
フローベースモデルと拡散モデルの融合~DiffFlow~
3つの要点
✔️ フローベースモデルと拡散モデルを拡張し、両手法の長所を併せ持つDiffusion Normalizing Flow(DiffFlow)を開発
✔️ DiffFlowではフローベースモデルでの関数の全単射性を緩和することでモデルの表現力を向上し、拡散モデルよりもサンプリング効率を向上
✔️ DiffFlowではフローベースモデルや拡散モデルではモデリングできなかった分布の複雑な細かい特徴も生成
Diffusion Normalizing Flow
written by Qinsheng Zhang, Yongxin Chen
(Submitted on 14 Oct 2021)
Comments: Neurips 2021
Subjects: Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
データ分布を学習して人工的に未知のデータを生成する深層学習モデルのことを深層生成モデルと呼びます。深層生成モデルでは潜在変数$\mathbb{z}$からデータ$\mathbb{x}$を生成するニューラルネットワークを学習します。
中でも潜在変数とデータの次元が等しいものがあり、これらのモデルでは潜在変数からデータを生成する過程を同じ空間内での軌跡として扱うことができます。この軌跡が決定論的に一つに定まる場合にはフローベースモデル、確率的に定まる場合には拡散モデルと呼ばれます。
フローベースモデルは関数を用いて潜在変数に逐次的な変換を加えることでデータを生成します。この関数は可逆でなければならないという制約があるため、モデルの表現力が制限されてしまうという問題点があります。
一方で、拡散モデルはデータにノイズを逐次的に加えて単純な潜在変数に落とし込む拡散過程とノイズを徐々に除去することでデータを復元する逆過程で構成されます。逆過程における高品質なサンプルの生成には拡散過程におけるノイズ付加を十分に遅くする必要があり、モデルの訓練に時間がかかるという欠点があります。また、ノイズをデータ分布とは独立に加えるという性質上、分布内の詳細な特徴を捉えられないといった課題もあります。
本稿で紹介するDiffusion Normalizing Flow(DiffFlow)では上述したフローベースモデルと拡散モデルにおける欠点を踏まえて二つの手法の良いとこどりをした形でデータの生成を行っています。次のセクションからフローベースモデルと拡散モデルの簡単な紹介を行った後、DiffFlowの概要について述べていきます。
フローベースモデル(正規化流)とは
フローベースモデル(正規化流)において前述した空間上の軌跡は以下の微分方程式でモデリングされます。
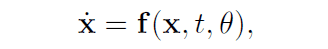
ここで、$\mathbb{x}(0)$は始点であるデータを表しており、$\mathbb{x}(T)$は終点である潜在変数$z$を表しています。$t$は潜在変数へと変換される時刻$T$までの時間ステップを意味します。
ここで、連続的な時間を仮定する場合には以下の関係式が導かれます。
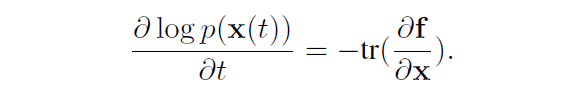
また、離散的な時間を仮定する場合には以下の関係式が導かれます。この場合にはデータから潜在変数へのマッピングが全単射関数の合成関数である$F=F_N \circ F_{N-1} ... F_{2} \circ F_{1}$で表されます。
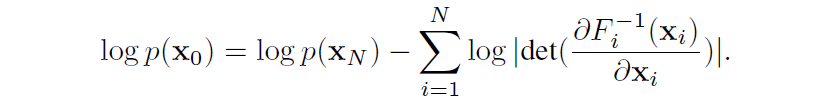
フローベースモデルでは以上の式で表されるようにデータ尤度を直接計算することができる点が特徴です。
拡散モデルとは
拡散モデルにおける空間上の軌跡は確率微分方程式によってモデリングされます。データから潜在変数への拡散過程は以下の関係式で表されます。式中の$\mathbb{f}$はベクトルを出力する関数であり、ドリフト項と呼ばれます。また、$g$はスカラー関数であり、拡散係数と呼ばれます。
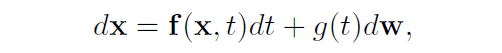
また、潜在変数からデータへの逆過程は以下の関係式で表すことができます。
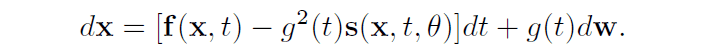
逆過程における関数$\mathbb{s}$が拡散過程における軌跡上の分布$p_F$のスコア関数$\nabla \log(p_F)$と一致し、両過程で潜在変数が同じ分布を共有している条件下においては逆過程の軌跡上の分布$p_B$が$p_F$と一致することが知られています。
拡散モデルではこの$p_F$と$p_B$の分布の違いを最小化するようにニューラルネットワークで近似した$\mathbb{s}$を訓練し、逆過程におけるサンプリングを利用してデータを生成します。この分布の違いを測る指標としてKLダイバージェンスが主に用いられます。
時間が離散的な条件下においては$p_F$と$p_B$はそれぞれ以下のように表すことができます。こちらの方が拡散過程と逆過程のイメージがつかみやすいかもしれません。
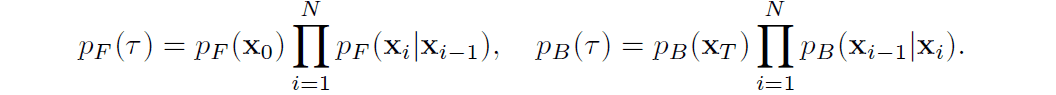
拡散モデルにおいてはデータ尤度を直接的に求めることができないため、対数尤度の下界を計算する形となっています。
DiffFlow
本論文で提案されたDiffusion Normalizing Flow(DiffFlow)では正規化流と拡散モデルの中間に位置するモデルを提案しています。データと潜在変数の双方向の過程を正規化流、拡散モデル及びDiffFlowについて図示すると以下のようになります。
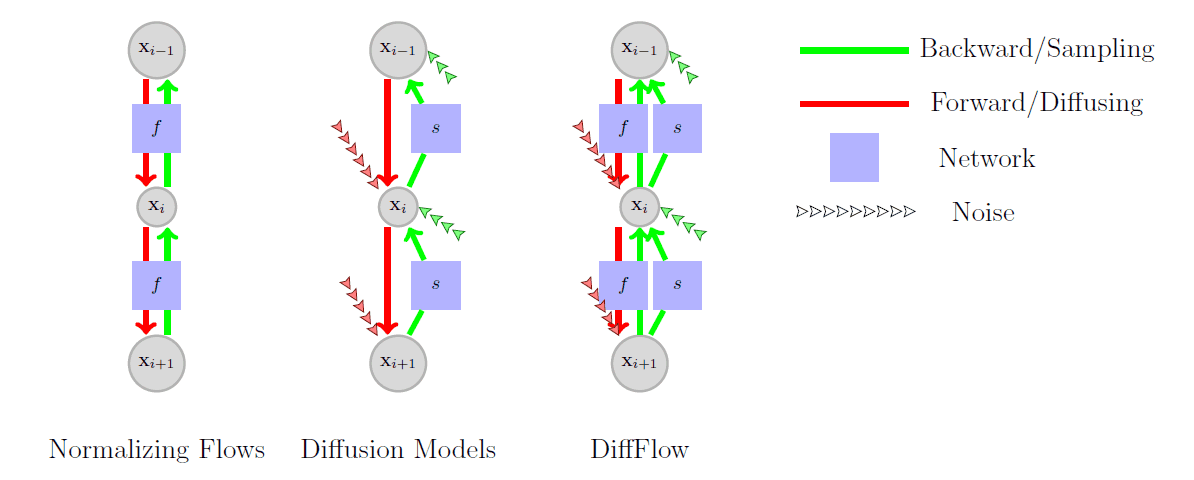
大きな違いとして拡散過程において単純な線形関数としてしか表現されていなかった関数$f$をニューラルネットワークによって近似して学習可能とした点や、正規化流では存在しなかった関数$f$の部分にノイズを導入した点が挙げられます。
フローベースモデルでは可逆関数のみを用いることによりデータが復元される保証はありますが、最終的にガウシアンノイズに到達する保証はありません。一方で、拡散モデルではデータに依存しないノイズを加えるため、データを完全に無視することによりたった1回のステップでガウシアンノイズに到達できます。しかし、これでは逆過程を学習することができないためデータを生成することができません。
DiffFlowではデータから潜在変数へと変換する過程において学習可能な関数$f$を新たに追加することにより、データをサンプリングする逆過程の学習に対して十分な教師信号を与えていると考えられます。
実装においては拡散過程と逆過程として以下のような離散的な時間における関係式(上:拡散過程、下:逆過程)を用います。
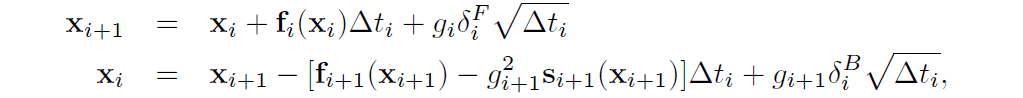
式中の$\delta$は多変量標準正規分布からサンプリングしたノイズを表し、$\Delta t$は離散化された時間ステップを表します。
損失関数は拡散過程における$p_F$及び逆過程における$p_B$の二つの分布に対するKLダイバージェンスから導出されます。DiffFlowではこの損失関数を最小化するように関数$f,s$を訓練します。
DiffFlowでは勾配を計算する際のメモリ消費への対策を講じたり、時間ステップを離散化する際の間隔を変更するなどの工夫を行っています。詳細については元論文を参照してみてください。
DiffFlowの仕組みについて大まかにわかったところで本手法によるデータ生成の結果についてみていきましょう。
人工データにおける拡散過程
まずはじめに人工データにおいて拡散過程を可視化した結果について見てみます。
下の図はDiffFlow(本手法)、DDPM(拡散モデル)、FFJORD(フローベースモデル)においてデータから潜在変数へと変換されていく様子を図示したものです。左右で別のリング状のデータを扱った際の結果が示されています。
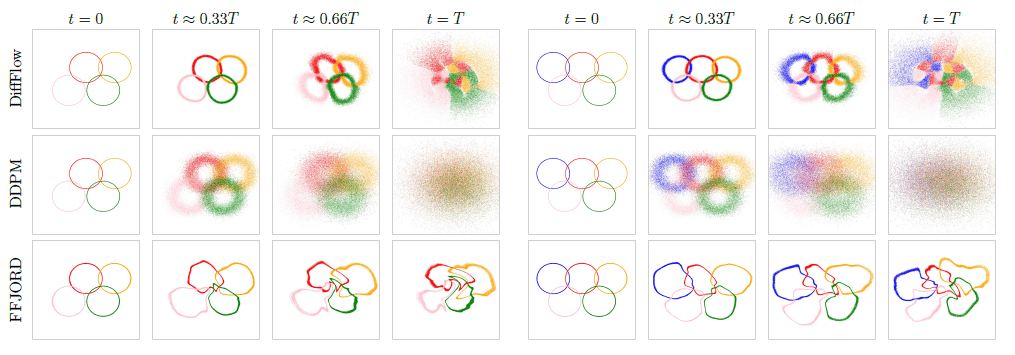
フローベースモデルであるFFJORDでは潜在変数に変換してもリングの形状が残ったままになっており、空間全体に点が散らばるようにはなっていません。一方で、拡散モデルであるDDPMは最終的に空間全体に散らばるような潜在変数が得られているものの、各モード(図中で色分けされたリング)が混在する表現になってしまっています。
DiffFlowではリングの特徴を維持したまま空間全体に広がる潜在変数の分布が獲得されており、フローベースモデルと拡散モデルの良いとこどりであることがわかります。
逆過程における人工データの生成
次に、人工データに関して逆過程を利用して潜在変数から画像をサンプリングした結果を示します。
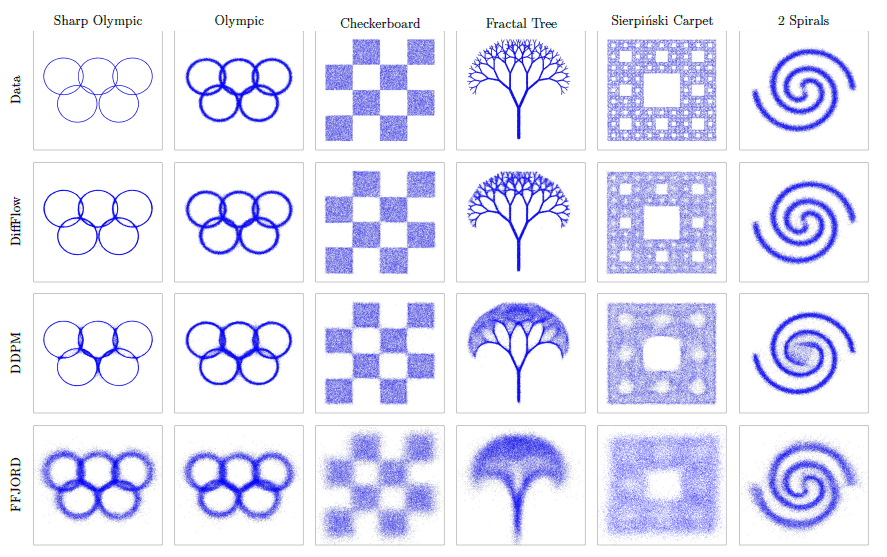
いずれのモデルも元のデータ分布を捉えた生成が行えていますが、分布の細かい形状を捉えられているのはDiffFlowのみとなっています。この結果からDiffFlowはよりシャープな境界を持つような複雑のデータセットにおいても上手くデータの生成を行える可能性が示唆されています。
おわりに
いかがだったでしょうか。DiffFlowではかなり細かいディテールまで再現して生成できていて驚きでした。今は深層生成モデルとしてVAEやGANが馴染みがありますが、これからはフローベースモデルや拡散モデルも注目を浴びてきそうです。
DiffFlowでは論文内で従来の拡散モデルよりも計算時間が遅いことが議論されており、実際に画像などの高次元データの生成に応用するとなるとまだまだ他の生成モデルに劣るように感じます。




この記事に関するカテゴリー






