GANももっとお手軽に使いたい
3つの要点
✔️ スケッチから生成モデルを作成
✔️ ベースラインと比較し、高精度を達成
✔️ 今後の改良が期待される
Sketch Your Own GAN
written by Sheng-Yu Wang, David Bau, Jun-Yan Zhu
(Submitted on 5 Aug 2021)
Comments: Accepted by ICCV 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
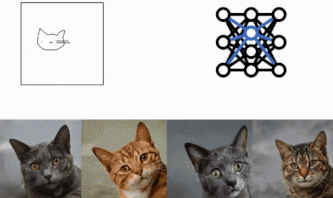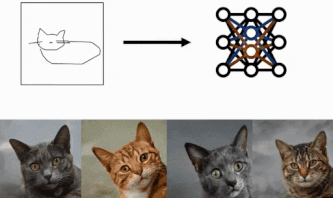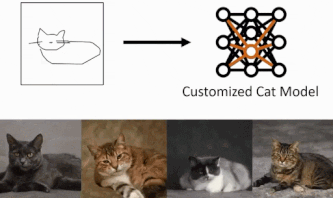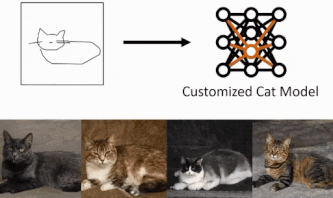
GANは技術が発展し、高品質な画像を生成することができるようになりました。もちろん、いくつかの制限はありますが、GANの有用性はどんどん高まってきています。ただいくつかの制限がある中で、一般のユーザーにも活用できるのかという疑問がうまれます。こういった有用性の高い手法は専門者がいなければ、利用できないのは大きな障壁に感じることでしょう。例えば、猫を使った作品を制作するユーザーが、寝そべっている猫、左を向いている猫など、特定のポーズをとった特別な猫画像を生成しようとした時にどうすれば良いのでしょうか?このようなカスタマイズされた生成を得るために、本論文では手描きのスケッチから生成モデルを作成するというタスクを提案し、この課題に挑んでいます。スケッチから単一の画像を作成するのではなく、手描きのスケッチから現実的な画像の生成モデルを作成することが可能かと言うことです。下図に示すように、たった4枚の手描きスケッチで、物体のポーズを変えたり、猫の顔をズームアップしたりすることができます。
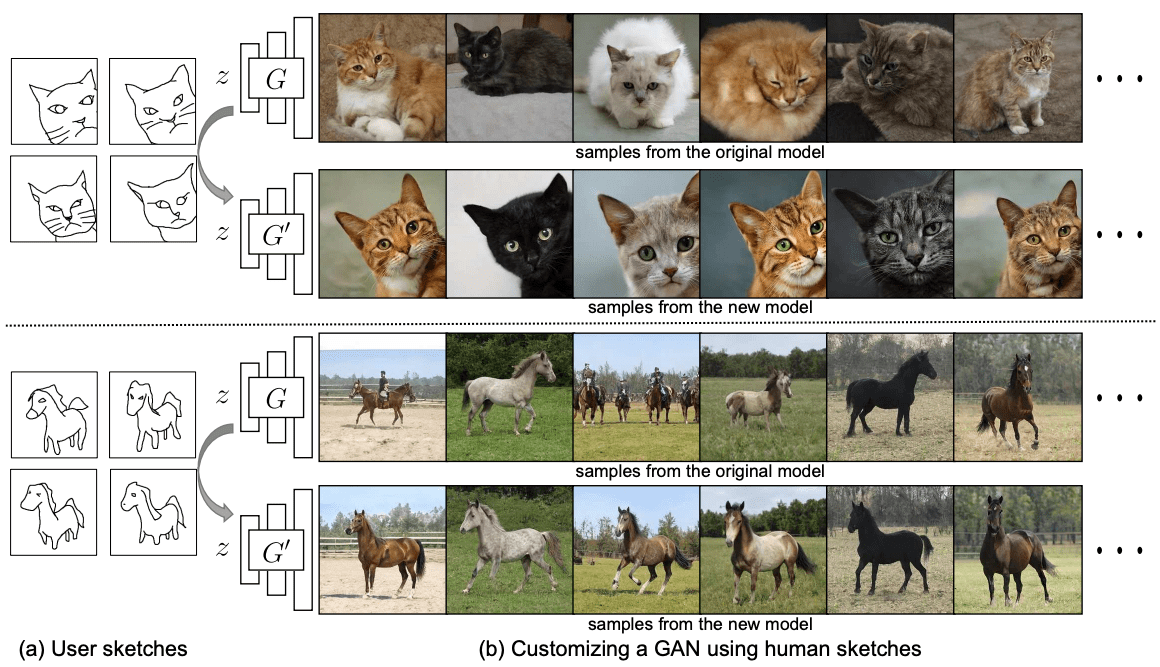
下に今回のタスクの概要イメージを載せておきます。

手法
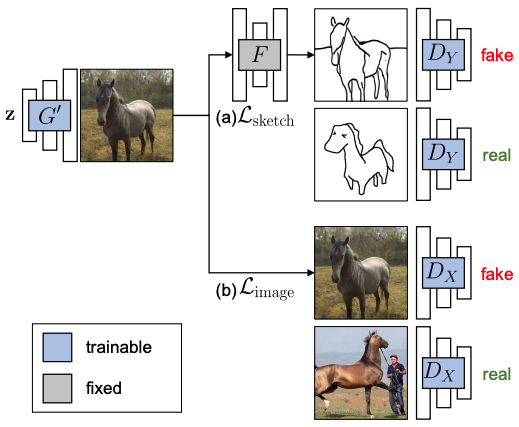
大きく分けて3つの構成で行っていきます。
- スケッチからGANモデルを作成するには、学習データ(=スケッチ)と出力(=画像)のミスマッチなので、従来通り、ドメイン変換ネットワークを用いて、クロスドメインの敵対的損失を導入しています。しかし、この損失を単純に使用すると、モデル自体の動作がかなり変化し、非現実的な結果が得られるという問題が発生するので、改良した損失を提案しています。→Cross-Domain Adversarial Learning
- 元のデータセットの内容とその多様性を維持するために、画像空間正則化を適用しながらモデルを学習していきます。→Image Space Regularization
- モデルのoverfittingを軽減するために、更新を特定の層に限定し、データの補強を行います。→最適化
全体の学習処理を下図に示します。
Cross-Domain Adversarial Learning
X , Y をそれぞれ画像とスケッチからなるドメインとします。大規模な学習画像x~$p_(data)$(x)と数枚の人間のスケッチy~$p_(data)$(y)を収集します。$G(z;θ)$を、低次元コードzから画像xを生成する事前学習済みGANとします。出力画像が依然としてXの同じデータ分布に従う一方で、スケッチバージョンの出力画像がYのデータ分布に似ている新しいGANモデル$G(z;θ')$を作成したいです。このネットワークは、写真とそのスケッチなどの入出力ペアを用いて学習させることができるが、その代わりに、画像からスケッチへのクロスドメイン画像変換ネットワークF : X → Yを利用します(F:Photosketch)。スケッチの学習データと画像生成モデルの間のギャップを埋めるために、生成された画像がスケッチYと一致するように、クロスドメインの敵対的損失を利用しています。識別器に渡す前に、生成器の出力は、事前に訓練された画像-スケッチネットワークFによってスケッチに転送されます(下式参考)。
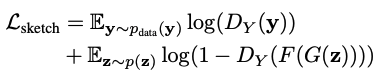
Image Space Regularization
スケッチに対する損失だけでは、生成される画像の形状がスケッチに一致するように強制されるだけになってしまします。すなわち、画質や生成の多様性が大幅に低下することが考えられます。この問題を解決するために、出力を元のモデルのトレーニングセットと比較する敵対的損失を追加しています。
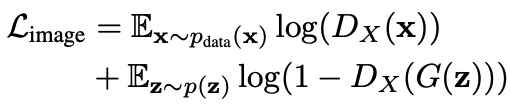
ここで、判別器$D_(X)$は、モデル出力の画質と多様性を維持し、ユーザーのスケッチに合わせるために使用されます。
また、下式の損失を利用して、大きな変動に対しては明示的にペナルティを課すという重み正則化の実験も行っています。実際には精度の改善は行われず、性能低下が起きることがわかりました。しかし、重み正則化と画像空間正則化のいずれかを適用することは、画質と形状マッチングのバランスをとるために重要であることが示唆されています。
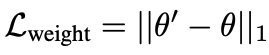
最適化
モデルのオーバーフィッティングを防ぎ、微調整を迅速に行うために、StyleGAN2ではマッピングネットワークの重みのみを変更し、z ∼ N (0, I)を異なる中間電位空間(W空間)に再マッピングしている。さらに、事前に学習させたPhotosketchネットワークFを使用し、学習によってFの重みを固定したという。 彼らは、トレーニング用のスケッチに最小限のオーグメンテーションを施す戦略で実験を行い、シーンテストではわずかなオーグメンテーションの方が良い結果が得られた。 今回の研究では、トランスフォームド・エンハンスメントを使用しました。
最終的な最適化式は以下になります。
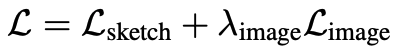 $λ_(image)$ = 0.7とし、画像空間正則化項の重要性を制御します。以下のミニマックスで、新しい重み$G(z; θ')$のセットを学習させます。
$λ_(image)$ = 0.7とし、画像空間正則化項の重要性を制御します。以下のミニマックスで、新しい重み$G(z; θ')$のセットを学習させます。
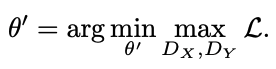
実験
データセット
大規模な定量的評価を可能にするために,以下のように定義された正解の分布を持つモデルスケッチのデータセットを構築しています。LSUNの馬、猫、教会の画像をPhotoSketchを用いてスケッチに変換し、下図に示すように、形やポーズが似ている30枚のスケッチのセットを手で選択し、ユーザーの入力としています。ターゲット分布を定義するために、入力されたスケッチと一致する2,500枚の画像をさらに手作業で選択しています。指定された30枚のスケッチにのみアクセスができ、2,500枚の実画像のセットは実際には見たことのないターゲットの分布となっています。
評価指標
生成された画像と評価セットの間のFrechet Inception Distance (FID)に基づいてモデルを評価します。FIDは、2つのセット間の分布の類似性を測定し、生成された画像の多様性と品質、および画像がスケッチとどの程度一致しているかを示す指標となっています。
ベースライン
Radfordらが提案されているベクトル演算法と同様に、ユーザのスケッチに似たサンプルを平均化して得られる定数ベクトル$Δw$を用いて、潜在的な$w_(new)$ = w + $∆w$をシフトさせてモデル出力をカスタマイズしたときの効果を評価します。($L_(sketch)$+$L_(image)$をFull (w/o aug.)・$L_(sketch)$+$L_(image)$+aug.をFull (w/ aug.))
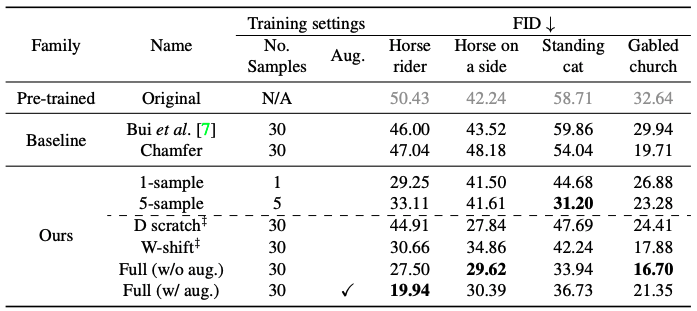
表に定量的な比較を示します。この結果は、上図で示した比較結果とも一致していることがわかります。ベースラインの手法はユーザーのスケッチと一致していないことがわかります。
アブレーションの研究
正則化手法とデータ増強の効果を検討しています。その結果を表に示します。
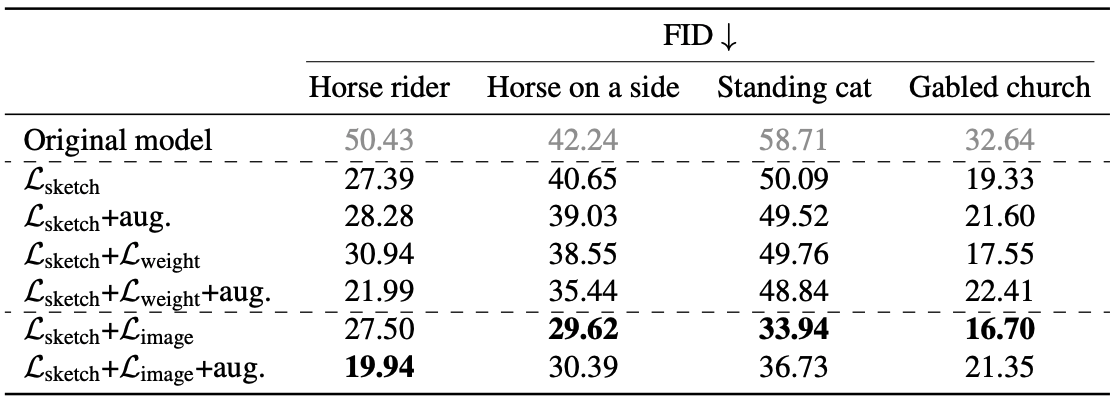
Photosketchから生成されたスケッチについては、補強を行っても必ずしも性能が向上しないことがわかります。画像の正則化を適用した場合、馬の乗り手のモデルは拡張の恩恵を受けますが、横向きの馬、立っている猫、などのモデル生成時は拡張なしの方が良い結果となりました。
正則化手法の比較
正則化手法である$L_(image)$または$L_(weight)$は、$L_(sketch)$のみで学習したモデルよりもFIDを向上させますが、画像正則化で学習したモデルの方が$L_(weight)$で学習したモデルよりも優れていることがわかりました。これは、正則化を用いて学習したモデルと用いないモデルの結果を下図に示しますが、上述の内容と一致しています。

まとめ
既製の学習済みモデルとクロスドメイントレーニングを利用して、ユーザがカスタマイズした生成モデルを作成できる手法を提案しています。本手法では、1枚の手書きスケッチを入力とすることで、初心者でもそのスケッチを生成するモデルを作成することが可能です。
しかし本手法は、すべてのスケッチに対して機能することができるわけではありません。例えば、ピカソの馬のスケッチなどでテストした場合は、失敗します。ピカソのスケッチは独特のスタイルで描かれていることが失敗の原因として考えられるなど、完璧ではありません。また、形状やポーズを柔軟に制御することはできますが、色や質感など、その他の特性をカスタマイズすることはできていません。ただ、今後このあたりは改善されていくかと思います。



この記事に関するカテゴリー





