いつ、なぜ、どの事前学習GANが役立つのか?
3つの要点
✔️ 事前学習済みGANの成功について調査
✔️ 事前学習済みGANのGenerator・Discriminatorの役割を説明
✔️ 最適なソースデータセット選択のための方針の提案
When, Why, and Which Pretrained GANs Are Useful?
written by Timofey Grigoryev, Andrey Voynov, Artem Babenko
(Submitted on 17 Feb 2022 (v1), last revised 10 Mar 2022 (this version, v2))
Comments: ICLR 2022
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
最近の研究では、事前学習されたGANを別のデータセットでfine-tuningすることにより、(特にデータ数が少ない場合において)ゼロからの学習よりも良い結果が得られたことが示されています。
では、いつ・なぜ・どのような事前学習済みGANが、より良好な性能を示すのでしょうか?
本記事では、事前学習GANの利用が生成画像にどのような影響を及ぼすのか、GeneratorとDiscriminatorの初期化がどのような役割を果たすのか、目的のタスクに対してどのような事前学習GANを選択するかなど、上記の疑問について様々な分析を行った研究について紹介します。
GAN fine-tuningの分析
はじめに、GANのfine-tuningが、ゼロからの学習と比べて優れた結果を示す理由について分析します。
GANのfine-tuningが成功する理由の直感的な予想
まず、事前学習済みのGeneratorとDiscriminator$G,D$について、分布$p_{target}$からの新しいデータでfine-tuningを行う場合について考えます。
論文では、事前学習済みの$G,D$は、それぞれ以下の役割を果たしていると予想し、その予想が正しいであろうことを実験により示します。
- Generatorの初期化は、ターゲットデータのモードカバレッジ(modes coverage)を担当(responsible for)している。
- Discriminatorの初期化は、初期勾配場(initial gradient field)を担当(responsible for)している。
この予想に基づくならば、事前学習済みの$G,D$を利用することによる成功の理由は以下のように表現することができます。
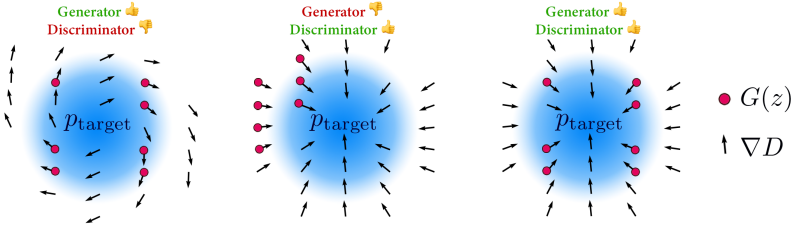
図の左では、適切なGeneratorと不適切なDiscriminatorを利用した場合のイメージが示されています。
この場合、Generatorは多様な初期サンプルを生成していますが、Discriminatorにより与えられる勾配が好ましくないため、学習は良好に機能しないと考えられます。図の中央では、不適切なGeneratorと適切なDiscriminatorを利用した場合のイメージが示されています。
この場合、Discriminatorにより与えられる勾配は良好ですが、Generatorが生成する初期サンプルの分布が適切でないため、最終的に生成されるモード範囲に偏りが生じてしまうと考えられます。そして図の右の通り、GeneratorとDiscriminatorの両方が適切ならば、新しいタスクに適切に移行できると考えられます。
以降では、この予想が妥当であるかを確認するため、合成データでの実験を行います。
合成データによる実験
実験では、以下の図で示される合成データについて考えます。

図の左から1番目は、2つのソースデータ(Source-I、Source-II)と、ターゲットデータ(Target)が示されています。
図の2、3番目は、それぞれSource-I、Source-II上で事前学習されたGeneratorの生成例が示されています。
これら2つの事前学習済みGeneratorと、ゼロからGeneratorをターゲットデータで学習した場合の結果が、それぞれ図の4、5、6番目に示されています(図の数字はターゲット分布と生成データWasserstein-1)。
図の通り、多様なデータを生成する適切な事前学習済みGeneratorを利用することで、ゼロからの場合と比べて良い結果が得られることが示されました。(逆に、生成例に偏りがあるGeneratorの利用は、ゼロからの場合よりも悪い結果に繋がることもわかりました。)
さらに、事前学習済みGeneratorとDiscriminatorの選択が、fine-tuning後の結果にどのような影響を示すかについて調査します。
ここで、事前学習済みGeneratorの品質をRecallによって測定し、事前学習済みDiscriminatorの品質をGround truth勾配とDiscriminator勾配の類似性により測定します。
このとき、異なる事前学習済みGenerator、Discriminatorのペアについて、ターゲットデータ(先程の実験と同じ設定)でfine-tuningを行い、ターゲットデータ分布と生成分布間のWasserstein-1距離を測定します。このような手順により、事前学習済みGeneratorとDiscriminatorの品質と最終的な性能との関係を調査します。結果は以下の通りです。
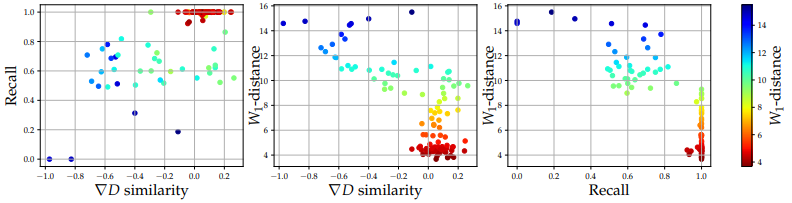
図の左では、選択したGenerator、DiscriminatorのRecallと∇D similarityがプロットされています。
図の中央と右は、それぞれDiscriminatorの品質(∇D similarity)・Generatorの品質(Recall)と、生成結果の品質(W1-distance)の関係が示されています。
結果から分かる通り、GeneratorとDiscriminatorの品質は、fine-tuning後の生成品質と有意な負の相関があることが示されました(ピアソン相関係数はRecallで-0.84、∇D similarityで-0.73)。
この実験により、事前学習済みGenerator、DiscriminatorのRecallと∇D similarityは、fine-tuning後のGANの品質と相関関係があることが示されました。ただし、因果関係が証明されたわけではないことに注意が必要です。
実験設定
StyleGAN2の事前学習
実験では、StyleGAN2アーキテクチャについて調査を行います。
・データセット
事前学習とターゲットに用いるデータセットは以下の通りです。
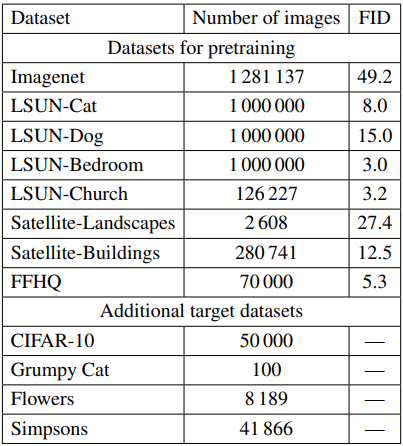
表のうち、Datasets for pretrainingに含まれる8つのデータセットで事前学習を行い、Additional target datasetsでfine-tuningを行います。画像の解像度は256x256で、モデルには公式PyTorch実装のStyleGAN2-ADAを利用します。表のFIDには各データセットで事前学習されたモデルのFIDスコアが示されており、これは小さいほど良好となります。
・事前学習設定
事前学習済みモデルについて、まずImageNetで50Mの画像で学習を行ったモデルを作成し、これを残りのデータセットごとに25Mの画像で学習を行うことで、7つのチェックポイントを作成します。
・対象データセットでの学習設定
ターゲットデータセットでの学習には、StyleGAN2-ADA実装のデフォルトの転送学習設定を利用し、各データセットごとに25Mの画像で学習を行います。
・評価指標
モデルの性能評価に用いる指標は以下の通りです
実験結果
実験の結果は以下の通りです。F、P、R、CはそれぞれFID、Precision、Recall、Convergence rateを示しています。
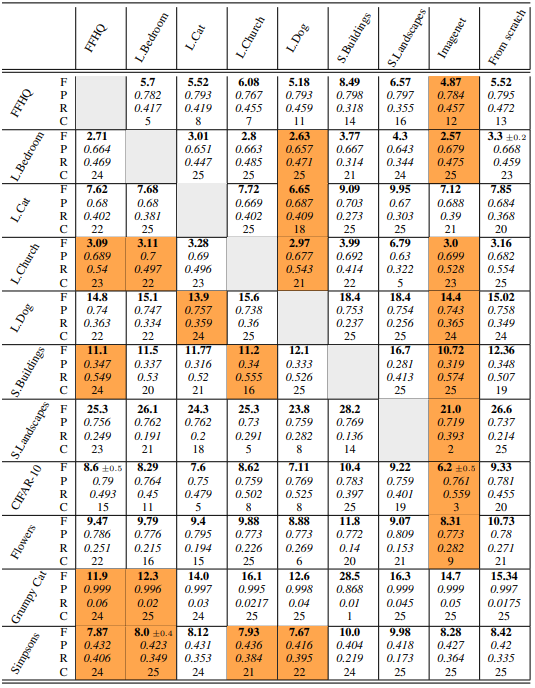
表からは次のようなことがわかります。
- FIDについて、多様なソースデータ(ImageNet、LSUN Dog)で事前学習されたチェックポイントは、全てのデータセットにおいてゼロからの学習(From scratch)より優れていました。
- 事前学習は、ゼロからの学習と比べて最適化を大幅に高速化します。
- ソースチェックポイントの選択は、fine-tuningされたモデルのRecall値に大きく影響します。例えばターゲットがFlowersデータセットの場合、10%を超えるばらつきが生じています。
なお、各ターゲットごとのRecallとPrecisionの標準偏差は以下のようになり、やはりRecallのばらつきが大きいことがわかります。
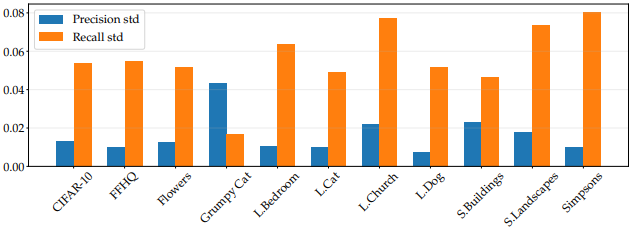
総じて、モデルのFIDスコアは低い(49.2)にも関わらず、ImageNetで事前学習されたモデルは、fine-tuningのためのチェックポイントとして優れていることがわかりました。
この結果は過去の研究に反するものですが、これは使用したモデルが異なる(WGAN-GP)ことによるものだと思われます。
追加実験による分析
・実データのモードカバレッジを向上させる事前学習
論文の予想では、Generatorの初期化はターゲットデータのモードカバレッジに関係しています。ここでは追加実験により、事前学習モデルの選択が、生成画像のモードにどれだけ影響するかを調査します。
具体的には、102個のクラスからなるFlowersデータセットでfine-tuningされたモデルの生成画像について、クラス分類器により各クラス内画像がどれだけ存在するかを調べます。結果は以下の通りです。
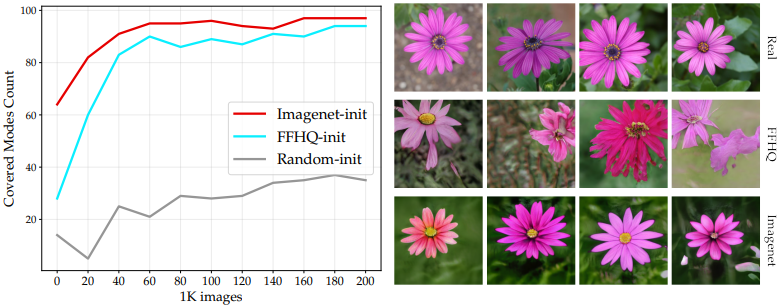
この図では、各チェックポイント(ImageNet、FFHQ、ランダム)について、10,000個の画像を生成し、10個以上のサンプルが含まれているクラス数がプロットされています(横軸はモデルの総学習画像枚数)。
図の通り、多様なソースデータであるImageNetで事前学習されたモデルは、より多様なモードをカバーしていることがわかります。
・適切な事前学習済みチェックポイントを選択する方法
最後に、特定のターゲットデータセットに対して、どのような事前学習済みチェックポイントを選択するべきなのかの簡単な方針について紹介します。
具体的には、ソース・ターゲットデータセットの分布の類似度を測定することにより、最適なモデルを選択することについて考えます。ここで、(1)単純にソース・ターゲットデータセット内の画像を利用する場合、(2)事前学習済みモデルの生成例とターゲットデータセット内の画像を利用する場合の二通りについて、FID、KID、Precision、Recallを測定します。
このとき、各指標の数値により、最適なソースデータセットを特定することができるかどうかを判定した場合の結果は以下の通りです。
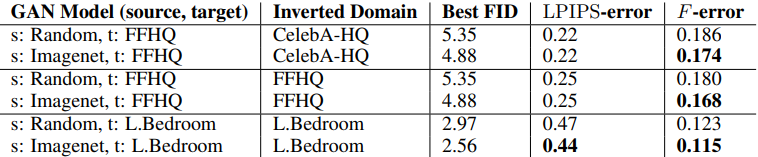
この表では、最適なチェックポイントを予測できなかったデータセットの数が示されており、数値が小さいほど良好な指標であることを示しています。
総じて、Precision以外の指標(特にRecall)を利用することで、(1)、(2)どちらの設定でも最適なソースデータセットを大まかに特定できることがわかりました。
まとめ
本記事では、事前学習済みGANモデルの成功について調査を行った論文について紹介しました。
論文では、適切な事前学習済みGANを利用することで、生成画像のモードのカバレッジを向上させることができること、最適な性能を得るには事前学習済みGeneratorとDiscriminator両方を利用するべきであることなど、様々な知見が示されました。また、ソース・ターゲットデータセット間のRecall値は、適切なソースデータセットの選択の指針となりうることがわかりました。




この記事に関するカテゴリー






