
教師なし双曲線距離学習
3つの要点
✔️ データの階層構造を従来より良く抽出できる、教師なし双曲線距離学習を提案した。
✔️ 階層類似度を二分するのではなく、より細かく類似度を考慮する新たなloss関数を導入した。
✔️ 本論文で提案したモデルはクラスタリングの3つのベンチマークにおいてSOTAを記録した。
Unsupervised Hyperbolic Metric Learning
written by Jiexi Yan, Lei Luo, Cheng Deng, Heng Huang
Comments: CVPR
Subjects: Computer Vision and Pattern Recognition (cs.CV)
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
類似度の距離を学習する距離学習は、コンピュータビジョンのさまざまな分野において重要であり、研究されてきました。特に、ディープラーニングを用いた深層距離学習では、正のサンプルをアンカーに近く、負のサンプルをアンカーに遠く配置するよう特徴量を学習します。しかしながら、現実世界では大量のラベルデータを入手することは困難なため、データの内在的な構造を教師なしで学習する手法が注目されています。従来の手法ではデータを正と負に二分していましたが、現実世界では同じ負のサンプルでもアンカーに近いものと遠いものがあるので、より階層的なクラス分けをした方が特徴量を学習することができます。また、ユークリッド空間で特徴量を得るのは、必ずしもデータの構造を捉えられないということが示唆されています。そこで本論文では、ラベルなしデータから内在情報を抽出する、教師なし双曲線距離学習を提案しました。まず、データを通常のユークリッド空間から双曲線空間へ組み込みます。そして、擬似ラベルを得るために階層クラスタリングをします。さらに、階層類似度を考慮した新たなloss関数を導入しました。
手法
モデルの概略は下図のようになります。データセット${\cal D}=\{{\bf x}_1,{\bf x}_2,\cdots{\bf x}_n\}$が与えられたとき、双曲線距離学習モジュールにおいて双曲線距離空間における特徴量${\cal Z}=\{{\bf z}_i=f({\bf x}_i|\theta)\}_{i=1}^n$を得ます。その後、階層クラスタリングモジュールでクラスタリングします。クラスタリング結果${\cal H}$から類似度${\cal S}=\{s_{ij}\}_{i,j=1}^n$を計算します。${\cal S}$を教師データとすることで、双曲線距離学習モジュールをファインチューニングします。
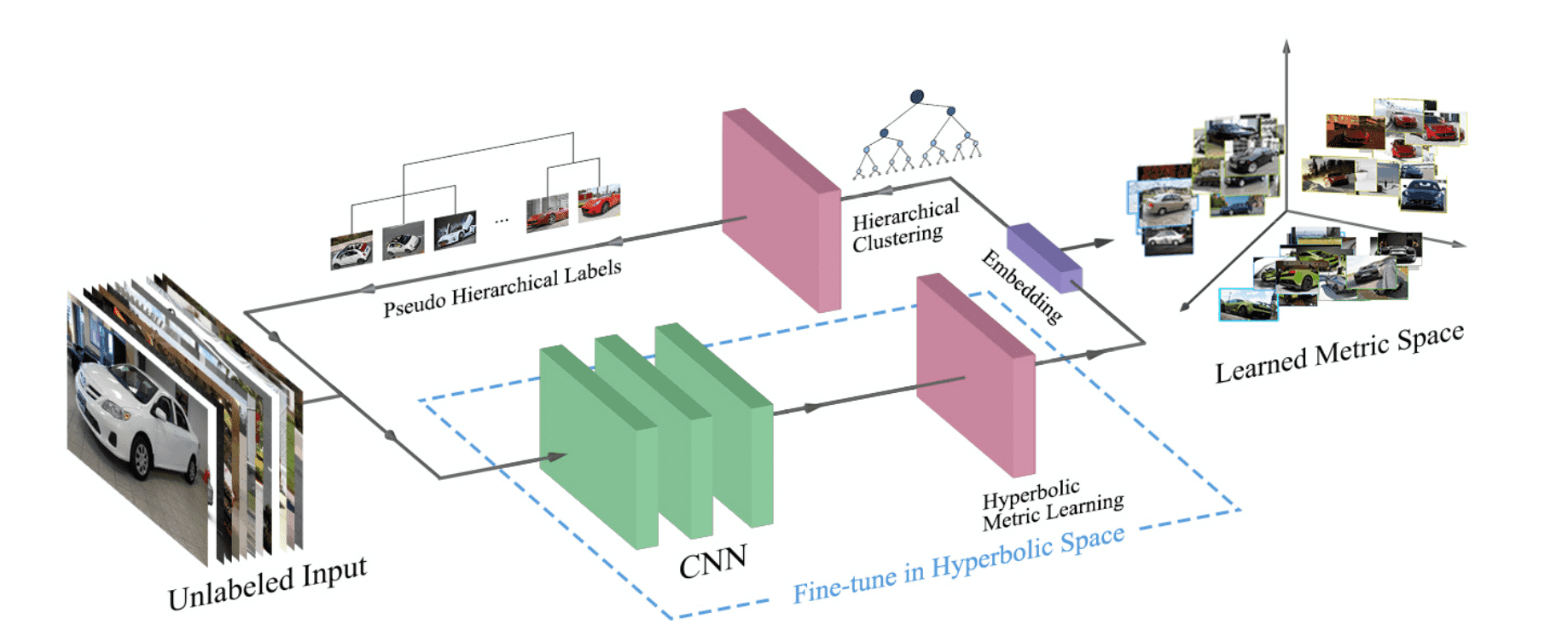
双曲線距離学習
本論文では階層構造を捉えるために、双曲線幾何学を導入します。特に、特定の軽量テンソルを持つリーマン多様体に対応する、双曲線空間のポアンカレ球モデルを考慮しました。ポアンカレ球モデルは多様体${\mathbb D}_\tau^d=\{{\bf x}\in {\mathbb R}^d: \tau||{|\bf x}||<1,\tau\geq0\}$によって定義されます。ここで$\tau$はポアンカレ球の曲率です。このモデルでは、二点${\bf z}_i,{\bf z}_j\in {\mathbb D}_\tau^d$間の距離は
$$d_{\mathbb D}({\bf z}_i, {\bf z}_j)={\rm cosh}^{-1}\left(1+2\frac{||{\bf z}_i-{\bf z}_j||^2}{(1-||{\bf z}_i||^2)(1-||{\bf z}_j||^2)}\right)$$
となります。そして、双曲線ネットワーク層を最終層に加え、"exp"マッピングによって${\mathbb R}^n$の入力特徴量から${\mathbb D}_\tau^n$の双曲線多様体へ射影します。
$${\bf z}={\rm exp}^\tau({\bf x}):={\rm tanh}({\sqrt \tau}||{\bf x}||)\frac{{\bf x}}{{\sqrt \tau}||{\bf x}||}$$
階層類似度
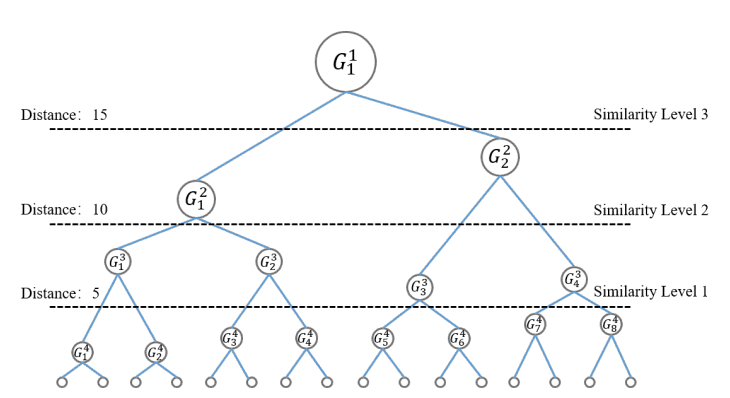
より良い情報量を得るために、下図のように複数のサブクラスターからなるツリー構造を考えます。異なるサブクラスター内のサンプル間距離を
$$d_{ab}=\frac{1}{n_an_b}\sum_{{\bf z}_i^a\in C_a, {\bf z}_j^b\in C_b}||{\bf z}_i^a-{\bf z}_j^b||$$
と定義します。ただし${\bf z}_i^a, {\bf z}_j^b$はサブクラスター$C_a, C_b$のサンプル、$n_a, n_b$は$C_a, C_b$のサンプル数です。$d_{ab}$と閾値$\delta$の大きさに応じて、類似度レベルが計算されます。下図の例では$\delta=\{5,10,15\}$とした時に得られる3つの類似度レベルです。最後に、サンプル${\bf z}_i^a, {\bf z}_j^b$間の類似度として
$$s_{ij}=L_k, \ L_k \in \{1,2,\cdots,K\}$$
を定義しました。
loss関数
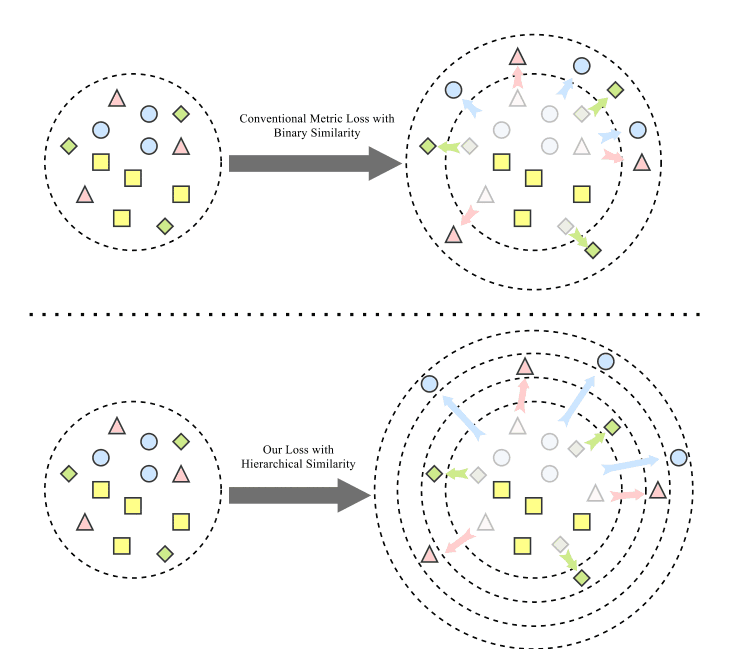
階層類似度の情報を有効利用するために、双曲線空間でのサンプル$\{{\bf z}_i, {\bf z}_j, {\bf z}_l\}\in {\cal S}$が与えられた時に、loss関数を次のように定義します。
$${\cal L}(i,j,l)=\left({\log}\frac{||{\bf z}_i-{\bf z}_j||}{||{\bf z}_i-{\bf z}_l||}-{\log}\Omega^{s_{ij}-s_{il}}\right)^2$$
ただし$\Omega$は階層類似度の寄与を調整するハイパパラメータです。第一項はサンプル間のlog比率で、第二項は対応する階層類似度のlog比率です。これを導入することによって、下図のように負のサンプルを類似度に応じて離すことができます。
結果
従来のモデルと比較するために、パブリックデータセットを用いて教師なし手法で画像検索タスクを行いました。結果は下表のようになりました。ここで、SOP(Stanford Online Products), CARS196, CUB-200-2011はパブリックデータセット、R@Kは階層レベルK毎の再現率です。表から、全てのデータセットで本手法が最も高い性能を示しています。このことから、階層類似度を用いることでより多くの情報量を抽出できていることが分かります。

まとめ
本論文では、教師なし双曲線距離学習を提案しました。まず、階層類似度を考慮し、双曲線空間でクラスタリングしました。さらに、それらを考慮した新しいloss関数を導入しました。本手法は従来のモデルと比べて、複数のベンチマークでSOTAを記録しました。






この記事に関するカテゴリー






