
Disentangled Representation Learningによる顔のなりすまし検知
3つの要点
✔️ Face Anti-spoofingのタスクにDisentangled Representation Learningを導入して潜在特徴をLiveness FeatureとContent Featureに分解
✔️ 低レベルのテクスチャ情報と高レベルのDepth情報を組み合わせてLivenessの特徴空間を正則化
✔️ 代表的なベンチマークによる実験を行い、SOTAと比較して有効性を検証
Face Anti-Spoofing Via Disentangled Representation Learning
written by Ke-Yue Zhang, Taiping Yao, Jian Zhang, Ying Tai, Shouhong Ding, Jilin Li, Feiyue Huang, Haichuan Song, Lizhuang Ma
(Submitted on 19 Aug 2020)
Comments: Accepted by ECCV2020
Subjects: Computer Vision and Pattern Recognition (cs.CV)
概要
画像認識の精度向上に伴い、人よりも高性能な顔認証技術が利用できるようになりました。今では、スマートデバイス、アクセス制御、セキュリティなど身近なところで広く利用されています。
しかし、人の顔画像は身近で簡単に手に入るため、他人へのなりすましリスクが懸念されています。他人へのなりすましはPresentation Attack(PA)とも呼ばれ、印刷された画像、電子デバイスによる動画、3Dマスク、化粧など多くの手法が報告されています。安全安心な顔認証システムを提供するためには、なりすましに堅牢な顔認証技術が不可欠です。
代表的なPAには動画像に特有の痕跡が含まれているため、これまではテクスチャ分析に基づく手法が提案されていました。他分野と同様に、ハンドクラフトベースとCNNベースがあり、ハンドクラフトベースでは、Local Binary Pattern(LBP)/ Histogram of Oriented Gridients(HOG)/ Scale Invariant Feature Transform(SIFT)などが用いられ、動画で唇の動きや瞬きなどのモーションに着目することで、なりすましを検知する方法などがあります。しかし、これらの方法では、電子デバイスで再生されるPAを検出することができません。
近年では、深層学習の進歩に伴い、畳み込みニューラルネットワーク(CNN)ベースの方法が、顔のなりすまし検知において大きな進歩を遂げてきました。この方法では、なりすまし検知のタスクをSoftmaxを用いたバイナリ分類として扱います。しかし、本質的ななりすましの痕跡を学習することが難しく、特定のデータセットにオーバフィットし、一般化性能が不足していることがほとんどです。
最近では、なりすまし検知に有用なDepth MapやrPPGなど補足情報を使用することで、より高精度でなりすましを検知できるようにする技術が報告されています。しかし、これは、なりすましに有用な特徴を事前に定義する必要がありますが、このような情報を全て洗い出すことは現実的ではありません。
顔のなりすまし検知では、なりすましのパターンを正確に事前に定義する方法ではなく、高次元の特徴量からなりすましパターンをいかに表現する方法が重要になってきます。
ここで、考えられる解決策の1つが、Disentangled Representation Learning(DRL)です。このDRLは、高次元の情報は、実質的に低次元で意味のある潜在表現変数によって説明できるという前提の手法です。
顔のなりすまし検知では、なりすましのパターンは、特定の無関係なノイズタイプやその組み合わせだけでなく、顔の属性の1つと見なすことができます。したがって、顔画像のすべてのバリエーションからLivenessの特徴量を抽出することを直接のターゲットとすることで、なりすまし検知に有用な特徴を学習できると考えられます。
この論文では、この考えに基づいて、下図に示すように、潜在表現(Latent Representation)を分離するDisentangled Representation Learningを用いた顔のなりすまし検知の手法を提案しています。顔画像の潜在空間(Latent Space)は、Liveness空間とContent空間の2つの空間に分解できると想定しています。ここで、Liveness FeatureはLivenessに関する特徴量で、Content FeatureはIDや照明状況などに関する特徴量を表します。
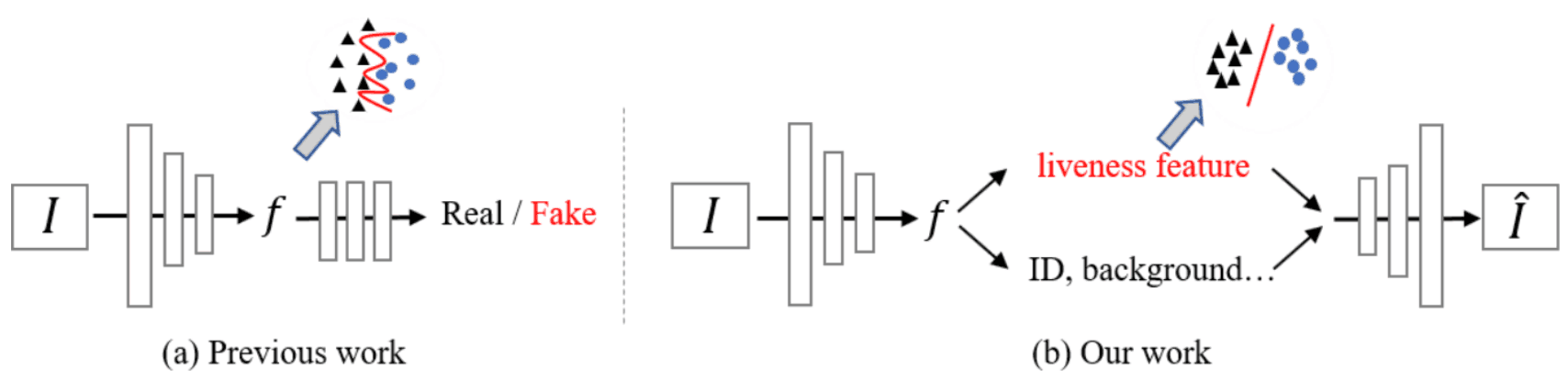
なりすましの特徴を表現するLivenessの特徴量を抽出し、他のノイズ情報に左右されない、より本質的な情報を使ってなりすまし検知を行うため、従来よりも一般化性能の高いモデルを実現することができるとしています。
続きを読むには
(5514文字画像16枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






