重みやノードではなく層をDropout!『LayerDrop』の提案
3つの要点
✔️ Transformerはパラメータ数が多く、膨大な計算量を必要とする
✔️ モデル圧縮として新たに層のDropoutを行うLayerDropを提案
✔️ 元の性能をそのままに様々な層数のモデルを抽出
Reducing Transformer Depth on Demand with Structured Dropout
written by Angela Fan, Edouard Grave, Armand Joulin
(Submitted on 25 Sep 2019)
Comments: Accepted to ICLR2020.
Subjects: Machine Learning (cs.LG); Computation and Language (cs.CL); Machine Learning (stat.ML)
code:
はじめに
Transformerは機械翻訳などの自然言語処理における重要なアーキテクチャとなっています。Transformerの各層には数百万のパラメータが含まれているため学習・推論双方において莫大な計算量を要します。
Transformerのような大きなモデルの性能をそのままに、より小さい(計算量の少ない)モデルを抽出することをモデル圧縮といいます。モデル圧縮には主に2つの手法があります。1つ目はDistillation(蒸留)です。Distillationは元のモデルの出力を教師データとしてより小さいモデルに学習させる手法です。2つ目はPruning(枝刈り)です。Pruningはモデルのノードや重みを削除することでパラメータ数を削減する手法です。本論文ではPruningに注目しています。
本論文のアプローチは、一定確率でノードを無視するDropoutと一定確率でノード間の重みを無視するDropconnectの派生形である層全体を無視するLayerDropをTransformerへ適用します。LayerDropの利点は以下の3つが挙げられます:
- 非常にDeepなTransformerを正規化し、学習を安定化することで他のベンチマークよりも良いパフォーマンスを実現
- テスト時に小さいモデルを抽出することができ、調整の必要がない
- LayerDropはDropoutと同様に実装が簡単
手法
Layerの選択
Pruningの対象となるLayerの選択方法を複数用意します。
・Every Other
最も単純な方法として一定確率$p$でPruningを行う手法が挙げられます。$p$でPruningを行うということは$d\equiv 0(mod\frac{1}{p})$においてLayerを削除することを意味します。この手法が最も直感的であり、バランスの取れたモデルを実現することができます。
・Search on Valid
本手法は検証セットを用いて抽出するモデルを決定するために様々なLayerの組み合わせの計算を行い、最も高性能なモデルを決定します。この手法の発想は単純なものですが、こういった手法は計算量が多く、推論時に過学習を起こす可能性があります。
・Data Driven Pruning
最後は各LayerのDrop率を学習する手法です。Drop率$p_d$をそのLayerのパラメータとしてソフトマックス関数を適用させ、推論時にはソフトマックス関数の出力に基づいて固定されたtop-kの層のみを採用します。
実際には、Every Otherが様々なタスクにおいて機能することがわかりました。他の2手法はあまり良い結果が得られませんでした。ここで、実験においてはPruningを行った後のモデルの調整を行っていないことに注意が必要です。
Drop率の設定
元のモデルが$N$個のグループを持ち、固定のDrop率$p$と仮定すると学習において用いられるグループ数の平均は$N(1-p)$個となります。よってPruning後のグループ数を$r$とすると最適なDrop率$p^*$は$$p^*=1-\frac{r}{N}$$となります。
より小さいモデルにおいてよりDrop率が高い方が良い性能を発揮することがわかりました。本論文における実験では$p=0.2$としていますが、推論時間が小さいモデルを対象とする場合には$p=0.5$を推奨しています。
実験①
実験設定
様々な自然言語処理のタスクにおいて提案手法の有効性を説明します。
- 機械翻訳
- WMT英独翻訳タスク
- データセット:WMT16
- Dropout:{0.1,0.2,0.5}
- LayerDrop率:$p=0.2$
- 評価指標:BLEU
- 言語モデリング
- データセット:Wikitext-103
- Dropout及びLayerDrop率は機械翻訳と同じ
- 評価指標:PPL
- 要約
- データセット:280K以上のニュース記事
- Dropout及びLayerDrop率は機械翻訳と同じ
- 評価指標:ROUGE
- 質疑応答
- データセット:ELI5
- 272Kの質問と回答のペア
- 評価指標:ROUGE
- データセット:ELI5
- 事前学習による文章表現
- データセット:Bookscorpus+Wiki,Bookscorpus+CC-News+Stories
- 評価指標:MRPC,QNLI,MNLI
結果①
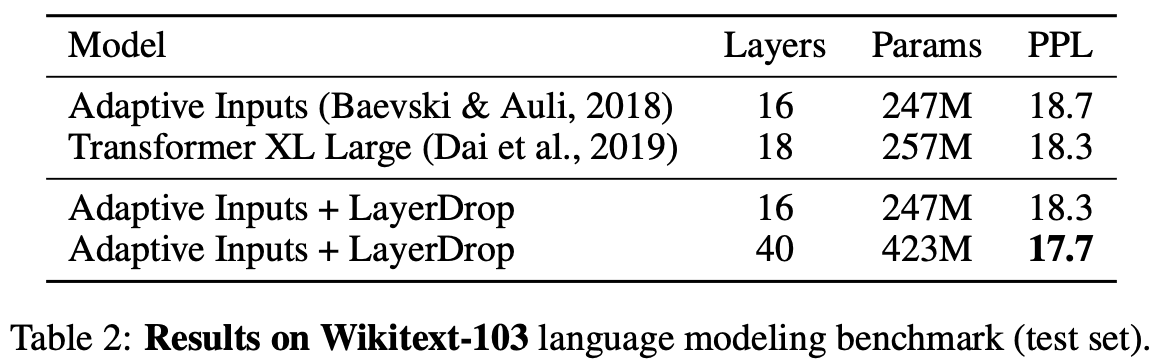
Table 2は言語モデリングの実験結果です。Adaptive Inputsにて学習されたTransformerに対するLayerDropの影響を示しています。16層のTransformerにLayerDropを追加することでPPLは0.4改善され、Transformer XLの最先端の結果と一致します。40層のTransformerに追加することでさらに0.6改善されています。
非常にDeepなTransformerは学習が不安定であり、メモリの使用量が多いため学習が難しく、Wikitext-103のような小さなデータセットでは過学習を起こしやすいです。 LayerDropはネットワークを正規化し、メモリの使用量を減らすことで学習の安定性が増します。
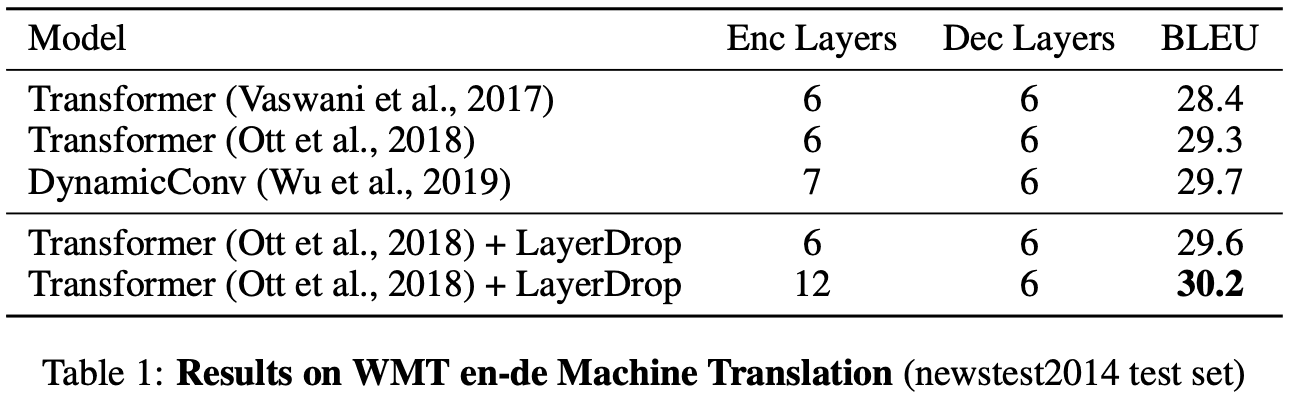
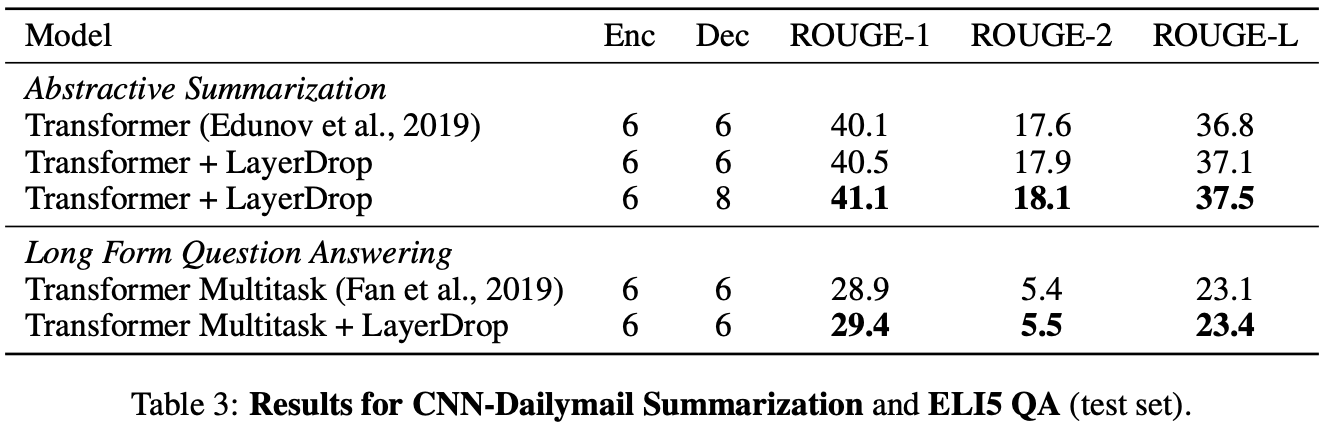
Table 1及びTable 3はSequence to sequenceタスクの結果です。機械翻訳、要約、質疑応答タスクのモデルにLayerDropを適用すると全てのタスクで性能が向上することが読み取れます。

Table 4は事前訓練に関する結果です。同様にLayerDropは性能を向上させていることがわかります。
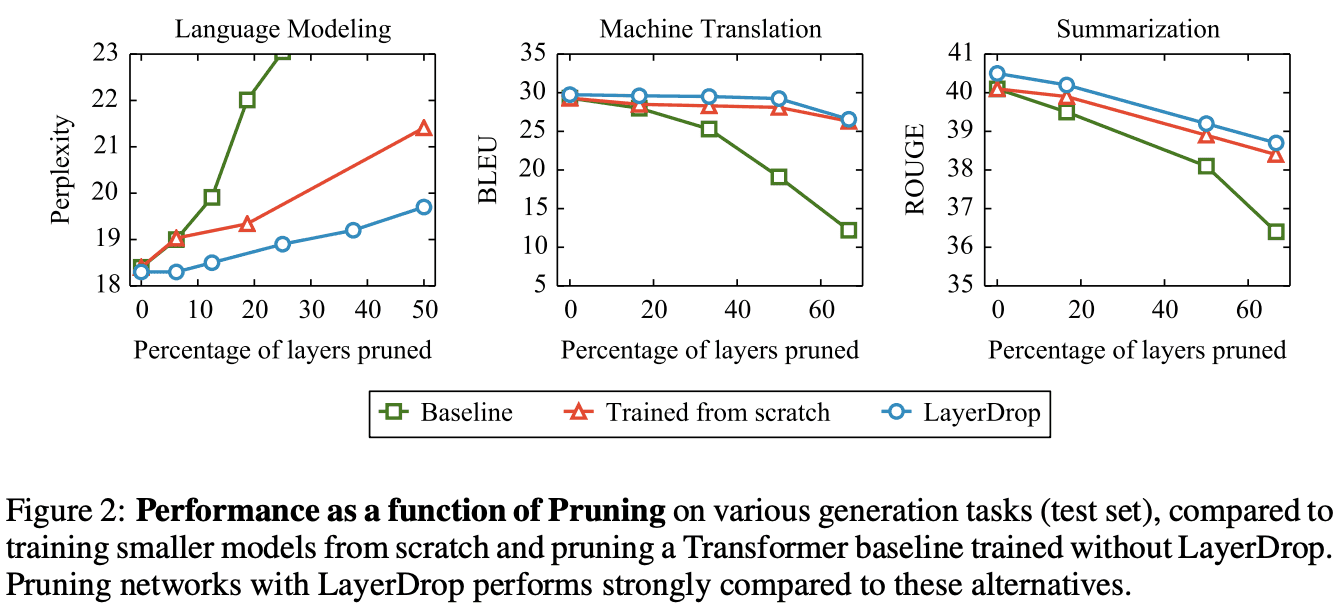
Figure 2は言語モデリング、機械翻訳及び要約のためのTransformerに関して横軸がPruningされる層の数、縦軸が性能となっています。LayerDropを適用して学習したモデルから希望の層を抽出することを示しています。一方、LayerDropを用いないBaselineから層をDropすると著しく性能が悪化することも見て取れます。
実験②
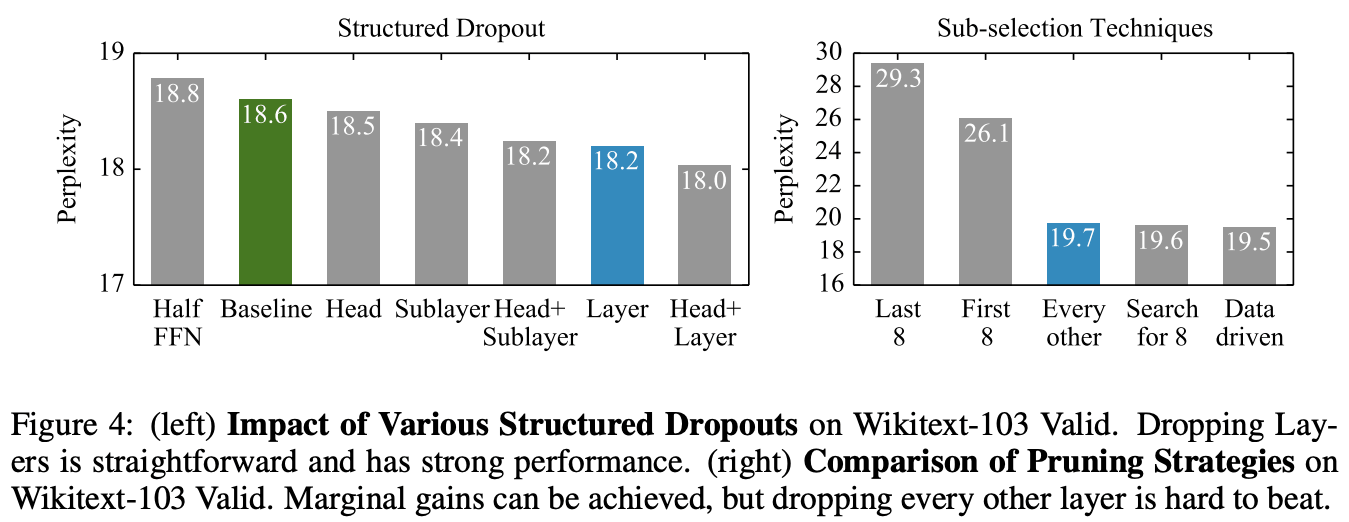
Figure4の左はDropoutする対象を比較したものです。attention head、FFN行列、Transformer全体やそれぞれを組み合わせた結果を比較しています。
Figure4の右は推論時のモデル層の選択に関するアプローチを比較したものです。この論文では"Every other"という単純な手法ですが、とても良い性能となっています。最適な8層を学習によって探索する手法でも提案手法と比較してわずかしか改善されていません。対照的に、入力層から8層や出力層から8層をDropすると性能が著しく低下することが読み取れます。これは直感的にですが、入力を処理していたり予測を処理している箇所をまとまってDropすると性能が低下することは理解できます。
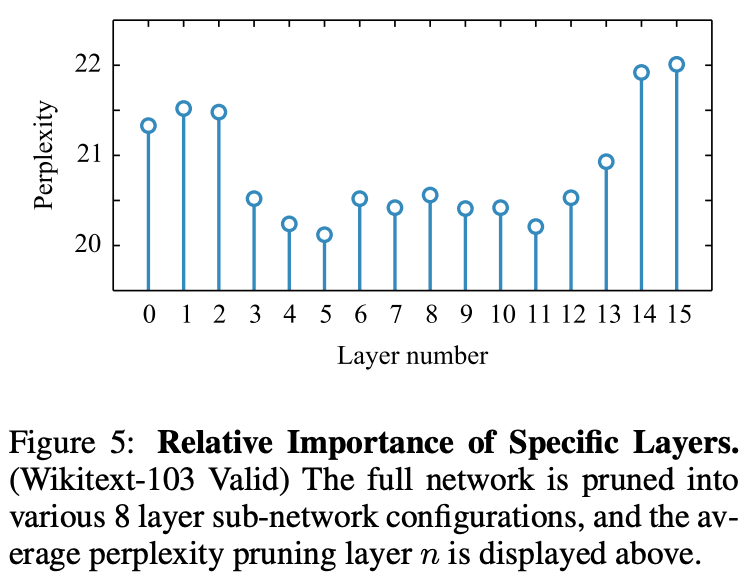 Figure5はどの層を削除するかの実験結果です。図からわかるように、入力層付近や出力層付近は重要な層(Dropしない方が良い)層となっています。
Figure5はどの層を削除するかの実験結果です。図からわかるように、入力層付近や出力層付近は重要な層(Dropしない方が良い)層となっています。
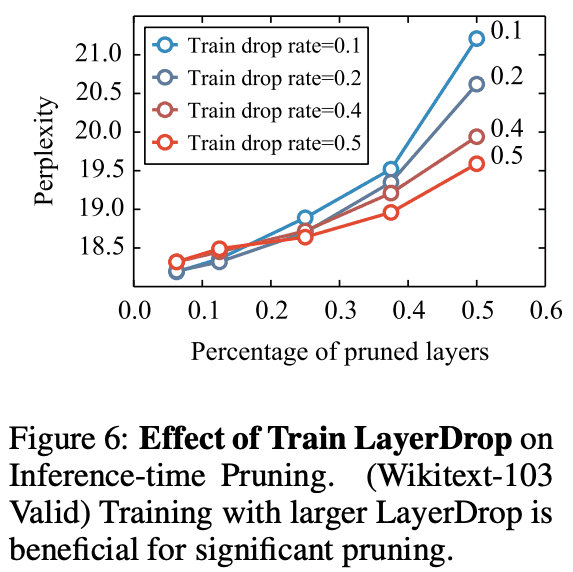 Figure6はDrop rateと性能の比較となっています。よりDeepなモデルではより高いDrop rateが望まれることがわかります。
Figure6はDrop rateと性能の比較となっています。よりDeepなモデルではより高いDrop rateが望まれることがわかります。
まとめ
Dropoutはニューラルネットワークを正規化し、ロバストになるようにします。本論文では特にLayerに着目したLayerDropを提案しました。様々なテキスト生成や機械翻訳タスクにおいて、非常にDeepなモデルの学習を可能にし、安定させることと同時に様々な深さのモデルを良い性能で抽出が可能であることを示しました。





この記事に関するカテゴリー
