BERTとGANを使った株価予測
3つの要点
✔️ GANを使った株価予測へのアプローチ
✔️ finBERTを使って金融市場の感情分析結果をインプット
✔️ これまでのモデルより優れた結果を出すことに成功
Stock price prediction using BERT and GAN
written by Priyank Sonkiya, Vikas Bajpai, Anukriti Bansal
(Submitted on 18 Jun 2021)
Comments: Published on arxiv.
Subjects: Statistical Finance (q-fin.ST); Computation and Language (cs.CL); Machine Learning (cs.LG) Computing (cs.NE)
code:
本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
研究概要
金融市場の動きを予測するための方法として、株価に関するテクニカル指標(例えば、移動平均)を使ったテクニカル分析が一般的に広まっています。近年は計算機の性能と技術の発展によってニューラルネットを使った株価予測がある程度可能になっています。紹介する論文では、これまでのモデルの性能を上回る、GANアーキテクチャのモデルを提案しています。GANとは本来画像生成のために提唱されましたものですが、提案するモデルでは一次元配列のデータを生成します。学習にはさまざまな市場データ、株価やテクニカル指標などに加え、BERTを用いた金融市場に対する感情分析結果が使われました。GANを使ったモデルが、金融市場予測において優れた結果を出すことはこれ以前の論文で言われていました。今回のモデルは、以前のモデルの性能を上回る結果を出すことに成功しています。
データセット
使用するデータセットについて、大まかな内訳は以下になっています。
- Apple.incの株価データ
- S&P500, NASDAQ100, NYSEなどのアメリカ市場の株価指数
- ロンドン、インド、東京、香港、上海、シカゴ各証券所の株価指数
- 金、原油、米ドルなどのいわゆるコモディティと呼ばれる商品価格データ
- Microsoft、Amazon、Googleなどのビック・テック(Big Tech)と呼ばれる企業の株価
- Seeking Alphaのニュースと見出しをFinBERTを用いた感情分析結果
今回の予測対象はApple.incの銘柄になります。株価データはYahoo Financeからダウンロードしました。使用する期間は2010年7月から2020年7月の10年間です。株価のデータについては、安値、高値、始値、終値、出来高、調整後終値※に加え、テクニカル指標も使われました。
※株式分割の実施の前後で株価を連続的にとらえるために、分割実施前の終値を分割後の値に調整したものを「調整後終値」という。調整後終値-Yahoo! ファイナンス
使われたテクニカル指標は以下の通りです。
- 7、21日の単純移動平均
- 指定日数分の終値の平均価格をつなげた折れ線
- ボリンジャーバンド
- 受験のときの偏差値のイメージ
- MACD(移動平均収束拡散)
- 短期移動平均線から中期移動平均線を引いたもの
- RSI(相対力指数)
- 買われすぎか売られすぎかを判断するための指標
- 終値のフーリエ変換
- 関数を三角関数成分に分解する。今回は終値を3,6,9ずつ使った計算が行われた。
それぞれの指標の理論についての詳しい説明は、論文解説の域を超えるので省略しますが、それぞれの指標をプロットしてみたグラフは以下の図になります。
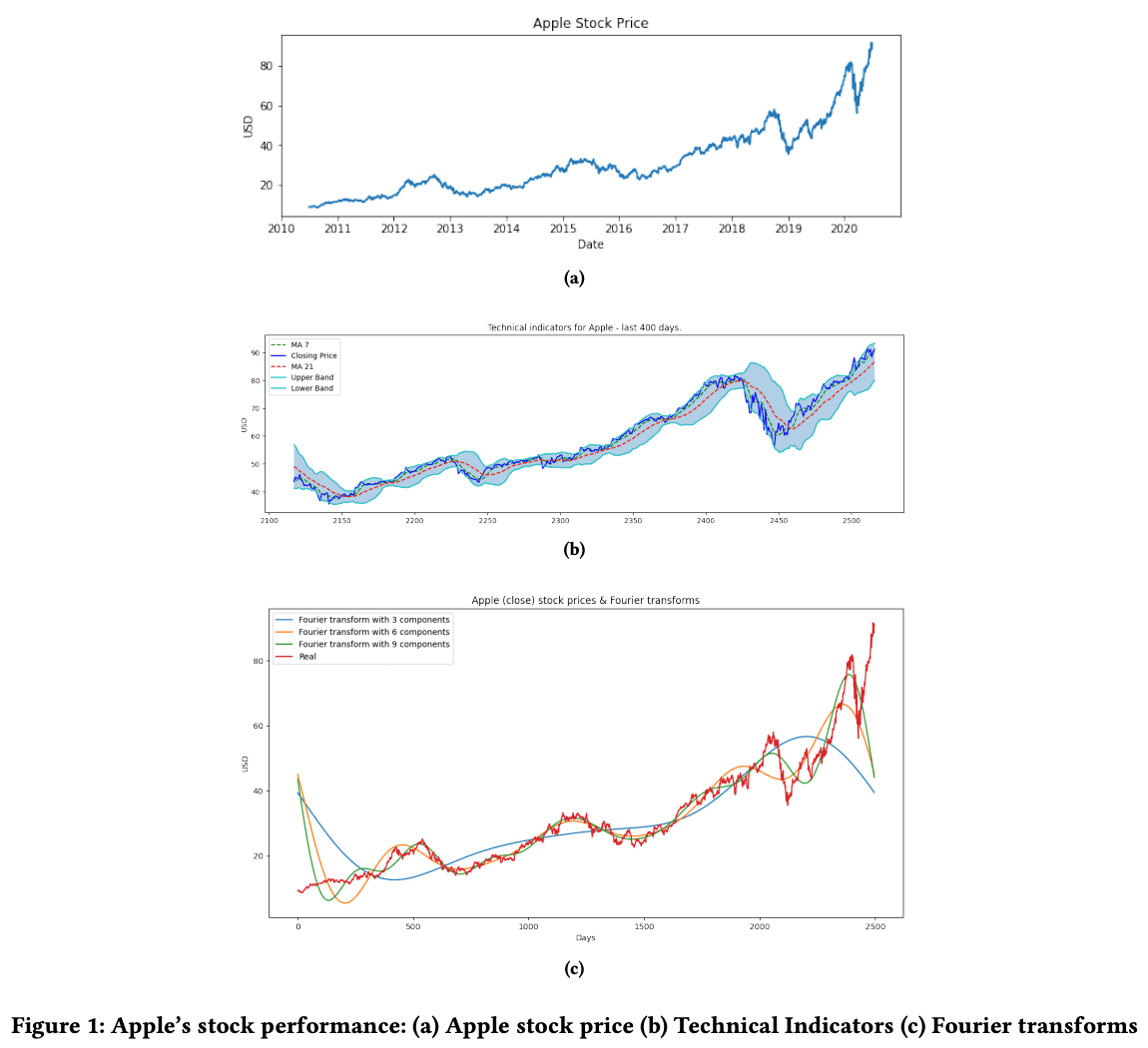
FinBERT
金融市場の感情分析について。まずFinBERTとはなにかというと、FinBERTはBERTを金融関係のデータを使ってファインチューニングし、金融関係の感情分析タスクに対応したものです。学習データにはTRC2-Financial データと Financial PhraseBank データの2つが使われています。
FinBERTのさらに詳しい説明は以下の論文を読んでいただけると幸いです。
FinBERT: Financial Sentiment Analysis with Pre-trained Language Models
written by Dogu Araci
(Submitted on 27 Aug 2019)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:
FinBERTを使った感情分析には、Seeking Alphaのウェブサイトから2010年7月から2020年7月のニュースと見出しがスクレイピングされFinBERTに入力されました。Seeking Alphaとは2004年から存在する金融関係の情報発信を行うウェブメディアです。さまざまな投資家やライターが質の高い情報を発信しています。
画像:https://seekingalpha.com/ (2021/09/30 12:50 時点)
そうしてFinBERTから出力された感情分析結果はデータセットに追加され、また後述するGANの生成器にも渡されます。
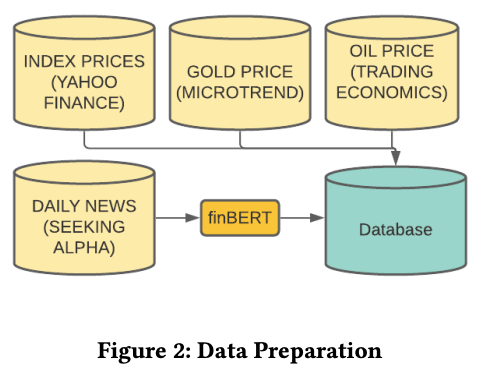
今回の予測を行うにあたり、ルックバックデータのステップは3日間のみで実施しました。前の3日間のデータで、次の4日目の価格を予測する形になります。データセットのサイズは(2517、37)で2517は日数を、37はカラム数です。期間は10年ですが、休日は市場で取引が行われないため、このような日数になっています。トレーニングとテスト用にデータセットを7:3で分割し、最終的なデータサイズはそれぞれ、トレーニングがおよそ2010年から2017年にあたる(1746、3、37)、テストがおよそ2017年から2020年にあたる(748、3、37)になりました。ここで3はルックバックの時間ステップパラメータを表しています。下の図は、今回使用したデータセットの概要図です。
正規化
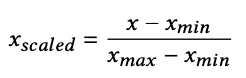
最後に、scikit-learnライブラリのMinMax scalerを用いてデータを正規化します。ここで、xscaledは正規化された値、xmaxは最大値、xminは最小値を指します。これはデータの範囲を-1~1の間に収めることで、データの複雑さを軽減するものです。
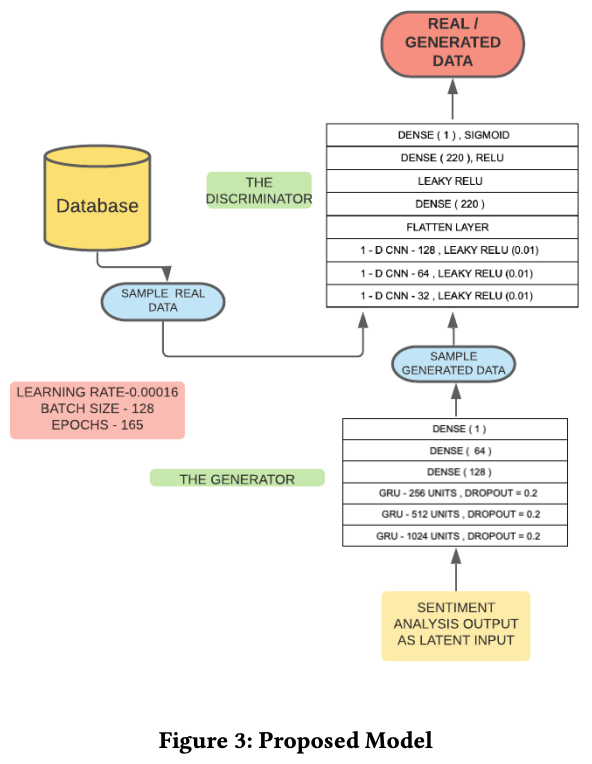
提案モデル
GANの構成としては生成器と識別器の2つを持ちます。生成器はデータを生成し、識別器はそれが生成器から作られたものかどうかを判定します。GANは当初、画像を生成するために提唱されましたが、提案モデルでは価格データの配列を生成するように構築されています。ここではGANの数学的理論と構成の詳細について触れていきます。提案モデルの全体像は以下のようになります。
生成器(GENERATOR)
生成器は以下の式で表されます。
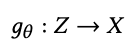
ここで、θは生成器の重みを表します。通常のGANではZはN(0,1)の入力ベクトルを指しますが、提案モデルでは、FinBERTの感情分析の出力に置き換えています。生成器は、生成器の出力gθ(Z)が、実際の価格データの分布Xと同じものだと識別器に推定されるような生成データ分布になるようにθを求めていきます。
生成器の構造
提案モデルでは、生成器にはGRU(Gated Recurrent Units)※が使われています。生成器は、1層、2層、3層でそれぞれ1024個、514個、256個のユニットで構成されています。過学習を防ぐために各層で20%のdropout率が設定されています。さらにそこに、128個、64個、1個のユニットを持つ全結合層がつかされています。生成器の出力は、入力されたデータの翌日の株価になり、識別機に渡されることになります。生成器の図は以下になります。
※GRUは、時系列データなどを分析するのによく使われるLSTM(long-short time memory)モデルを改造したもので、LSTMよりも少ないパラメータで学習ができるため、学習が早く、少ないデータ量でも十分な性能を発揮するという特徴があります。

識別器(DISCRIMINATOR)
識別器は以下の式で表されます。
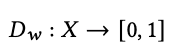
ここでwは識別器の重みを表しています。識別器は実際の価格データには1、生成されたデータに対しては0を出力します。
識別機の構造
識別機には1次元のCNN(Convolutional NeuralNetwork)、活性化関数としてはLeakyRelu(Leaky Rectified Linear Unit)が使われています。LeakyReluは、入力値が0未満なら入力値をα倍した値を返し、0以上なら入力値と同じ値を返します。ここでのαは0.01です。また3層あるCNNでは、カーネルサイズが(3,5,5)とされています。それらに続いて、CNNで畳み込んだデータを1次元に変換するためのflatten層、220個のユニットを持った全結合層、αが0.3に設定されたLeakyRelu層、220個のユニットとReluを活性化関数とした全結合層、生成されたデータかどうかを判定する、シグモイド活性化関数を持った1個の全結合層が接続されました。以下は識別器の図になります。

損失関数
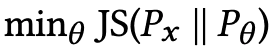
GANの損失関数はKL-JSダイバージェンスに基づいていて、学習ステップではクロス・エントロピーを用いて、2つの分布(実際のデータ分布Pxと生成されたデータ分布Pθ)を区別します。このクロス・エントロピーを最小化することで、KL-JSダイバージェンスを最小化し、実際のデータに類似した分布を得ることができます。
GANモデル
GANモデルを(θ、w)の式で表すと以下のようになります。
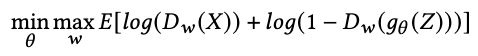
生成器は、生成したデータが実際のデータとして識別器に判定させたいので(Dw(gθ(Z)の部分)、上式を最小化するようにします。逆に識別器は、実際のデータと生成されたデータを正しく分類することが望まれます。よって、上式を最大化して、正しく分類するようにします。上式を微分し、それぞれの重み成分に分解した結果が以下になります。
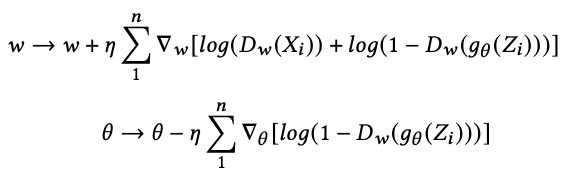
ここで、𝜂は学習率を表します。識別器は実際のデータと生成データの分布間の損失を計算したあと、重みを更新して、実際のデータにより近い生成データを生成するため、生成器に逆伝搬されることで学習します。
実験結果
予測には提案モデルに加え、ARIMA、LSTM、GRU、そしてノイズを入力とするプレーンバニラGAN(提案モデルとパラメータや構成が同じ)が比較のために評価されました。モデルの評価指標として、RMSE(Root Mean Square Error)指標が選ばれました。最後に、5日後、15日後、30日後の株価予測結果をモデルごとで比較しました。ここでは提案モデルはS-GANと命名しています。まずは翌日の株価を予測した結果のグラフになります。
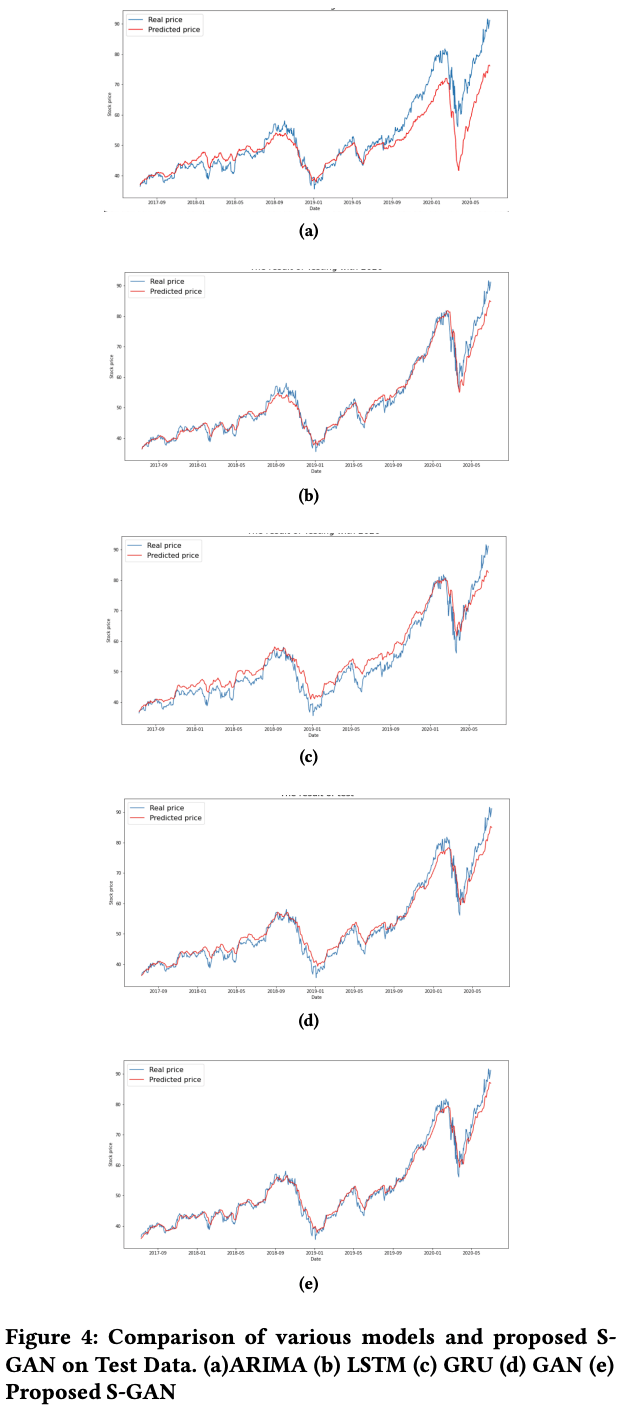
図を見るだけでは、主観的にしか捉えることができませんが、(b)LSTM、(d)GAN、(e)S-GANあたりが良さそうな結果を出していることがわかります。
次にモデルごとのRMSE値の結果です。
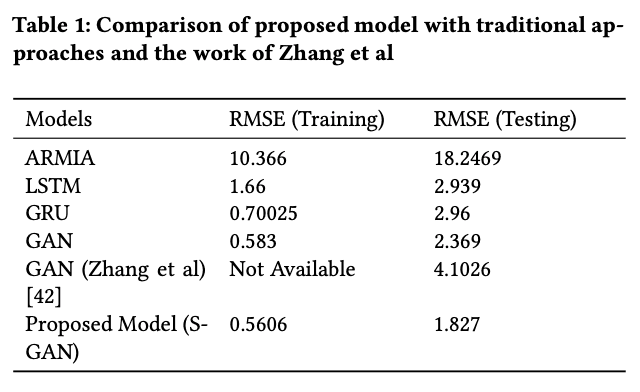
※Zhangらが提案したGANモデルについては以下の論文で述べられています。
Stock Market Prediction Based on Generative Adversarial Network
written by KangZhang, GuoqiangZhong, JunyuDong,ShengkeWang,YongWang.
Comments: Procedia Computer Science; Volume 147, 2019, Pages 400-406
実験では、上のモデルの全体図に示してあったのと同じハイパーパラメータで学習しました.学習率は0.00016、バッチサイズは128、エポック数は165とし、Adamによる最適化を用いて重みを更新しました。提案モデル(ここではS-GAN)2010年から2017年までの学習データを用いて、トレーニングRMSEは0.5606となりました。2017年から最後までのデータで計算されたテストRMSEは1.827でした。トレーニングとテストスコアの両方において、提案モデルが最もよい結果となったことがわかります。
最後に5,15,30日間の予測結果です。上のグラフは各モデルの予測価格と実際の価格の推移で左から順に5日,15日,30日となっています。下の表はモデルのRMSEスコアになります。
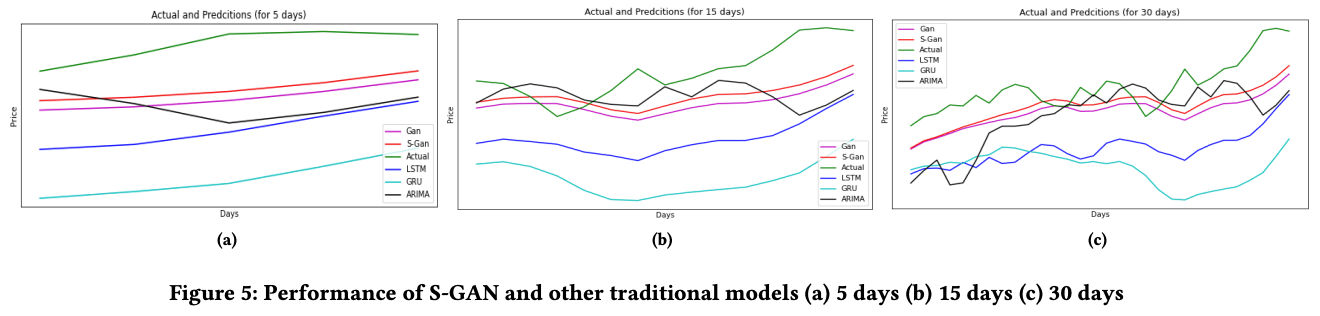

これを見るとGANのモデル同士ほぼ同じ傾きで予測が推移しているのがわかります。プレーンのGANとの違いで確実に言えるのは、論文を読む限りモデルへの入力の部分で、提案モデルへの入力にはFinBERTの感情分析結果を使っていますが、その影響、つまり金融市場の感情分析を使うことについての有効性が示されたといえるでしょう。
まとめ
この論文では、生成器がGRU、識別機がCNNで構成されたGANが、FinBERTを使った金融市場の感情分析結果を使用することで、株価予測タスクにおいて他のモデルよりも優れた結果を出力することがわかりました。言い換えるなら、金融市場でのプレイヤー感情が、市場に影響を与えるということです。課題として、一日の取引が終了したあとに翌日の株価を予測する形となっているため、取引時間中にリアルタイムで予測が行えるようにすることが述べられています。しかし、ある日の取引が終了した時点で、次の日価格をある程度予測できるということは、プレイヤーにとっては十分な情報になり得るでしょう。
感想
私個人の考えとしては、1日や数時間後の株価よりも数日や数週間先の株価を予測することに大きな意義を感じるとともに、その困難さも痛感します。短期間で利益が得られるほど株価が急上昇することはまれですし、かと言って数ヶ月先の株価を予測するには、もっと複雑でさまざまな要因を考える必要が出てくるからです。だからといって、この金融市場を予測することが不可能と決まったわけではありません。ランダムウォーク性を持つ市場に対してパターン認識で挑むというのはナンセンスだというのが個人的意見ですが、今後も、今回のようにGANを時系列タスクに応用するなど、新たなモデルや取り組みが行われるたびに精度は向上していくと考えられます。将来どこまで進むことができるかを思うと、リサーチし続ける価値のある分野の一つだと思います。
宣伝
ICCV 2021 網羅的サーベイ」プロジェクト開催します!内容は「論文サマリ作成」です!
約1ヶ月間に論文を最低でも1本以上読んで頂ける方はぜひこちらのGoogle Formにご登録ください。xpaper.challenge Slackへの招待リンクを送ります。




この記事に関するカテゴリー





