Depthの時空間情報を学習して顔のなりすまし検知の精度を向上する「FAS-SGTD」
3つの要点
✔️ 詳細な空間情報を特徴量化するResidual Spatial Gradient Block(RSGB)と、その時間変化を特徴量化するSpatio-Temporal Propagation Module (STPM)を組み合わせ、Depthを含む時空間を考慮する新しいフレームワークを提案
✔️ 詳細な顔のなりすましパターンをより適切に学習するため、Euclidean Distance Loss (EDL)ではなく、Contrastive Depth Loss(CDL)を導入
✔️ 代表的なベンチマークで最先端の性能を達成
Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing
written by Nilay Sanghvi, Sushant Kumar Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh
(Submitted on 18 Mar 2020)
Comments: Accepted by CVPR2020
Subjects: Computer Vision and Pattern Recognition (cs.CV)
概要
顔認証システムの導入が進む一方で、なりすまし検知の重要性も高まっています。
なりすましには、大きく3つあります。1つ目は印刷された顔写真を利用する手口(Print Attack)、2つ目はスマホなど電子デバイスに表示した顔画像を利用する手口(Replay Attack)、3つ目は人にそっくりな物理的な3Dマスクを利用する手口(3D Mask Attack)です。
この論文では、3つのなりすまし手法のうちPrint AttackとReplay Attackをより高精度で検知する新しい手法を提案しています。
ここ数年の研究でDepth情報を用いることでなりすまし検知の精度を向上することが報告されています。本物の顔には凹凸がある一方で、Print AttackとReplay Attackでは表面が平な紙やディスプレイで表示され、凹凸の特徴がないため、Depth情報を利用することで高精度になりすましを検知することができます。
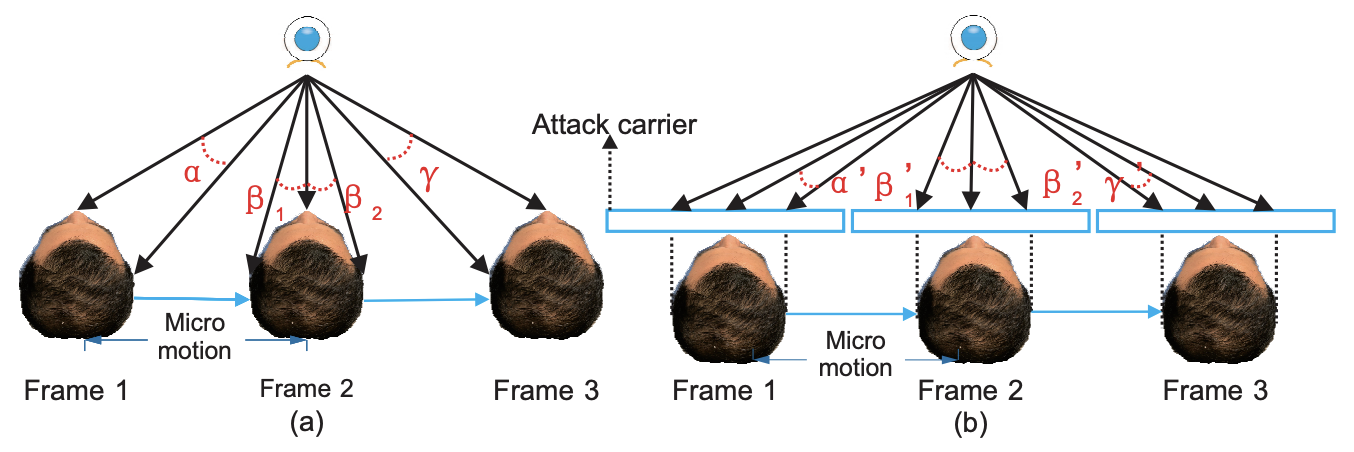
従来の研究では、カメラで撮影した映像の単一フレームから空間情報を利用してDepthを推定しています。しかし、この論文では、正確にDepthを推定するためには、複数フレームから空間情報の時間変化も考慮する必要があるとしています
下図がこの説明を極端ですが、わかりやすく表したものです。(a)が本物の顔を撮影している様子で、(b)がPrint AttackとReplay Attackを撮影している様子です。
(a)をみてみると、フレームごとに顔が右に動いた場合、鼻の中心と耳までの距離が変化します。この場合、α > β2となるはずです。しかし、(b)をみてみると、顔が同じように動くと、α' < β'2となり、大小関係が逆になります。
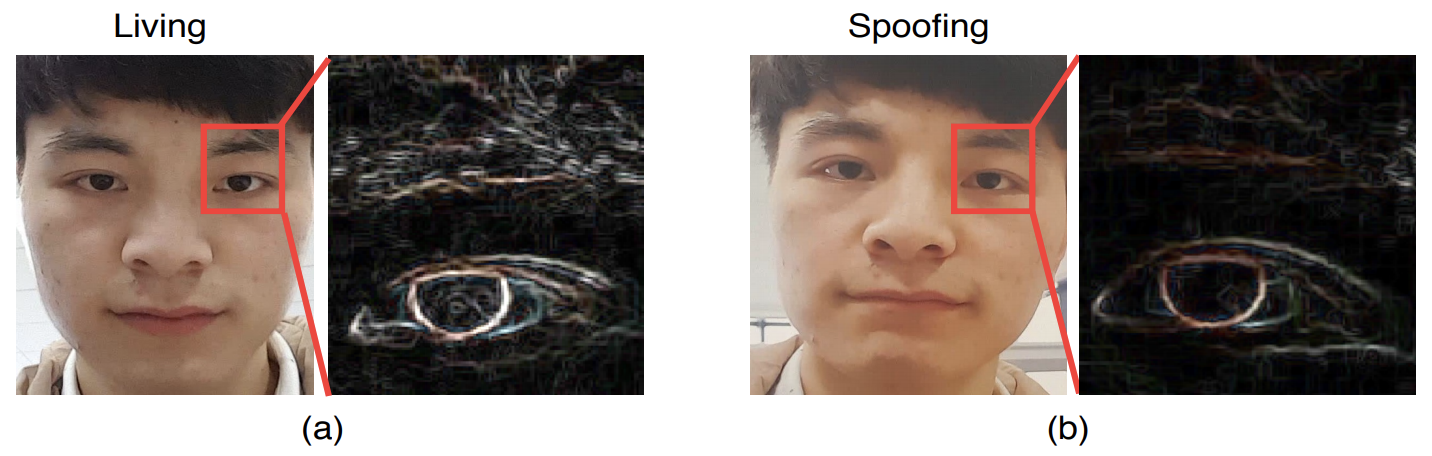
また、従来に比べてより詳細な空間情報を取得するために、Sobel演算による空間勾配も利用しています。
下図のように、なりすましにおいて空間勾配に大きな差が生じるためです。
続きを読むには
(6236文字画像22枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






