GANで限られたデータから高精度画像を生成
3つの要点
✔️ 限られたデータでGANを学習するために、APA(Adaptive Pseudo Augmentation)と呼ばれる新規augmentation手法を提案
✔️ APAが最適解に収束することを理論的に証明
✔️ 複数のデータセットに対して、 APAを使用したモデルは、従来のSOTAモデルを上回った
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
written by Liming Jiang, Bo Dai, Wayne Wu, Chen Change Loy
(Submitted on 12 Nov 2021)
Comments: NeurIPS 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
StyleGAN2などを始めとしたGANのSOTAモデルは、非常に高精度な画像を生成することができる一方で、大量の学習データを必要とします。しかしながら、データの乏しさやプライバシーの問題など、十分な学習データを入手することができない場合があります。一般に、GANの学習データが少ない場合、Discriminatorがoverfitし、真の画像と偽の画像に対する出力分布が離れてしまいます。その結果、Generatorへのフィードバックが無意味な情報となり、生成される画像精度が劣化します。そこで本論文では、APA(Adaptive Pseudo Augmentation)と呼ばれる新規augmentation手法を開発しました。APAでは、overfitting度合いに応じて、Generatorの生成した画像を真の画像とみなし、Discriminatorを適応的に騙すことで確度を下げます。その結果、Discriminatorがoverfitしにくくなり、生成画像の精度向上が期待できます。
APA
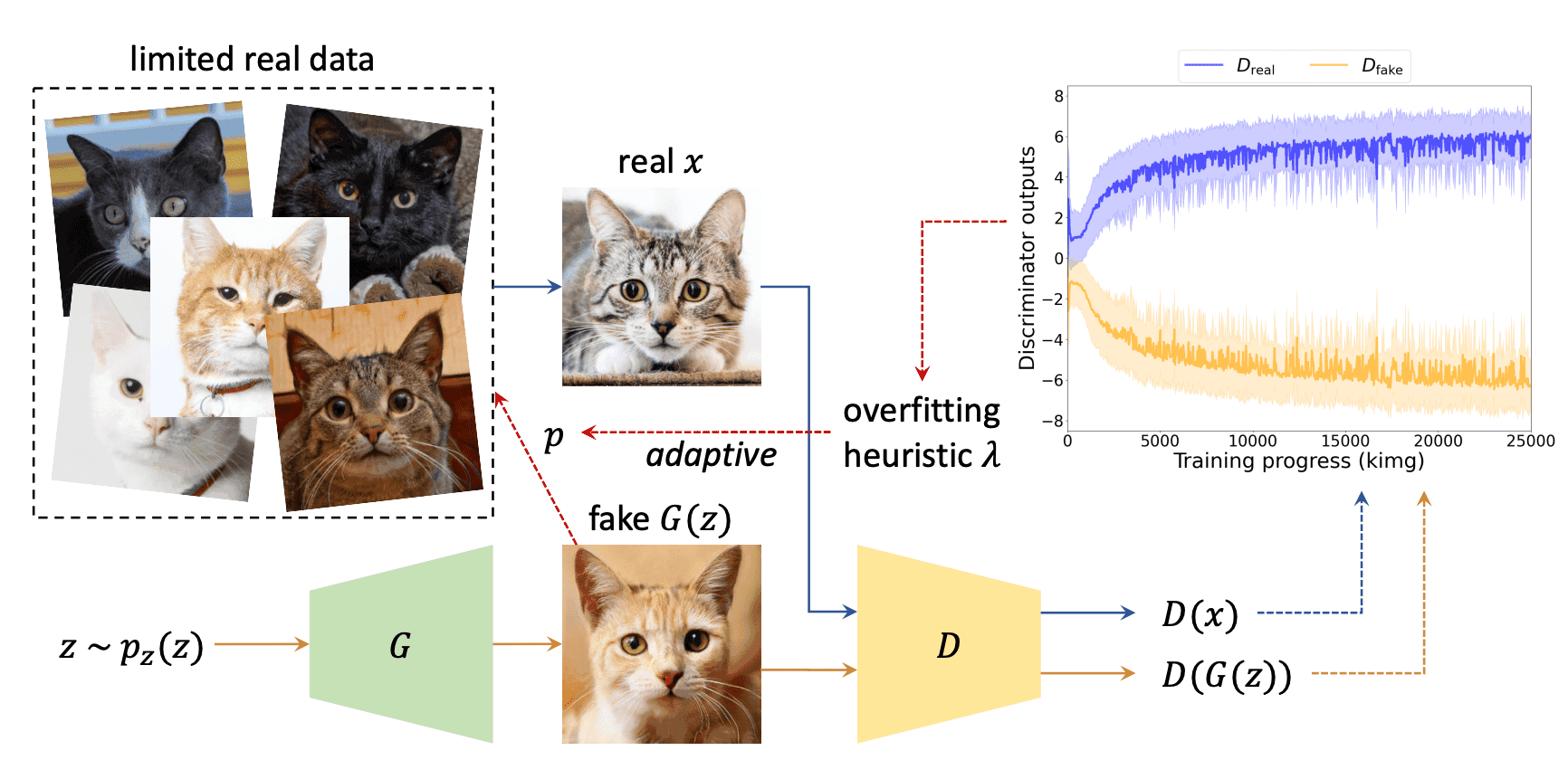
上図に示すように、Generatorによって生成された画像を擬似的に真の画像とみなし、Discriminatorを騙します。闇雲に偽の画像を真の画像としてもうまく行かないので、ある確率$p \in [0,1)$で実行し、$1-p$の確率で何もしないpseudo augmentationを用いました。ここで$p$はDiscriminatorのoverfit度合いに応じて変化し、次式で定義されるパラメータ$\lambda$を用いて調整されます。
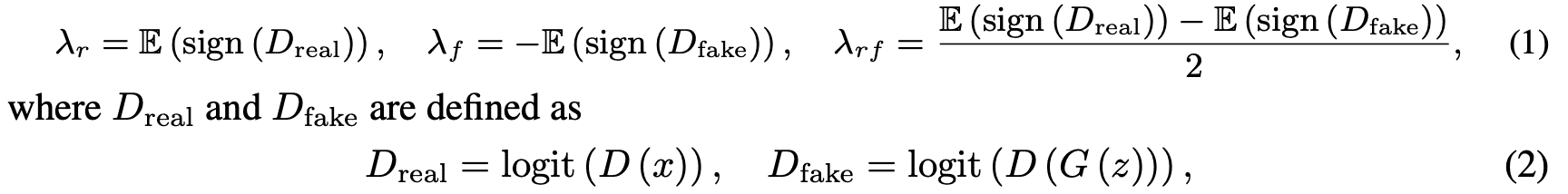
ここで$D,G$はDiscriminatorおよびGenerator、$x$は真の画像、$z$はノイズパラメータ、logitはlogit関数です。$\lambda_r$はDiscriminatorが真の画像に対して、正のlogitを予測する割合を表し、$\lambda_f$は偽の画像に対する割合を表します。さらに、$\lambda_{rf}$は真の画像と偽の画像に対するlogit間の半分の距離を表します。すべての$\lambda$に対して、$\lambda=0$は全くoverfittingしていない状態、$\lambda=1$は完全にoverfittingしている状態を表します。本論文では特に$\lambda_r$をパラメータとして用いました。具体的には、$p=0$で初期化し、閾値$t$(主に用いた値は0.6)に対して、$\lambda$が$t$を上回る(下回る)場合、$p$を1ステップ増加(減少)します。これを4イテレーション毎に繰り返し、overfitting度合いに応じて適応的にpseudo augmentationをすることができます。
理論的考察
$\alpha$を$p$の期待値とすると、$0\leq\alpha<p_{\rm max}<1$ を満たし、GeneratorとDiscriminatorの価値関数$V(G,D)$は次式のようになります。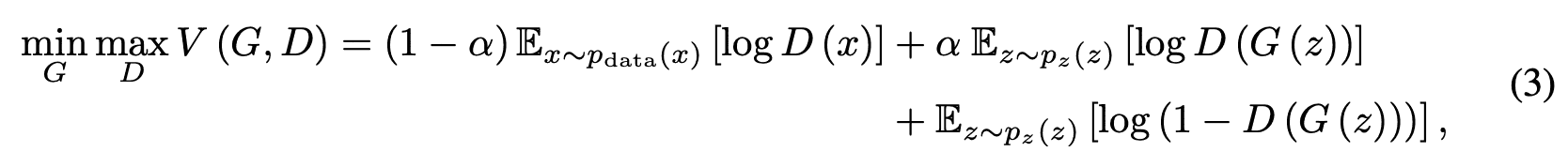
すると、以下の命題が成立します。
命題1
$G$が固定の時、$D$の最適解は
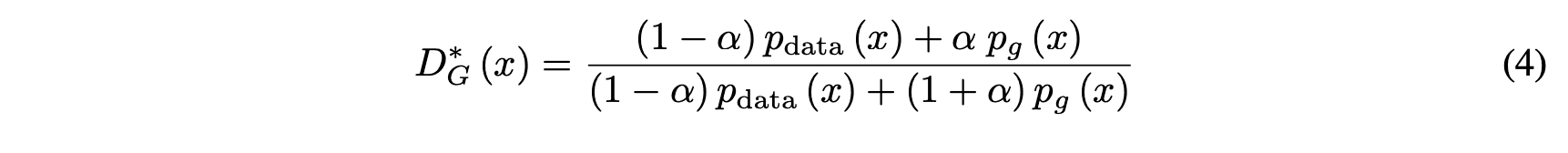
ただし$p_{data}(x), p_g(x)$は真のデータと偽のデータの従う確率分布
証明
任意の$G$に対して、$D$は$V(G,D)$を最大化することが目的なので
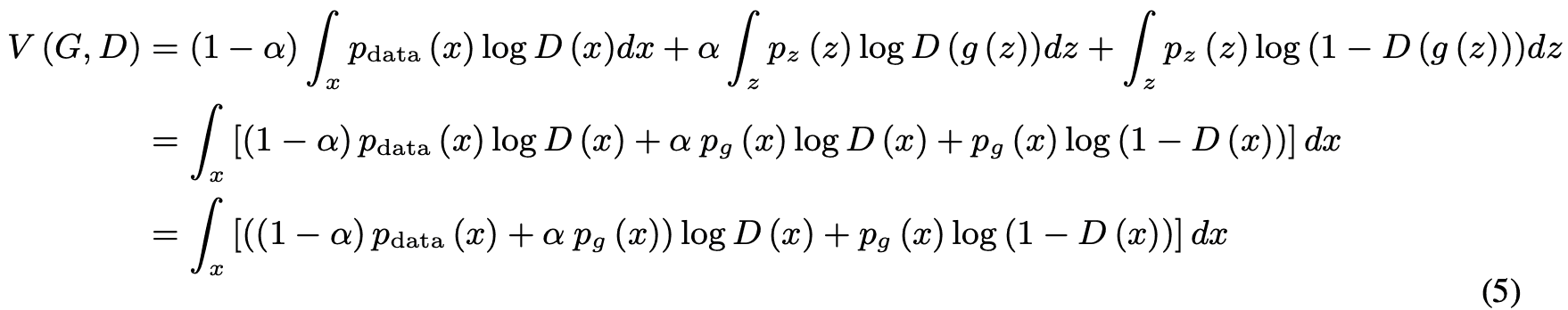
ここで、$m=n=0$を除く任意の実数$(m,n)$に対して$f(y)=m\log(y)+n\log(1-y)$は$y=\frac{m}{m+n}$の時に最大となります。また、$D$は$p_{data}$または$p_g$の$supp$(台)内で定義されるので、命題1を満たします。(証明終)
ところで、$D$が最適解を取る時、$G$の目的は$V(G,D)$を最小化することですが、$D$の目的は、入力$x$に対する予測$Y$の条件付き確率$P(Y=y|x)\ (where\ y=0\ {\rm or}\ 1)$の対数尤度の最大化なので、評価関数を次のように書けます。
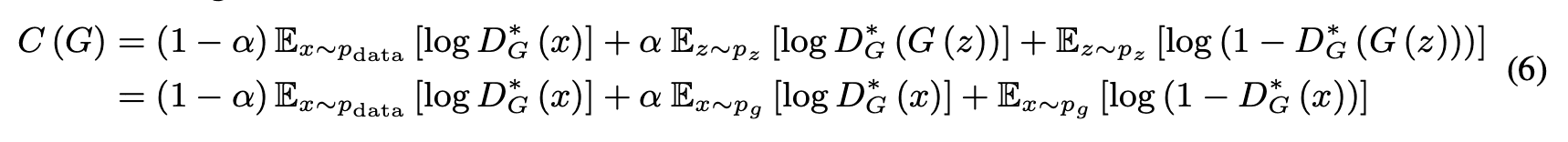
次に、$C(G)$の大域的最小値を考えます。
命題2
$C(G)$が大域的最小値となるのは、$p_g=p_{data}$の時に限り、最小値は$C(G)=-\log 4$
証明
1)$p_g=p_{data}$の時、式(4)より$D^*_G(x)=\frac{1}{2}$
これを式(6)に代入すると$C^*(G)=(1-\alpha)\log\frac{1}{2}+\alpha\log{1}{2}+\log{1}{2}=-\log4$
2)式(5)より
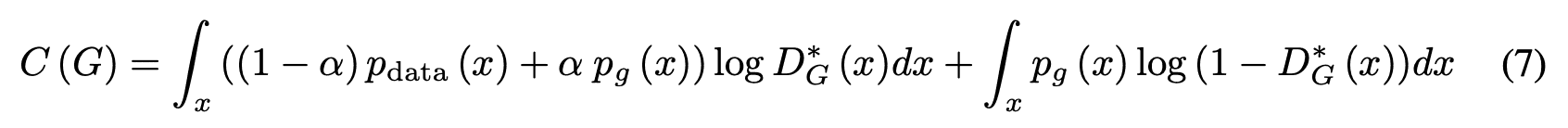
式(6)は$p_g=p_{data}$の時
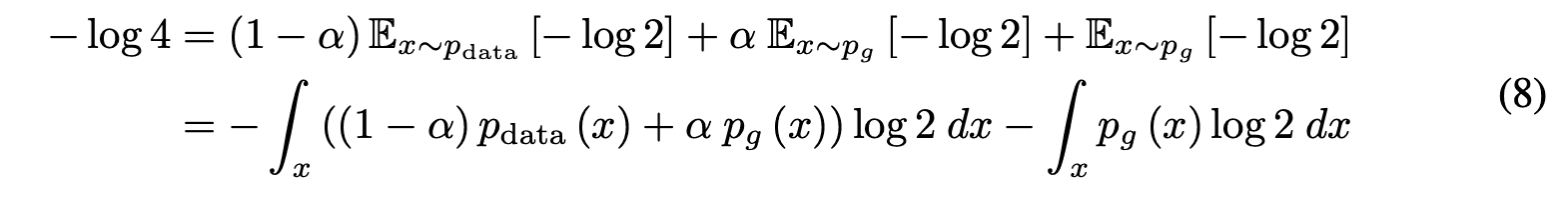
式(8)から式(7)を引くと
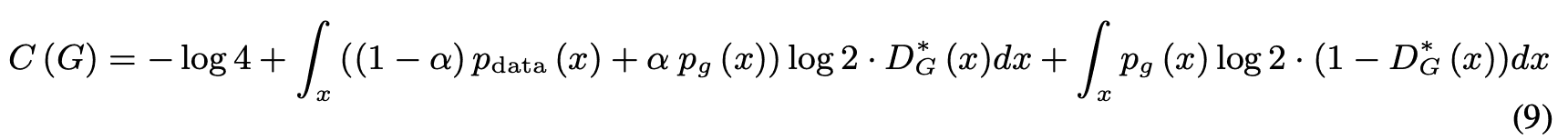
式(4)を式(9)に代入して
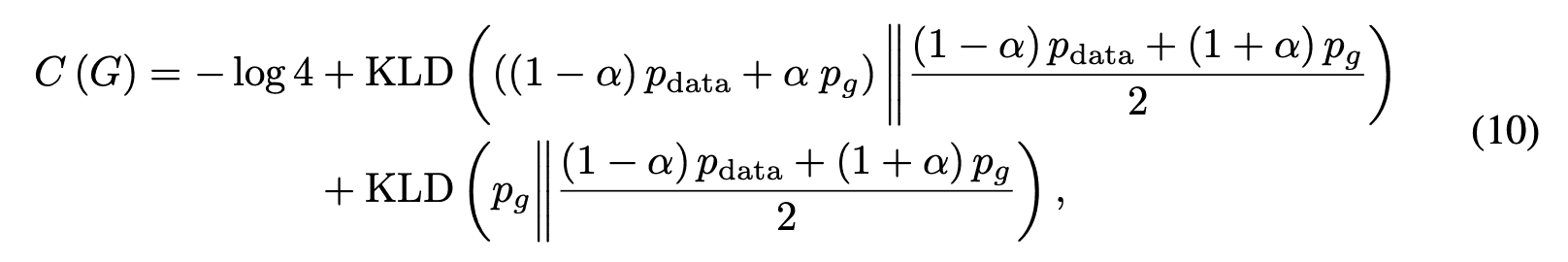
ここでKLDはKLダイバージェンスです。さらに式(10)はJSダイバージェンスJSDを用いて次のように表せます。
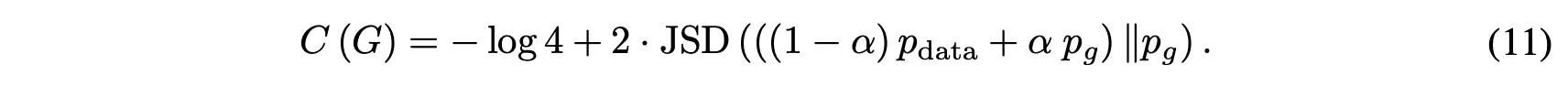
$JSD(P||Q)$は$P=Q$の時に最小値0を取るので、$C(G)$は${p_g}=p_{data}$の時にのみ最小値$-\log 4$を取ります。(証明終)
実験結果
限られたデータで学習した、StyleGAN2とAPAの生成画像は下図のようになりました。すべてのデータセットに対して、StyleGAN2では劣化が生じているのに対し、APAではほとんど劣化が生じていません。

また、評価指標はFID(Frechet Inception Distance)とIS(Inception Score)を用い、下表のようになりました。FIDは低いほど良く、ISは高いほど良いので、すべてのデータセットでAPAの方が高い性能を示しています。

さらに、FFHQデータセットに対して、学習データ数を変化させたときの結果はそれぞれ下の図と表のようになりました。やはり、すべてのパターンにおいて、APAの方が定性的にも定量的にもStyleGAN2を上回っており、十分なデータで学習した場合でもAPAが有効であることを示しています。

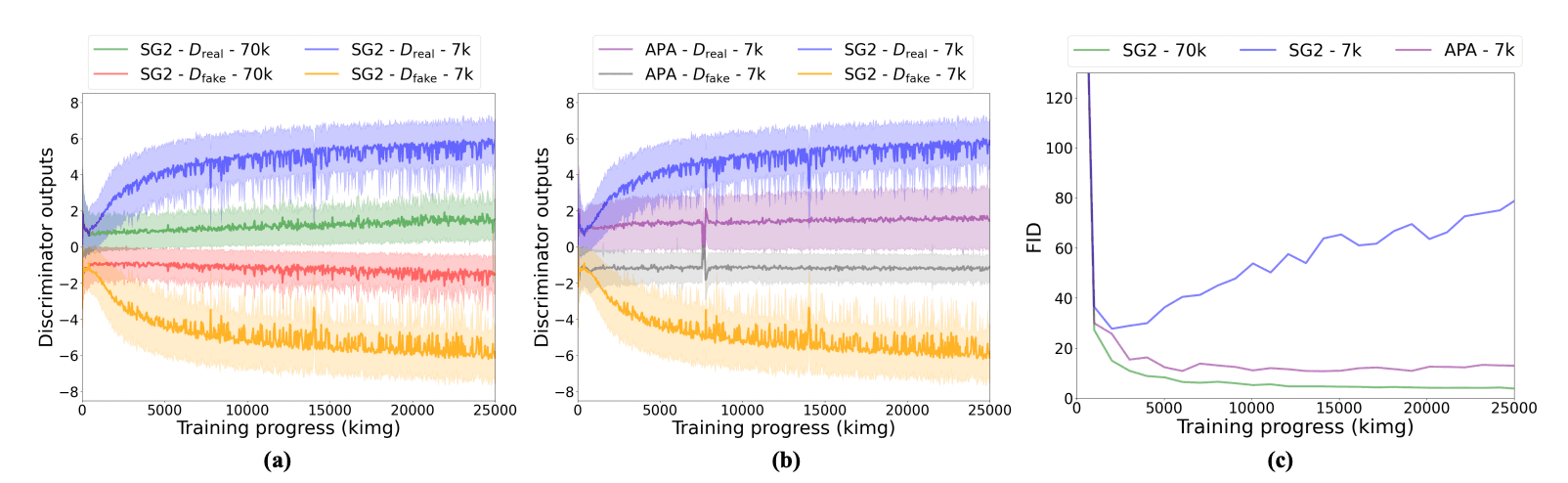
なお、Discriminatorのoutputは、StyleGAN2の場合、下図(a)のように、データ数が少なくなると真と偽の予測確率の差が広がり、overfitしてしまいますが、APAは下図(b)のように差が縮まり、十分量で学習したStyleGAN2に近い振る舞いをしています。FIDに関しても、APAは下図(c)のように限られた学習データでも収束することが分かります。
最後に、パラメータ$\lambda, p$を変えた場合、ラベル反転を真と偽の両方に行った場合、閾値$t$を変えた場合の比較結果は下表のようになりました。APAのmainで用いた値と比べてほぼ近い性能を示し、StyleGAN2よりも良い結果となっています。

まとめ
本論文では、限られたデータからGANで高精度な画像を生成するために、APAと呼ばれる手法を提案しました。その結果、無視できる計算コストで従来手法よりも大きく改善し、今後さまざまな場面で応用が期待できます。しかしながら、限られたデータから高精度な画像が生成できる技術は、悪用される危険性もあり、データセットの扱いには注意が必要です。






この記事に関するカテゴリー






