少数データでGANを学習させるテクニック
3つの要点
✔️ たった10枚でGANのfine-tuningに成功
✔️ フィッシャー情報が重要
✔️ Elastic weight consolidationがGANでも有効
Few-shot Image Generation with Elastic Weight Consolidation
written by Yijun Li, Richard Zhang, Jingwan Lu, Eli Shechtman
(Submitted on 4 Dec 2020)
Comments: Accepted by NeurIPS 2020.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
はじめに
近年多くのGAN学習理論が発表され、「大規模なデータがないとGANは学習できない」と言うのは昔の話になりつつあります。AI-SCHOLARでも少数データでGANを学習する記事が取り上げられています。↓
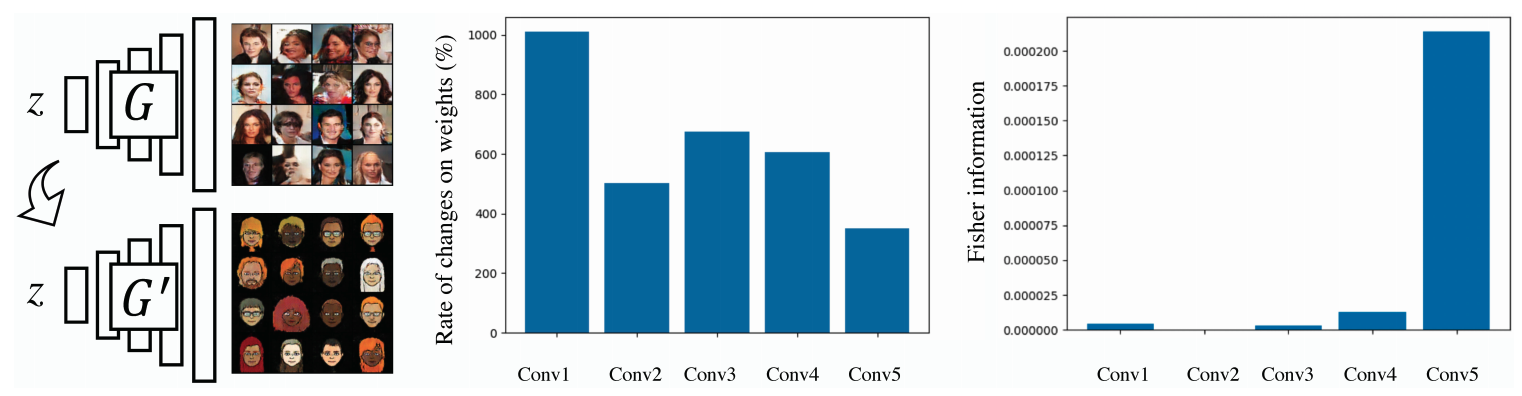
これら2つの記事と今回の記事を読めば、GANで注目されている少数データでの学習系はキャッチアップできると思います。今回ご紹介する論文はたった10枚程度のデータでGANをfine-tuningさせることに成功したと言う論文になります。下図の概要図が今回やりたいことを表しています。

提案手法
少数データでfine-tuningすると言うことは基本的には難しいです。少数データの分布を完全に推論するができると考えるのは普通に考えても不合理です。曲線を1点から推論することが明らかに難しいのと同じ問題です。そうなってくると事前学習しているソースドメインを利用しようと考えるのはごく自然な流れです。しかし、一般的に転移学習をさせてしまうとターゲットドメインでの性能は良いがソースドメインでの性能は劇的に悪くなります(この現象は破滅的忘却 (CatastrophicForgetting) と呼ばれいます)。そのためソースドメインを利用しようと考えても、上手くいかないのです。
そこで今回のメインテクニックはelastic weight consolidation(継続学習)です。継続学習は転移学習に似ていますが、少しだけ枠組みが違います。継続学習についてはすでにAI-SCHOLAR記事で説明されていますので、こちらの記事をご確認ください。→(継続学習を学ぶ。メタ学習による選択的可塑性の実現と破滅的忘却の防止策!)
今回はこのelastic weight consolidationをGANに適用してもうまくいことがわかったという内容です。Elastic weight consolidationの利点を生かすことでGANで難しかった少数データ学習を可能にしたという内容になります。
Elastic weight consolidation
著者らは、ターゲットドメインには、生成モデルを学習するための豊富なデータがあると仮定し、良い重みがどのようなものであるかについて、インスピレーションを得るための実験を行なっています。
大規模ソースデータと大規模ターゲットデータを収集し、5層のDCGANを用いて、重みの変化率を測定しています。その結果が以下の図になります。
ここで重要なことがわかりました!それが最後の層(Conv5)の重みがConv1に比べて変化率が小さいことです。初期層のソースデータ学習した重みはターゲットドメインを学習するために大幅に変化していることから重要ではなく、最終層の方がソースデータにとっても、ターゲットデータにとっても重要な重みを保有していることがわかったのです。単純なfine-tuningではなく、重要な最終層の重みを保持しやすくすることでfine-tuningの成功率を上げれる可能性が出てきたのです。すなわち、異なる層の重みを異なる方法で正則化すべきであることと言うことです。
次の問題はこの各重みの重要性をどのように定量化または測定すれば良いのかと言う問題です。ここまで来れば勘のいいひとは気づくと思います。思い出していただきたいのは数理統計学では、フィッシャー情報Fは観測値が与えられたときにモデルのパラメータをどれだけうまく推定できるかを示すことができるということです。(A Tutorial on Fisher information)
ソースドメインに関する事前学習された生成モデルが与えられた場合、ネットワーク・パラメータ$θ_s$の学習値が与えられたある量のデータ$X$を生成することにより、フィッシャー情報$F$は次のように計算することができます。
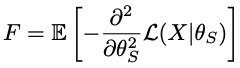
$L(X|θ_s)$は対数尤度関数であり、識別器の出力を用いて二値クロスエントロピー損失を計算することと同じです。
一応簡単に識別器の出力を使用し、実際の顔画像で学習したGモデルの異なる層での重みの平均Fを上図の右側に示しています。明らかに最後の層の重みが、他の層の重みよりもはるかに高い$F$を持っていることがわかります。重みの変化率を考慮すると、$F$を重みの重要度の尺度として直接使用し、さらに正則化損失を追加して、目標領域への適応中の重みの変化にペナルティを課すことができます。
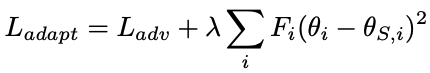

なので事前学習を行なった後で$F$を保存しておき、fine-tuning時に$F$を用いて正則化をかける
定性評価
NSTとBSAとMineGANとの実際の生成結果の比較を見ていきます。FFHQを学習したモデルに10枚のEmojiデータでfine-tuningしていきます。

結果は明らかですね。提案手法以外はまともに生成できていないことがわかります。MineGANも生成ができているように見えますが、明らかに過学習しています。提案手法では、学習データにない画像も生成されているので多様性をソースから引き継ぐことができています。
また実験の結果、ソースドメインとターゲットドメインのギャップが大きくなるほどうまくいかないことがわかりました。

CelebA-FemaleとEmojiはギャップが少ないため、比較的上手くいっていますが、Color pencil landscapeはギャップが大きすぎてまともに生成できていません。
定量評価
10枚画像をfine-tuningした時のFIDとLPIPSとUserの主観的な評価(画像ペアで生成画像を選ばせて、その時のエラー率)も行なっています。

比較すると精度の高さがわかります。さらにUser評価においても大きく他の手法より精度が高いのが特徴的ですね。
まとめ
少数データでのGANのfine-tuningに成功する方法を確立しています。Elastic weight consolidationはGANの学習でも有効に働き、他の手法と比較しても圧倒的な精度でした。また手法もかなりシンプルで、わかりやすいのもよかったです。




この記事に関するカテゴリー





