二次元GANは三次元形状を知っているか?
3つの要点
✔️ GANが三次元情報を暗黙的に学習していることを実証
✔️ 二次元画像を元に学習されたGANから教師なしで三次元形状を復元する手法を提案
✔️ 三次元形状復元や顔画像の回転などで既存手法と比べて優れた性能を発揮
Do 2D GANs Know 3D Shape? Unsupervised 3D shape reconstruction from 2D Image GANs
written by Xingang Pan, Bo Dai, Ziwei Liu, Chen Change Loy, Ping Luo
(Submitted on 2 Nov 2020 (v1), last revised 21 Feb 2021 (this version, v2))
Comments: Accepted to ICLR2021 oral.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
dataset:

はじめに
GAN(Generative Adversarial Network)は、画像生成などにおいて非常に優れた性能を示し、多様なデータを生成することに成功しています。本記事で紹介する論文では、二次元画像により学習されたGANが、三次元情報をも暗黙的に捉えることができることを示しました。
つまり、二次元画像をもとに学習されたGANから、二次元画像の三次元形状を復元することが可能であることを実証しました。イメージは以下の図の通りです。

提案されたフレームワークは、二次元画像から三次元形状を(教師なしで)復元できる上に、視点の変更(回転)や証明の変更などの高度な操作をも行うことができます。以下に見ていきましょう。
手法
提案手法の全体図は以下の通りです。 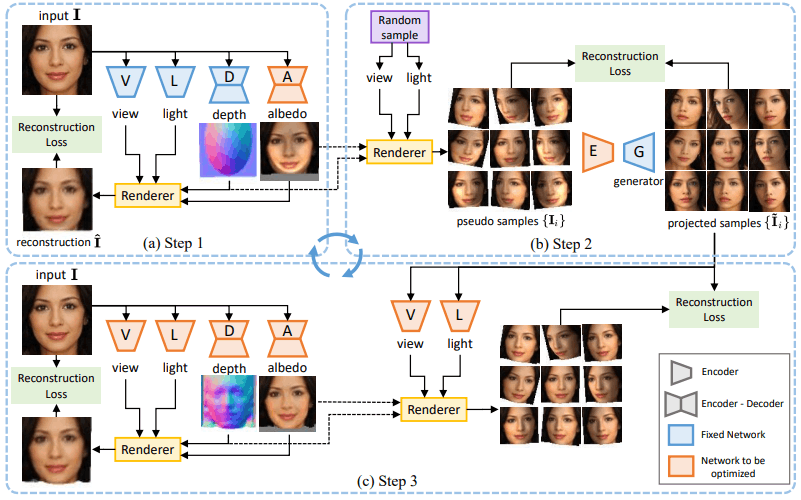
この手法は先行研究に従っています。
このとき、画像$I \in R^{3×H×W}$を入力として、深度マップ$d \in R^{H×W}$(奥行き情報)、アルベド(Albedo:反射能)画像$I \in R^{3×H×W}$、視点$v \in R^6$、光の方向$l \in S^2$からなる四つの情報を予測する関数を利用します。これは図の左上(a)から分かる通り、四つの情報に対応するサブネットワーク($D,A,V,L$)をそれぞれ利用して予測されます。
これらの四つの情報は、Lighting$\Lambda$、Reprojection$\Pi$の二つのステップからなるレンダリング処理を経て、元の入力を復元するように学習されます。
Lighting$\Lambda$は、画像の三次元情報(奥行き・反射能・光の方向)をもとに三次元外観を構成するようなイメージ、reprojection$\Pi$は三次元での外観を二次元画像に投影するようなイメージであるといえます。 これらを経て画像の復元を行い、$\hat{I}$を得る処理は以下の式でまとめられます。
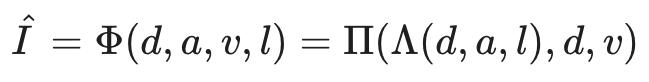
この設計は先述の通り先行研究に従っていますが、先行研究では物体形状の左右対称性を仮定として採用しているのに対し、本手法ではGANを利用した以下の手順により、この仮定を回避し、物体の非対称性をより良く捉えることができます。
Step 1(図a):弱い形状の利用
顔や車を始めとした多くの物体は、やや凸状の形状をしていると考えられます。
そこで図(a)のdepthの通り、画像$I$に対応する深度マップ$d$を、楕円状に初期化します。このとき、既存のシーン解析モデルを利用して、楕円が画像内のオブジェクトと大まかに一致するよう配置します。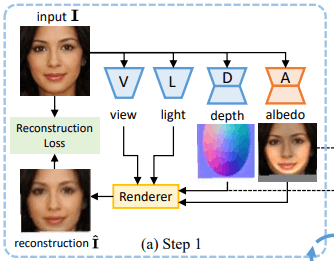
さらに、視点は$v_0=0$、光の方向は正面からであるとして初期化し、再構成損失をもとにアルベドネットワーク$A$の学習を行います。
Step 2: サンプリングとGAN image manifoldへの投影
視点$v$・光の方向$l$をランダムにサンプリングし、レンダリングを行って疑似サンプル$\{I_i\}$を取得します。
これらの疑似サンプルは下図の通り、不自然な歪みや影を有していますが、顔の回転(視点の変化に対応)や光の変化(光の方向の変化に対応)についての情報も持っています。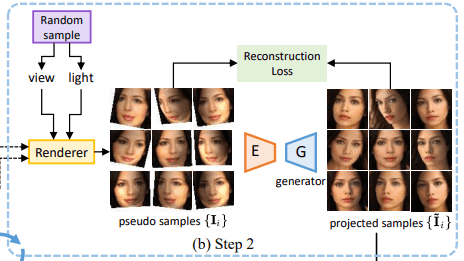
ここで、これらの疑似サンプルに対してGANのGeneratorによる再構成を行います。具体的には、各サンプルの中間潜在ベクトル$w_i$を予測するようにエンコーダ$E$の学習を行います(GANのGeneratorの学習は行いません)。このとき、最適化目標は次の式で与えられます。
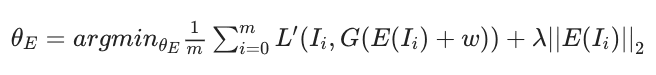
ここで、$m$はサンプル数、$\theta_E$はエンコーダ$E$のパラメータ、$\lambda$は正則化係数、$L^{\prime}$は画像の距離の指標(提案手法ではL1距離)となります。
$\lambda||E(I_i)||_2$は正則化項で、潜在オフセットが大きくなる(中間潜在ベクトル分布から大きく外れる)ことを防ぎます(論文では強力な正則化を行う手法も適用されています)。
GANのGeneratorを用いていますが、先述の通りGeneratorの学習は行いません。そのため、入力画像に不自然な(通常の二次元画像には存在せず、GANの出力にも通常含まれないような)歪みや影が存在していたとしても、Generatorの生成結果には(通常のGANの出力と同様に)このような歪みや影は出現しません。
そのため、疑似サンプル画像の持つ視点・光の変化等の情報を適切に保持しつつ、通常の二次元画像には含まれない不自然な歪みや影を修正した、自然な画像を生成することができます。
Step 3: 三次元形状の学習
Step 2で得られた生成結果(投影サンプル$\tilde{I}_i$)は、元画像$I$の視点・光の方向をうまく変化させたものであるといえます。
Step 3ではこれらの情報を利用することで、三次元形状の学習を行います。具体的には以下の図の通り、視点・照明ネットワーク$V,L$は、各サンプル$\tilde{I}$ごとの視点・照明方向$\tilde{v}_i,\tilde{l}_i$を予測します。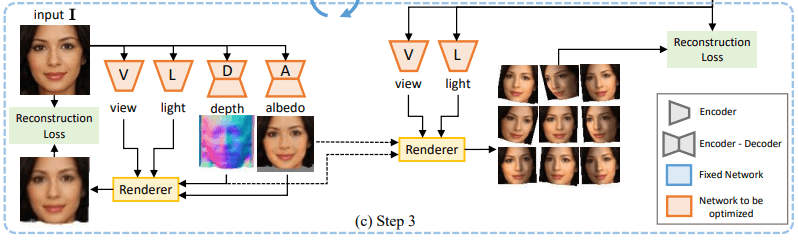
深度・アルベドネットワーク$D,A$は、元画像$I$を入力として深度・アルベド画像$\tilde{d},\tilde{a}$を出力します。これらの予測結果を元にレンダリングを行い、これが各サンプル画像を再構成するように学習を行います。ここで、四つのネットワークは、以下の再構成目的により共同で学習されます。
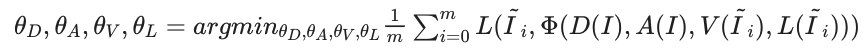 このとき、Step 2で生成された投影サンプル$tilde{I}_i$だけでなく、元画像$I$も同時にサンプルの一つとして利用します。
このとき、Step 2で生成された投影サンプル$tilde{I}_i$だけでなく、元画像$I$も同時にサンプルの一つとして利用します。
また、Step 2で各サンプルごとに視点・光の方向$v_i,l_i$をランダムにサンプリングしましたが、これはStep 3の学習時には利用しません(GANのGeneratorで生成された際、視点や光の方向が変化している可能性があるため)。 これらのStep1~3を反復して実行することで、適切に三次元情報の学習を行います(実験では四回繰り返します)。 
ここまでの議論では元画像$I$を単一画像としていますが、これは複数の画像に拡張することもできます。
実験
実験では、三次元形状復元について提案手法を評価し、次に視点変更などの三次元的画像操作への応用を行います。
実験設定
・データセット
使用したデータセットは以下の通りです。
・GANモデル
提案手法内で用いられるGANには、先述したデータセットで事前に学習されたStyleGAN2を用います。
教師なし三次元形状再構成
・定性的評価
提案手法並びに先行研究のUnsup3dでの定性的な結果は以下の図で示されます。

図の通り、人間の顔や猫、車、建物などの三次元形状を高い品質で復元することができます。Unsup3d手法もある程度良好な結果を示していますが、特に車や建物などの非対称な物体ではうまく機能していない傾向があります。
・定量的評価
定量的評価にはBFMデータセットを利用します。ここで、先行研究に従い、指標としてSIDE(scale-invariant depth error)とMAD(mean angle deviation)を用いて評価を行います。結果は以下の通りです。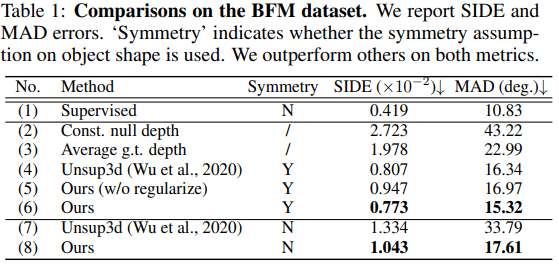
Symmetryは対称性の仮定を用いた場合(Y)または用いなかった場合(N)を示しています。総じて先行研究(Unsup3d)を上回る結果を示しています(表の(6),(8))。また、潜在オフセット正則化を用いなかった場合が(5)に示されており、提案手法での正則化が有効に機能していることが示されています。
さらに、提案手法では形状(深度マップ)の初期化に楕円形を用いていましたが、異なる設定で初期化した場合の比較結果は以下の通りです。

詳細は省きますが、形状初期化の設定が性能にもたらす影響は小さいことが分かります。ただし、平面形状(Flat)の場合では性能が大きく悪化しているため、少なくとも視点や光の方向の変化を捉えられるような三次元形状で初期化されている必要はあると考えられます。
三次元的画像操作について
・物体の回転と再照明(Relighting)
提案手法は学習完了後、視点$v$や光の方向$l$を変更してレンダリングを行う(またはエンコーダ$E$とGAN Generator$G$を経由する)ことにより、三次元的な画像操作を行うことが出来ます。
以下の図では、物体の回転と再照明を行った場合の結果を示しています。 
Rotation(Relighting)-3Dは(復元した三次元形状とアルベド画像から)レンダリングを行った場合を、Rotation(Relighting)-GANはエンコーダ・GANを介して画像を生成した結果を示しています。レンダリングした結果は物体の構造を忠実に反映しており、またGANを用いた場合は非常に自然で現実的な画像が生成されており、どちらも有効に機能していることがわかります。
・Identityを保持する顔回転
GANを用いて顔回転を実行することができる教師なし手法(HoloGAN、GANSpace、SeFa)と提案手法の比較を行います。
具体的には、各手法について100枚のランダムな顔画像を-20度~20度回転させて20枚のサンプル画像を取得し、一般的な顔identity検出モデルArcFaceを用いた場合、回転中に顔identityがどのように変化するかを評価します。顔画像の回転が適切に行われていれば、顔identityは大きく変化しないと考えられます。結果は以下の通りです。
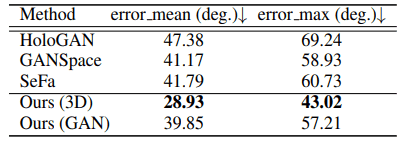
表の通り、既存手法と比べて損失は非常に小さく抑えられており、顔identityが有効に保持されていることがわかります。また、実際の生成例は以下の通りです。
既存手法では回転により顔が大きく変化している(例えばGANSpaceのrightでは性別が変わっている)のに対し、提案手法(Ours)では同一人物だと認識できます。
今後の課題について
提案手法は非常に有効に機能していますが、以下の図で示されるように、三次元形状の復元が正確に行えない場合も存在しました。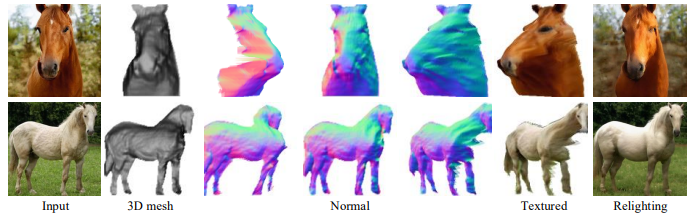
これは、提案手法の形状の初期化が単純な凸形状になっていることに起因していると考えられます。また、提案手法の三次元形状は深度マップによりパラメータ化されているため、オブジェクトの裏側の形状はモデル化することができません。これは、三次元メッシュを深度マップ以外の何らかの形式で扱うなど、より良いパラメータ化を行うことにより解決できる可能性もあり、今後の発展に期待が持てるでしょう。
まとめ
本記事で紹介した論文では、二次元画像を元に学習されたGANから、教師なしで三次元形状を復元する画期的な手法を提案しました。これは、三次元形状復元タスクへの有効な手法を提案したのみならず、GANが三次元的な情報をも暗黙的に学習していることをも示しています。GANは画像生成にて大きな成功を収めていますが、その潜在能力がさらに明らかになったと言えるでしょう。





この記事に関するカテゴリー






