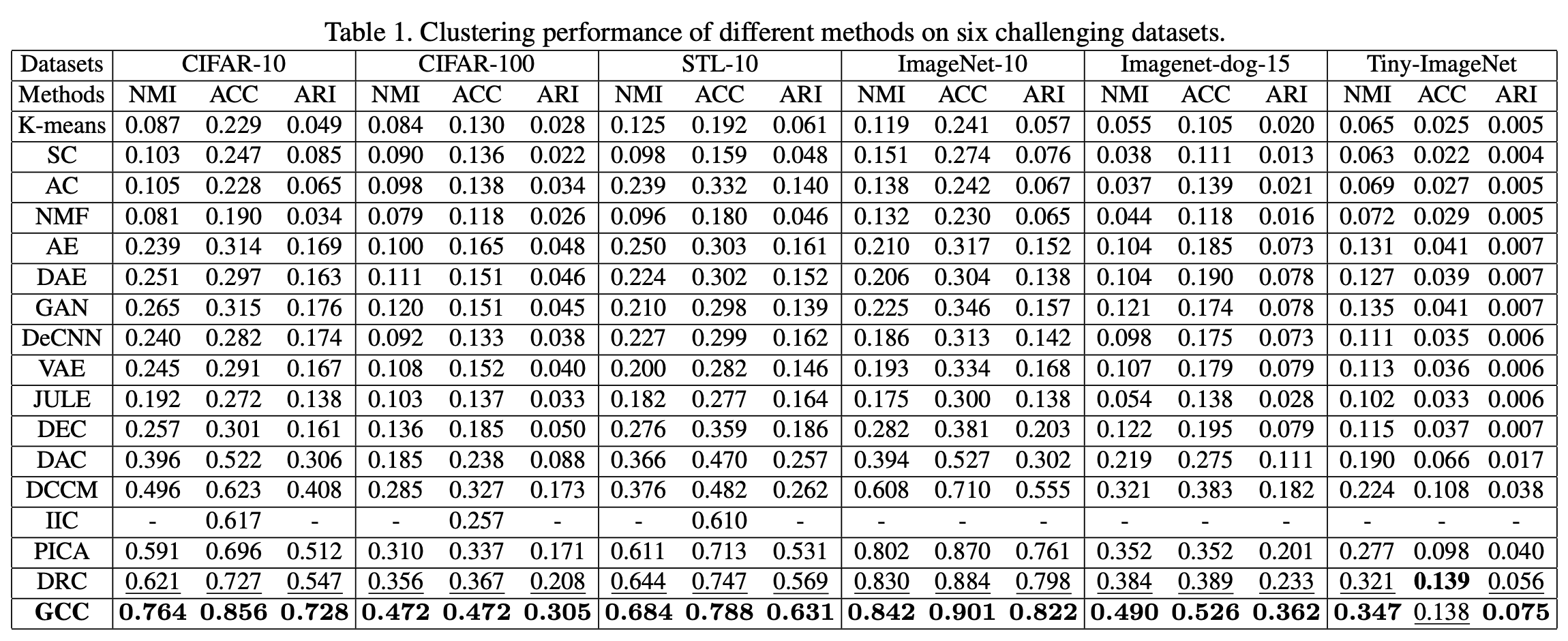
表から、本論文の手法は3つの評価指標で、全てのデータセットに対して従来のSOTAモデルを大幅に改善する結果となっており、有効性を示しています。また、GCCが成功したサンプル、失敗したサンプルの例を下図に示します。

図から、成功したサンプル(左)は異なる背景や角度のものも含まれており、頑健性を示しています。一方で失敗したサンプル(中央、右)は形状の似た他クラスや、異なるパターンのものと写っているものなどであり、教師なし学習でこれらを分離するのは難しく、課題となっています。
まとめ
本論文では、新しいグラフContrastive learningを用いたクラスタリング手法を提案しました。従来と異なり、サンプルと同じクラスタに属する他のサンプルのオーグメンテーションの類似度を近づけることによって、効率よく学習しました。その結果、6つのベンチマークにおいて従来のSOTAを大幅に更新しました。






この記事に関するカテゴリー






