複数人の顔を合成した画像を生成!Barbershop
3つの要点
✔️ 2つの顔画像を組み合わせた画像生成タスク
✔️ CycleGAN2等で用いられているW空間ではなく新たにFS空間を提案
✔️ 生成画像はいずれの指標においても既存手法を上回っている
Barbershop: GAN-based Image Compositing using Segmentation Masks
written by Peihao Zhu, Rameen Abdal, John Femiani, Peter Wonka
(Submitted on 2 Jun 2021)
Comments: Accepted by arXiv
Subjects: Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
code:

はじめに
GAN(Generative Adversarial Network)を用いた画像編集は近年、プロ向けのアプリケーションや一般ユーザー向けのソーシャルメディアでの写真編集ツールなどで広く利用されるようになりました。特に人の顔写真を編集するツールが注目されています。本論文では複数の画像の要素を組み合わせた合成画像を生成することで画像編集に関する新たなツールを提案しています。
最近では潜在空間の操作による顔編集が成功を収めていますが、それらはポーズ・表情・性別・年齢などのグローバルな属性を変更することで画像の操作を行っています。本論文で行いたい合成タスクは様々な理由で難しいものとなっています。まず、各部分の視覚的特性は互いに独立していません。髪の毛でいえば、周囲の光や顔や服・背景からの透過光に左右されます。また、顔や肩は髪の毛や影に影響を与えます。このような理由から画像の全体的な整合性を考慮しないと各部分がハイクオリティとなっていても画像の異なる領域がバラバラに見えてしまうというアーチファクトが発生します。そのため本論文では構造テンソル$F$による特徴の空間的な粗い位置の制御と外観コード$S$によるグローバルなスタイル属性の細かい制御を可能とする新しい$FS$潜在空間を提案します。

本論文で提案された手法をFig. 1に示します。元となる画像に、ターゲット画像の髪の毛の形状のみを転写することができます(b)。また、直毛や巻き毛などの違いを転送することもできています(d~g)。
手法

提案手法の流れをFig. 3に示します。大まかな流れは以下のようになります:
- 参照する画像のセグメンテーションが生成されるか、手動で生成する
- セグメンテーションされた各画像$Z_k$から潜在コード$C^{align}_k=(F^{align}_k,S^{align}_k)$を検出される
- 各$k$ごとに$F^{align}_k$の領域$k$をコピーし、結合構造のテンソル$F^{blend}$を形成する
- 外観コード$S^{blend}$が画像として整うように$S^{align}_k$の重みが導出する
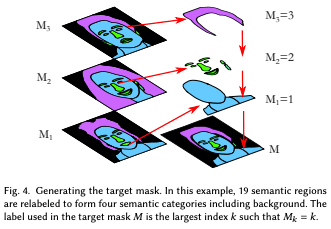
Initial Segmentation
最初のステップでは参照画像のセグメントを行います。これによりターゲット画像へコピーすべき領域を選択します。$M_k=SEGMENT(Z_k)$は参照画像$Z_k$のセグメンテーションを表し$SEGMENT()$はBiSeNETなどのセグメンテーションネットワークであるとします。本ステップでの目的は、ターゲットセグメンテーションマスク$M$と一致する合成画像$Z^{blend}$を形成し、$M=k$となる位置で$Z^{blend}$の視覚特性が元の参照画像$Z_k$から転写されるようにすることとなります。ここで、各ピクセルのターゲットマスク$M(x,y)$は$M_k(x,y)=k$という条件を満たす値$k$が設定されます。複数の$k$が条件を満たす場合はより大きい$k$が選択されます。例えば髪の部分は当然肌に覆われている部分もあります。このとき肌ラベル及び髪ラベルに該当しますが、髪ラベルの方が$k$が大きく設定されているためその箇所は肌ラベルではなく髪ラベルがあてられます。
Embedding
画像を合成する前にまずは各画像をターゲットマスク$M$に合わせます。これは"はじめに"でも述べたように目や鼻などのパーツが互いに独立しておらず、頭部全体のポーズに依存しているため重要なステップとなります。参照画像を揃えるために入力画像$Z_k$を再構成するための潜在コード$C^{rec}_k$を発見する"Reconstruction"及び生成画像とターゲットマスク間のクロスエントロピーを最小化する潜在コード$C^{align}_k$を発見する"Alignment"から成り立っています。
・Reconstruction
入力画像として$Z_k$が与えられたとき、$G(C^{rec}_k)$が$Z_k$を再構成できるような$C^{rec}_k$を発見します($G()$は生成器)。そのための手法として本論文ではStyleGAN2のW+空間を用いて$w^{rec}_k$を導出するII2Sを用いて初期化を行います。しかしW+空間ではシワやほくろなどの顔の詳細を捉えるには十分ではありません。1つのアプローチとしてはノイズ埋め込みがあり、これは再構成の面ではほぼ完璧ではありますが、画像の編集や合成においてアーチファクトとして現れるオーバーフィッティングに繋がります。そのため本論文では新たにFS空間と呼ばれる潜在空間を用いることで上記のノイズ埋め込みの問題を発生させることなくW+空間よりも優れた結果となります。W+空間とFS空間の比較をFig. 5にしめします。

Fig. 5を見るとFS空間ではより詳細な情報が取り込まれていることがわかります。筆者らは生成器のスタイルブロックの出力を空間的相関を持つ構造テンソル$F$として用い、W+空間の対応するブロックを置き換えます。説明の簡単のためにここではスタイルブロック8を用います。初期構造テンソルとして$F^{init}_k=G_8(w^{rec}_k)$を形成し、$w^{rec}_k$の10ブロックを用いて外観コード$S^{init}_k$を初期化します。そして$C^{rec}_k$を導出します:
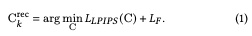
ここで、

・Alignment
各入力画像$Z_k$はテンソル$F^{rec}_k$と外観コード$S^{rec}_k$で構成される$C^{rec}_k$によって符号化されています。$C^{rec}_k$は画像の外観を捉えていますが、より詳細な部分であるターゲットセグメンテーションに合わせられていません。そこで、ターゲットセグメンテーションに合致し、かつ外観を示す$C^{rec}_k$の近くに存在する潜在コード$C^{align}_k$を導出します。 しかし直接$C^{align}_k$を最適化すると、$F^{rec}_k$が空間的に相関を持っているため困難です。そのためまずは$F^{rec}_k$の詳細を$F^{align}_k$へ転送します。
Alignmentされた画像$G(w^{alignment})$と元の画像$Z_k$間のスタイルを保存するためにマスクされたスタイル損失を使用する。
グラムマトリックス
![]()
ここで、$\gamma$はVGGネットワークの層$l$の活性化によって得られる行列です。そしてマスクを定義します:
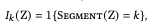
ここで、$1\{\}$は指示関数であるため$I_k$は意味的カテゴリ$k$の領域を示す指標となります。
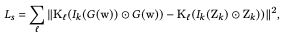
そしてスタイル損失は潜在コード$w$によって生成された画像のグラムマトリックスとターゲット画像$Z_k$との差の大きさで示され、各画像の意味領域$k$内でのみ評価されます:
$I_k(Z_k)\bigodot Z_k$は意味領域$k$以外のピクセルを0とすることでマスキングを行うという式となります。サイクル損失は以下のようになります:
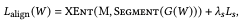
ここで、$XEnt()$は多クラスのクロスエントロピー関数です。
次に画像$Z_k$から構造と外観を$F_k$へ移すための式は
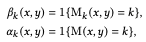
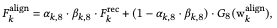
となります。この式は対象画像と参照画像の意味クラスが同じであればそのまま$F^{rec}_k$をコピーしそうでない場合(他の画像から部位を組み合わせる)は$w^{align}_k$を用いて領域を生成するという式となっています。
Structure Blending
画像を組み合わせるために粗い構造を組み合わせます。以下の式のように粗い構造は各構造テンソルを組み合わせるだけで組み合わせることができますが、外観コードに関してはより注意が必要となります。
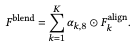
Appearance Blending
本節での目標は組み合わせ画像の外観コード$S^{blend}$を導出することです。そのために先行研究にて用いられたLPIPS distance functionを導入します:
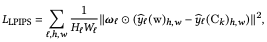
$\hat{y}_l$はconvnet(VGG)の$l$層の活性化であり、$W_l,H_l$はチャネル次元での正規化されたテンソルを指し、$\omega$はチャネルごとの重みです。マスクされている場合は以下のようになります:
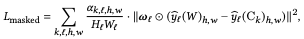
以下の式を満たす$S^{blend}$を導出するために正の重み$u_k$を学習によって求めます(すべての$u_k$を加算すると1となる)。
実験
実験設定
- モデル
- MichiGAN
- LOHO
- Ours
- データセット
- https://arxiv.org/abs/2012.09036
- 120枚の高解像度の画像セット
実験結果
・User Study
AmazonのMechanical Turkを用いてユーザ評価(396人)を行いました。提案手法と既存手法の画像を2つ見せ、どちらがより高画質でアーチファクトが少ないかを聞いた結果、LOHOに対しては95%が、MichiGANに対しては96%の人が提案手法の方が優れていると回答しました。
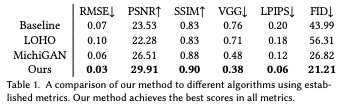
・Reconstruction Quality
様々な指標で画像の品質を評価しましたが、いずれの指標においても提案手法が最も優れています。
・生成画像
提案手法での様々な組み合わせ画像の紹介をします。
髪の組み合わせ(Fig. 6)だけでなく、 目や眉などの顔の特徴を転送する(Fig. 7)ことなどにも成功している。


・limitation
提案手法では、Fig. 10のように顔の一部に細い髪の束がかかっていたり幾何学的歪みは直すことができません。これらの問題はより少ない正則化などが必要な可能性があり今後の研究の課題となります。

まとめ
本論文では新たなGANベースの画像編集フレームワークとしてBarbershopを提案しました。ユーザはセグメンテーションマスクを操作したり、異なる画像からコンテンツをコピーすることで画像を操作することができます。提案手法のキモとしては、まず、一般的に使われているW+空間のみでなく、構造テンソルを組み合わせた新たな潜在空間を提案したことです。構造テンソルにより潜在コードがより空間的に認識されるようになり顔の詳細をよりよく捉えることが可能となりました。次にaligned embeddingによって入力画像に似た画像を埋め込むことができ、新たなセグメンテーションマスクに適合するように画像を修正することも可能となりました。最後に新しい潜在空間でエンコードされた複数の画像を組み合わせて高品質な画像を生成することができました。





この記事に関するカテゴリー






